字符串的操作补充:
.join() 方法用于将序列(字符串/列表/元组/字典)中的 元素 以指定的字符连接生成一个新的字符串
1 str = "人生苦短我用python!" # 用于字符串 2 s = ".".join(str) 3 s1 = "_".join(str) 4 print(s) # 人.生.苦.短.我.用.p.y.t.h.o.n.! 5 print(s1) # 人_生_苦_短_我_用_p_y_t_h_o 6 7 lis = ["1","2","3","4","5"] # 用于列表 8 print("".join(lis)) # 12345 9 print("*".join(lis)) # 1*2*3*4*5 10 11 dic = {'name':'xiaobai','age':'22','job':'teacher','hobby':'music'} # 用于字典 12 print("_".join(dic)) # name_age_job_hobby 把key链接成字符串
数据类型转换
1 # 数据类型转换: 2 # x--y y(x) int(xxx) str(xxx) 3 # 字符串转换成列表 .split() 列表转换成字符串 .join() 4 # 可表示False的数据类型 False, 0, "", [], tuple(), dict(), set(), None.
关于删除
列表和字典在循环时都不能删除 如:
1 lst = ["王大锤", "王有才", "张小白", "刘大哥"] 2 for i in lst: 3 lst.remove(i) 4 print(lst) # ['王有才', '刘大哥'] # 删除不彻底,原因是每次删除都导致元素移动,每次都会更新索引
若执行循环删除 应把要删除的内容保存在新列表中,循环新列表,删除老列表(字典)
1 lst = ["王大锤", "王有才", "张小白", "刘大哥"] 2 lst1 = [] 3 for i in lst: 4 lst1.append(i) 5 for i in lst1: # 注意第二个for不放在第一个内 6 lst.remove(i) 7 print(lst) # [] 8 9 # 删掉姓王的 10 lst = ["王大锤", "王有才", "张小白", "刘大哥"] 11 lst1 = [] 12 for i in lst: 13 if i.startswith("王"): # 把姓王的装进新列表 14 lst1.append(i) 15 for i in lst1: 16 lst.remove(i) 17 print(lst)
清空字典
1 dic = {"jay":'周杰伦', "jj":"林俊杰 ", "jack": "莱昂纳多迪卡普里奥"} 2 dic.clear() 3 print(dic)
用循环清空
1 # 用循环清空 同上 2 dic1 = {} 3 for k,v in dic.items(): 4 dic1.setdefault(k,v) 5 for k in dic1: 6 dic.pop(k) 7 # 或者把要删除的放到列表 8 lst = [] 9 for i in dic: 10 lst.append(i) 11 for i in lst: 12 dic.pop(i) 13 print(dic)
创建字典 .fromkeys()
1 # 正确用法 2 d = dict.fromkeys("wang","王尼玛") # 注意是使用类名 dict. 创建 "wang"是可迭代的 3 print(d) # {'w': '王尼玛', 'a': '王尼玛', 'n': '王尼玛', 'g': '王尼玛'} 4 d1 = dict.fromkeys(["1","2","3"],[456]) # ["1","2","3"] 可迭代的 5 print(d1) # {'1': [456], '2': [456], '3': [456]}
注意 dict中的元素在 迭代过程中 是不允许进行删除的
如:
1 dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦金金⽼老老板'} 2 for i in dic: # 删掉带k的元素 3 if 'k'in i: 4 del dic[i] 5 print(dic) # dictionary changed size during iteration
fromkeys 是创建一个新字典 并返回给你 不是在原有的字典中 添加 键值对
1 # 坑1 2 dic = {} 3 dic.fromkeys("周杰伦","王尼玛") # fromkeys 静态的 4 print(dic) # {} 打印为空 因为 fromkeys 作用只是创建新字典 必须有新变量来接 5 # fromkeys 作用等同于: dd = dict() ddd = {} 6 d = dic.fromkeys("周杰伦","王尼玛") # 用新变量 7 print(d) # {'周': '王尼玛', '杰': '王尼玛', '伦': '王尼玛'}
value若是可变的数据类型,所有的key都可以改动这个数据,一个改动,所有的value都跟着改
1 # 坑2 2 dic = {} 3 d = dic.fromkeys("王尼玛",[12,34]) 4 print(d) 5 d["王"].append(56) 6 print(d) # {'王': [12, 34, 56], '尼': [12, 34, 56], '玛': [12, 34, 56]} 7 print(id(d["王"]),id(d["尼"]),id(d["玛"])) # 2618348757576 2618348757576 2618348757576 8 # 如上可见 内存地址是一致的 用的是同一个value 若value可改则都会改掉
集合 set:
set集合是python的一个基本数据类型.一般不常用.
与字典对比:
字典:{}
字典的key: 不可变,不能重复, 底层存储是无序的
集合:{}
集合里的元素: 不可变,不能重复. 底层也是无序的。 hash
可以理解成 集合就是字典 集合里面不存在value 只存储key
应用:利用set元素不重复无序 去重复
1 lst = ["周杰伦", "周杰伦", "王力宏", "王力宏", "胡辣汤"] 2 s = set(lst) 3 print(s) # {'胡辣汤', '王力宏', '周杰伦'} 集合 4 lst1 = list(s) 5 print(lst1) # ['胡辣汤', '周杰伦', '王力宏']
集合里面元素是不可以改变的 但本身可以改变 (增删改查)
1 s = {1,2,3,4,[6,7,8]} 2 print(s) # Error unhashable type: 'list' [6,7,8]是可改变的 3 s = {1,2,3,4,5} 4 s.add(7) # 集合本身可变 5 print(s)
frozenset
set集合本身是可改变的 (不可hash的)
但若需要set可hash.可用frozenset来保存数据.frozenset是不可变的.也就是一个可哈希的数据类型
如:
1 s = frozenset([1,2,3,4,5]) 2 print(s) # frozenset({1, 2, 3, 4, 5}) 3 dic = {s:"哇哈哈"} 4 print(dic) # {frozenset({1, 2, 3, 4, 5}): '哇哈哈'}
集合与frozenset 等同于 列表与元组
list -> tuple
set -> frozenset
集合增删改查(不常用):
1 s = {"刘嘉玲", '关之琳', "王祖贤"} 2 3 s.add("林青霞") # 增添 注意重复的不会添加进去 4 print(s) # {'刘嘉玲', '关之琳', '王祖贤', '林青霞'} 5 s.update("张曼玉") # 迭代添加 6 print(s) # {'关之琳', '张', '曼', '玉', '林青霞', '王祖贤', '刘嘉玲'} 7 8 s.pop() # 随机弹出一个 9 print(s) # {'关之琳', '刘嘉玲'} 10 s.remove("刘嘉玲") # 直接删除元素 11 s.remove("麻花腾") # 不存在 删除会报错 12 print(s) # {'关之琳', '王祖贤'} 13 s.clear() # set() 清空 要注意的是set集合如果是空的.打印出来是set() 因为要和 dict区分. 14 print(s) 15 16 17 # set集合中数据没有索引.也没办法定位元素. 所以不能直接修改. 18 # 我们可以采用先删除后添加的方式来完成修改操作 19 s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"} 20 # 把刘嘉玲改成赵本⼭山 21 s.remove("刘嘉玲") 22 s.add("赵本山") 23 print(s) # {'赵本山', '李若彤', '张曼玉', '王祖贤', '关之琳'} 24 25 26 # set是一个可迭代对象. 可进行for循环查询 27 s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"} 28 for i in s: 29 print(i)
深浅拷贝
赋值操作 =
两个变量指向的是同一个内存地址
1 lst1 = ["孙悟空", "贝吉塔", "卡卡罗特"] 2 lst2 = lst1 # 没有创建新的对象 内存地址赋值给lst2 3 print(lst1 is lst2) # True 4 5 lst1.append("七龙珠") 6 print(lst1) 7 print(lst2) # 打印出相同 相同 因为指向的同一个内存地址 8 print(id(lst1),id(lst2)) # 2068950114824 2068950114824
思路参考:
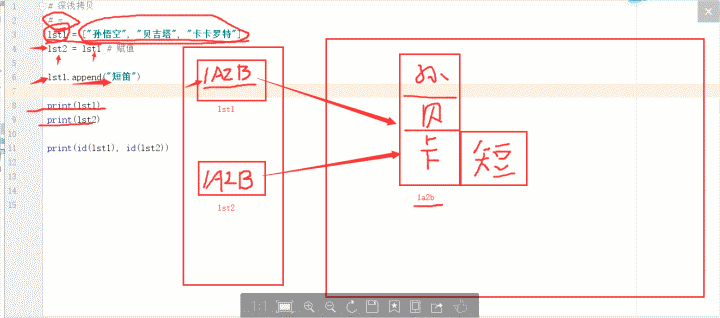
浅拷贝 只拷贝第一层.第二层的内容不会拷贝.所以被称为浅拷贝
优点:节省存储
缺点: 复杂运算容易出现同一个对象被多个变量所引用
1 lst1 = ["孙悟空", "贝吉塔", "卡卡罗特"] 2 # lst2 = lst1[:] # 在原来的数据中获取到所有的数据组成新的列表 等同于 .copy() 3 lst2 = lst1.copy() # 拷贝帮我们创建新对象 不再同一内存地址 4 lst1.append("七龙珠") 5 print(lst1) 6 print(lst2) # lst2是新的对象 原来lst1改变 不影响lst2 7 print(id(lst1),id(lst2))
1 # 坑 2 lst1 = ["孙悟空", "贝吉塔", "卡卡罗特",["七龙珠","火影忍者"]] 3 lst2 = lst1.copy() # 浅拷贝 4 lst1[3].append("路飞") 5 print(lst1) # ['孙悟空', '贝吉塔', '卡卡罗特', ['七龙珠', '火影忍者', '路飞']] 6 print(lst2) # ['孙悟空', '贝吉塔', '卡卡罗特', ['七龙珠', '火影忍者', '路飞']] 7 print(id(lst1),id(lst2)) # 地址不同 2389500584520 2389501071176 8 # 打印出的内容相同,因为 lst1[3] 是固定,浅拷贝出来lst2[3]仍是原地址 9 print(id(lst1[3]),id(lst2[3])) # 3176429412936 3176429412936
深拷贝: 把元素内部的元素完全进行拷贝复制.不会产生一个改变另一个跟着改变的问题
优点:完全拷贝出一份两个对象之间除了数据相同,没有任何关系
缺点:占内存
1 import copy # 引入拷贝模块 2 lst1 = ["孙悟空", "贝吉塔", "卡卡罗特",["七龙珠","战斗陀螺"]] 3 lst2 = copy.deepcopy(lst1) # 会把这个对象相关的内部信息全部复制一份 创建新的列表 4 5 lst1[3].append("巴啦啦小魔仙") 6 print(lst1) # ['孙悟空', '贝吉塔', '卡卡罗特', ['七龙珠', '战斗陀螺', '巴啦啦小魔仙']] 7 print(lst2) # ['孙悟空', '贝吉塔', '卡卡罗特', ['七龙珠', '战斗陀螺']] 8 print(id(lst1), id(lst2)) # 内存地址不同
共同点: 快速创建对象 -> 原型模式(设计模式)
