Python插入数据到elasticse
发布时间:2019-07-30 10:28:30编辑:auto阅读(2260)
将一个文件中的内容逐条写入elasticsearch中,效率没有写hadoop高,跟kafka更没得比import time
from elasticsearch import Elasticsearch
from collections import OrderedDict
start_time = time.time()
es = Elasticsearch(['localhost:9200'])
temp_list = []
with open('log.out','r',encoding='utf-8')as f:
data_list = f.readlines()
for data in data_list:
temp = OrderedDict()
temp['ServerIp'] = data.split('|')[0]
temp['SpiderType'] = data.split('|')[1]
temp['Level'] = data.split('|')[2]
temp['Date'] = data.split('|')[3]
temp['Type'] = data.split('|')[4]
temp['OffSet'] = data.split('|')[5]
temp['DockerId'] = data.split('|')[6]
temp['WebSiteId'] = data.split('|')[7]
temp['Url'] = data.split('|')[8]
temp['DateStamp'] = data.split('|')[9]
temp['NaviGationId'] = data.split('|')[10]
temp['ParentWebSiteId'] = data.split('|')[11]
temp['TargetUrlNum'] = data.split('|')[12]
temp['Timeconsume'] = data.split('|')[13]
temp['Success'] = data.split('|')[14]
temp['Msg'] = data.split('|')[15]
temp['Extend1'] = data.split('|')[16]
temp['Extend2'] = data.split('|')[17]
temp['Extend3'] = data.split('|')[18]
# temp_list.append(temp)
body = {'ServerIp': temp['ServerIp'],
'SpiderType': temp['SpiderType'],
'Level': temp['Level'],
'Date': temp['Date'],
'Type': temp['Type'],
'OffSet': temp['OffSet'],
'DockerId': temp['DockerId'],
'WebSiteId': temp['WebSiteId'],
'Url': temp['Url'],
'DateStamp': temp['DateStamp'],
'NaviGationId': temp['NaviGationId'],
'ParentWebSiteId': temp['ParentWebSiteId'],
'TargetUrlNum': temp['TargetUrlNum'],
'Timeconsume': temp['Timeconsume'],
'Success': temp['Success'],
'Msg': temp['Msg'],
'Extend1': temp['Extend1'],
'Extend2': temp['Extend2'],
'Extend3': temp['Extend3'],
}
es.index(index='shangjispider', doc_type='spider', body=body, id=None)
end_time = time.time()
t = end_time - start_time
print(t)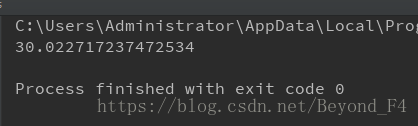
不得不说,这样搞,效率真的不高,插入287条用了30s,根本没法投入生产,在想别的办法
-----------------------------------------------------------------------------------------------------------------
又搞了半天,发现了一个新的方法,效率陡增啊,老铁,有木有!!!!
=》
==》
===》
====》
=====》
======》
-----------------------------------------------擦亮你的双眼---------------------------------------------------------
import time
from elasticsearch import Elasticsearch
from elasticsearch import helpers
start_time = time.time()
es = Elasticsearch()
actions = []
f = open('log.out', 'r', encoding='utf-8')
data_list = f.readlines()
i = 0
for data in data_list:
line = data.split('|')
action = {
"_index": "haizhen",
"_type": "imagetable",
"_id": i,
"_source": {
'ServerIp': line[0],
'SpiderType': line[1],
'Level': line[2],
'Date': line[3],
'Type': line[4],
'OffSet': line[5],
'DockerId': line[6],
'WebSiteId': line[7],
'Url': line[8],
'DateStamp': line[9],
'NaviGationId': line[10],
'ParentWebSiteId': line[11],
'TargetUrlNum': line[12],
'Timeconsume': line[13],
'Success': line[14],
'Msg': line[15],
'Extend1': line[16],
'Extend2': line[17],
'Extend3': line[18],
}
}
i += 1
actions.append(action)
if len(action) == 1000:
helpers.bulk(es, actions)
del actions[0:len(action)]
if i > 0:
helpers.bulk(es, actions)
end_time = time.time()
t = end_time - start_time
print('本次共写入{}条数据,用时{}s'.format(i, t))见证奇迹的时刻
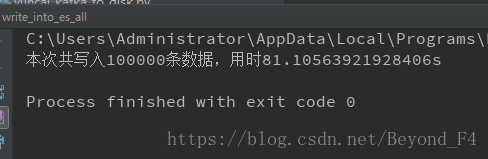
这效率杠杠滴呀,反正是够我用了,先这样吧,需要提升了再想办法吧
老铁,记得给我点赞喏!!!!
上一篇: Python3 Urllib库的基本使用
下一篇: python命名空间
- H3C基本命令大全
53534
- H3C IRF原理及 配置
40359
- Python exit()函数
34758
- python全系列官方中文文档
30521
- python 获取网卡实时流量
25396
- 1.常用turtle功能函数
25185
- python 获取Linux和Windows硬件信息
23599
- 天天基金网数据接口
18882
- Selenium使用代理IP&无头模式访问网站
15180
- Selenium&Pytesseract模拟登录+验证码识别
14692
- LangGraph Studio可视化
1157°
- LangSmith开发-应用入门
1079°
- LangGraph开发-多轮对话问答机器人
1149°
- LangGraph开发-条件分支/循环图实战
1167°
- LangGraph开发-生态介绍,入门demo实战
1203°
- LangChain-接入12306-HTTP MCP智能体
1357°
- LangChain接入自定义爬虫-MCP工具
1316°
- LangChain接入Filesystem-MCP工具
1290°
- LangChain搭建MCP服务端和客户端流程
1389°
- LangGraph与MCP技术概述
1332°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
