urllib与urllib2的学习总结(
发布时间:2019-08-25 09:34:29编辑:auto阅读(2221)
urllib2可以接受一个Request对象,并以此可以来设置一个URL的headers,但是urllib只接收一个URL。这意味着,你不能伪装你的用户代理字符串等。
urllib模块可以提供进行urlencode的方法,该方法用于GET查询字符串的生成,urllib2的不具有这样的功能。这就是urllib与urllib2经常在一起使用的原因。
先啰嗦一句,我使用的版本是python2.7,没有使用3.X的原因是我觉得2.7的扩展比较多,且较之前的版本变化不大,使用顺手。3.X简直就是革命性的变化,用的蹩手。3.x的版本urllib与urllib2已经合并为一个urllib库,学着比较清晰些,2.7的版本呢urllib与urllib2各有各的作用,下面我把自己学习官方文档和其他资料的总结写下,方便以后使用。
urllib与urllib2并不是可以代替的,只能说2是一个补充吧。先来看看他们俩的区别,有一篇文章把urllib与urllib2的关系说的很明白《difference between urllib and urllib2》,意思如下。
Python的urllib和urllib2模块都做与请求URL相关的操作,但他们提供不同的功能。他们两个最显着的差异如下:
这两点对于用过urllib与urllib2的人来说比较好理解,但是对于没用过的还是不能有好的理解,下面参考官方的文档,把自己对urllib与urllib2的学习内容总结如下。
A.urllib2概述
urllib2模块定义的函数和类用来获取URL(主要是HTTP的),他提供一些复杂的接口用于处理: 基本认证,重定向,Cookies等。
urllib2支持许多的“URL schemes”(由URL中的“:”之前的字符串确定 - 例如“FTP”的URL方案如“ftp://python.org/”),且他还支持其相关的网络协议(如FTP,HTTP)。我们则重点关注HTTP。
在简单的情况下,我们会使用urllib2模块的最常用的方法urlopen。但只要打开HTTP URL时遇到错误或异常的情况下,就需要一些HTTP传输协议的知识。我们没有必要掌握HTTP RFC2616。这是一个最全面和最权威的技术文档,且不易于阅读。在使用urllib2时会用到HTTP RFC2616相关的知识,了解即可。
B.常用方法和类
1) urllib2.urlopen(url[, data][, timeout])
urlopen方法是urllib2模块最常用也最简单的方法,它打开URL网址,url参数可以是一个字符串url或者是一个Request对象。URL没什么可说的,Request对象和data在request类中说明,定义都是一样的。
对于可选的参数timeout,阻塞操作以秒为单位,如尝试连接(如果没有指定,将使用设置的全局默认timeout值)。实际上这仅适用于HTTP,HTTPS和FTP连接。
先看只包含URL的请求例子:
import urllib2
response = urllib2.urlopen('http://python.org/')
html = response.read()urlopen方法也可通过建立了一个Request对象来明确指明想要获取的url。调用urlopen函数对请求的url返回一个response对象。这个response类似于一个file对象,所以用.read()函数可以操作这个response对象,关于urlopen函数的返回值的使用,我们下面再详细说。
import urllib2
req = urllib2.Request('http://python.org/')
response = urllib2.urlopen(req)
the_page = response.read()这里用到了urllib2.Request类,对于上例,我们只通过了URL实例化了Request类的对象,其实Request类还有其他的参数。
2) class urllib2.Request(url[, data][, headers][, origin_req_host][, unverifiable])
Request类是一个抽象的URL请求。5个参数的说明如下
URL——是一个字符串,其中包含一个有效的URL。
data——是一个字符串,指定额外的数据发送到服务器,如果没有data需要发送可以为“None”。目前使用data的HTTP请求是唯一的。当请求含有data参数时,HTTP的请求为POST,而不是GET。数据应该是缓存在一个标准的application/x-www-form-urlencoded格式中。urllib.urlencode()函数用映射或2元组,返回一个这种格式的字符串。通俗的说就是如果想向一个URL发送数据(通常这些数据是代表一些CGI脚本或者其他的web应用)。对于HTTP来说这动作叫Post。例如在网上填的form(表单)时,浏览器会POST表单的内容,这些数据需要被以标准的格式编码(encode),然后作为一个数据参数传送给Request对象。Encoding是在urlib模块中完成的,而不是在urlib2中完成的。下面是个例子:

import urllibimport urllib2
url = 'http://www.someserver.com/cgi-bin/register.cgi'values = {'name' : 'Michael Foord', 'location' : 'Northampton', 'language' : 'Python' }
data = urllib.urlencode(values)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
the_page = response.read()
headers——是字典类型,头字典可以作为参数在request时直接传入,也可以把每个键和值作为参数调用add_header()方法来添加。作为辨别浏览器身份的User-Agent header是经常被用来恶搞和伪装的,因为一些HTTP服务只允许某些请求来自常见的浏览器而不是脚本,或是针对不同的浏览器返回不同的版本。例如,Mozilla Firefox浏览器被识别为“Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11”。默认情况下,urlib2把自己识别为Python-urllib/x.y(这里的xy是python发行版的主要或次要的版本号,如在Python 2.6中,urllib2的默认用户代理字符串是“Python-urllib/2.6。下面的例子和上面的区别就是在请求时加了一个headers,模仿IE浏览器提交请求。
import urllibimport urllib2
url = 'http://www.someserver.com/cgi-bin/register.cgi'user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'values = {'name' : 'Michael Foord', 'location' : 'Northampton', 'language' : 'Python' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
the_page = response.read()
标准的headers组成是(Content-Length, Content-Type and Host),只有在Request对象调用urlopen()(上面的例子也属于这个情况)或者OpenerDirector.open()时加入。两种情况的例子如下:
使用headers参数构造Request对象,如上例在生成Request对象时已经初始化header,而下例是Request对象调用add_header(key, val)方法附加header(Request对象的方法下面再介绍):
import urllib2
req = urllib2.Request('http://www.example.com/')
req.add_header('Referer', 'http://www.python.org/')
r = urllib2.urlopen(req)OpenerDirector为每一个Request自动加上一个User-Agent header,所以第二种方法如下(urllib2.build_opener会返回一个OpenerDirector对象,关于urllib2.build_opener类下面再说):
import urllib2
opener = urllib2.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
opener.open('http://www.example.com/')最后两个参数仅仅是对正确操作第三方HTTP cookies 感兴趣,很少用到:
origin_req_host——是RFC2965定义的源交互的request-host。默认的取值是cookielib.request_host(self)。这是由用户发起的原始请求的主机名或IP地址。例如,如果请求的是一个HTML文档中的图像,这应该是包含该图像的页面请求的request-host。
unverifiable ——代表请求是否是无法验证的,它也是由RFC2965定义的。默认值为false。一个无法验证的请求是,其用户的URL没有足够的权限来被接受。例如,如果请求的是在HTML文档中的图像,但是用户没有自动抓取图像的权限,unverifiable的值就应该是true。
3) urllib2.install_opener(opener)和urllib2.build_opener([handler, ...])
install_opener和build_opener这两个方法通常都是在一起用,也有时候build_opener单独使用来得到OpenerDirector对象。
install_opener实例化会得到OpenerDirector 对象用来赋予全局变量opener。如果想用这个opener来调用urlopen,那么就必须实例化得到OpenerDirector;这样就可以简单的调用OpenerDirector.open()来代替urlopen()。
build_opener实例化也会得到OpenerDirector对象,其中参数handlers可以被BaseHandler或他的子类实例化。子类中可以通过以下实例化:ProxyHandler (如果检测代理设置用), UnknownHandler, HTTPHandler, HTTPDefaultErrorHandler, HTTPRedirectHandler, FTPHandler, FileHandler, HTTPErrorProcessor。
import urllib2
req = urllib2.Request('http://www.python.org/')
opener=urllib2.build_opener()
urllib2.install_opener(opener)
f = opener.open(req)如上使用 urllib2.install_opener()设置 urllib2 的全局 opener。这样后面的使用会很方便,但不能做更细粒度的控制,比如想在程序中使用两个不同的 Proxy 设置等。比较好的做法是不使用 install_opener 去更改全局的设置,而只是直接调用 opener的open 方法代替全局的 urlopen 方法。
说到这Opener和Handler之间的操作听起来有点晕。整理下思路就清楚了。当获取一个URL时,可以使用一个opener(一个urllib2.OpenerDirector实例对象,可以由build_opener实例化生成)。正常情况下程序一直通过urlopen使用默认的opener(也就是说当你使用urlopen方法时,是在隐式的使用默认的opener对象),但也可以创建自定义的openers(通过操作器handlers创建的opener实例)。所有的重活和麻烦都交给这些handlers来做。每一个handler知道如何以一种特定的协议(http,ftp等等)打开url,或者如何处理打开url发生的HTTP重定向,或者包含的HTTP cookie。创建openers时如果想要安装特别的handlers来实现获取url(如获取一个处理cookie的opener,或者一个不处理重定向的opener)的话,先实例一个OpenerDirector对象,然后多次调用.add_handler(some_handler_instance)来创建一个opener。或者,你可以用build_opener,这是一个很方便的创建opener对象的函数,它只有一个函数调用。build_opener默认会加入许多handlers,它提供了一个快速的方法添加更多东西和使默认的handler失效。
install_opener如上所述也能用于创建一个opener对象,但是这个对象是(全局)默认的opener。这意味着调用urlopen将会用到你刚创建的opener。也就是说上面的代码可以等同于下面这段。这段代码最终还是使用的默认opener。一般情况下我们用build_opener为的是生成自定义opener,没有必要调用install_opener,除非是为了方便。
import urllib2
req = urllib2.Request('http://www.python.org/')
opener=urllib2.build_opener()
urllib2.install_opener(opener)
f = urllib2.urlopen(req)
C.异常处理
当我们调用urllib2.urlopen的时候不会总是这么顺利,就像浏览器打开url时有时也会报错,所以就需要我们有应对异常的处理。
说到异常,我们先来了解返回的response对象的几个常用的方法:
geturl() — 返回检索的URL资源,这个是返回的真正url,通常是用来鉴定是否重定向的,如下面代码4行url如果等于“http://www.python.org/ ”说明没有被重定向。
info() — 返回页面的原信息就像一个字段的对象, 如headers,它以mimetools.Message实例为格式(可以参考HTTP Headers说明)。
getcode() — 返回响应的HTTP状态代码,运行下面代码可以得到code=200,具体各个code代表的意思请参见文后附录。
1 import urllib22 req = urllib2.Request('http://www.python.org/')3 response=urllib2.urlopen(req)4 url=response.geturl()5 info=response.info()6 code=response.getcode() 当不能处理一个response时,urlopen抛出一个URLError(对于python APIs,内建异常如,ValueError, TypeError 等也会被抛出。)
HTTPError是HTTP URL在特别的情况下被抛出的URLError的一个子类。下面就详细说说URLError和HTTPError。
URLError——handlers当运行出现问题时(通常是因为没有网络连接也就是没有路由到指定的服务器,或在指定的服务器不存在),抛出这个异常.它是IOError的子类.这个抛出的异常包括一个‘reason’ 属性,他包含一个错误编码和一个错误文字描述。如下面代码,request请求的是一个无法访问的地址,捕获到异常后我们打印reason对象可以看到错误编码和文字描述。
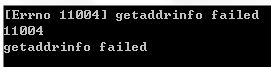
1 import urllib22 req = urllib2.Request('http://www.python11.org/')3 try:4 response=urllib2.urlopen(req)5 except urllib2.URLError,e:6 print e.reason7 print e.reason[0]8 print e.reason[1]
运行结果:
HTTPError——HTTPError是URLError的子类。每个来自服务器HTTP的response都包含“status code”. 有时status code不能处理这个request. 默认的处理程序将处理这些异常的responses。例如,urllib2发现response的URL与你请求的URL不同时也就是发生了重定向时,会自动处理。对于不能处理的请求, urlopen将抛出HTTPError异常. 典型的错误包含‘404’ (没有找到页面), ‘403’ (禁止请求),‘401’ (需要验证)等。它包含2个重要的属性reason和code。
当一个错误被抛出的时候,服务器返回一个HTTP错误代码和一个错误页。你可以使用返回的HTTP错误示例。这意味着它不但具有code和reason属性,而且同时具有read,geturl,和info等方法,如下代码和运行结果。
import urllib2
req = urllib2.Request('http://www.python.org/fish.html')try:
response=urllib2.urlopen(req)except urllib2.HTTPError,e: print e.code print e.reason print e.geturl() print e.read()
运行结果: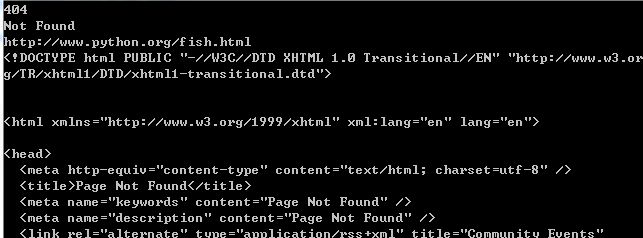
如果我们想同时处理HTTPError和URLError,因为HTTPError是URLError的子类,所以应该把捕获HTTPError放在URLError前面,如不然URLError也会捕获一个HTTPError错误,代码参考如下:
1 import urllib2 2 req = urllib2.Request('http://www.python.org/fish.html') 3 try: 4 response=urllib2.urlopen(req) 5 except urllib2.HTTPError,e: 6 print 'The server couldn\'t fulfill the request.' 7 print 'Error code: ',e.code 8 print 'Error reason: ',e.reason
9 except urllib2.URLError,e:10 print 'We failed to reach a server.'11 print 'Reason: ', e.reason12 else:13 # everything is fine14 response.read()
这样捕获两个异常看着不爽,而且HTTPError还是URLError的子类,我们可以把代码改进如下:
1 import urllib2 2 req = urllib2.Request('http://www.python.org/fish.html') 3 try: 4 response=urllib2.urlopen(req) 5 except urllib2.URLError as e: 6 if hasattr(e, 'reason'): 7 #HTTPError and URLError all have reason attribute. 8 print 'We failed to reach a server.' 9 print 'Reason: ', e.reason10 elif hasattr(e, 'code'):11 #Only HTTPError has code attribute.12 print 'The server couldn\'t fulfill the request.'13 print 'Error code: ', e.code14 else:15 # everything is fine16 response.read()
关于错误编码因为处理程序默认的处理重定向(错误码范围在300内),错误码在100-299范围内的表示请求成功,所以通常会看到的错误代码都是在400-599的范围内。具体错误码的说明看附录。
写到这上面多次提到了重定向,也说了重定向是如何判断的,并且程序对于重定向时默认处理的。如何禁止程序自动重定向呢,我们可以自定义HTTPRedirectHandler 类,代码参考如下:
1 class SmartRedirectHandler(urllib2.HTTPRedirectHandler):2 def http_error_301(self, req, fp, code, msg, headers):3 result = urllib2.HTTPRedirectHandler.http_error_301(self, req, fp, code, msg, headers)4 return result5 6 def http_error_302(self, req, fp, code, msg, headers):7 result = urllib2.HTTPRedirectHandler.http_error_302(self, req, fp, code, msg, headers)8 return result
附录:
1 # Table mapping response codes to messages; entries have the 2 # form {code: (shortmessage, longmessage)}. 3 responses = { 4 100: ('Continue', 'Request received, please continue'), 5 101: ('Switching Protocols', 6 'Switching to new protocol; obey Upgrade header'), 7 8 200: ('OK', 'Request fulfilled, document follows'), 9 201: ('Created', 'Document created, URL follows'),10 202: ('Accepted',11 'Request accepted, processing continues off-line'),12 203: ('Non-Authoritative Information', 'Request fulfilled from cache'),13 204: ('No Content', 'Request fulfilled, nothing follows'),14 205: ('Reset Content', 'Clear input form for further input.'),15 206: ('Partial Content', 'Partial content follows.'),16 17 300: ('Multiple Choices',18 'Object has several resources -- see URI list'),19 301: ('Moved Permanently', 'Object moved permanently -- see URI list'),20 302: ('Found', 'Object moved temporarily -- see URI list'),21 303: ('See Other', 'Object moved -- see Method and URL list'),22 304: ('Not Modified',23 'Document has not changed since given time'),24 305: ('Use Proxy',25 'You must use proxy specified in Location to access this '26 'resource.'),27 307: ('Temporary Redirect',28 'Object moved temporarily -- see URI list'),29 30 400: ('Bad Request',31 'Bad request syntax or unsupported method'),32 401: ('Unauthorized',33 'No permission -- see authorization schemes'),34 402: ('Payment Required',35 'No payment -- see charging schemes'),36 403: ('Forbidden',37 'Request forbidden -- authorization will not help'),38 404: ('Not Found', 'Nothing matches the given URI'),39 405: ('Method Not Allowed',40 'Specified method is invalid for this server.'),41 406: ('Not Acceptable', 'URI not available in preferred format.'),42 407: ('Proxy Authentication Required', 'You must authenticate with '43 'this proxy before proceeding.'),44 408: ('Request Timeout', 'Request timed out; try again later.'),45 409: ('Conflict', 'Request conflict.'),46 410: ('Gone',47 'URI no longer exists and has been permanently removed.'),48 411: ('Length Required', 'Client must specify Content-Length.'),49 412: ('Precondition Failed', 'Precondition in headers is false.'),50 413: ('Request Entity Too Large', 'Entity is too large.'),51 414: ('Request-URI Too Long', 'URI is too long.'),52 415: ('Unsupported Media Type', 'Entity body in unsupported format.'),53 416: ('Requested Range Not Satisfiable',54 'Cannot satisfy request range.'),55 417: ('Expectation Failed',56 'Expect condition could not be satisfied.'),57 58 500: ('Internal Server Error', 'Server got itself in trouble'),59 501: ('Not Implemented',60 'Server does not support this operation'),61 502: ('Bad Gateway', 'Invalid responses from another server/proxy.'),62 503: ('Service Unavailable',63 'The server cannot process the request due to a high load'),64 504: ('Gateway Timeout',65 'The gateway server did not receive a timely response'),66 505: ('HTTP Version Not Supported', 'Cannot fulfill request.'),67 }本文出自https://www.cnblogs.com/wly923/archive/2013/05/07/3057122.html
上一篇: yum命令执行报错(python升级导致
下一篇: python接口自动化-token登录
- H3C基本命令大全
53520
- H3C IRF原理及 配置
40348
- Python exit()函数
34749
- python全系列官方中文文档
30506
- python 获取网卡实时流量
25381
- 1.常用turtle功能函数
25180
- python 获取Linux和Windows硬件信息
23592
- 天天基金网数据接口
18862
- Selenium使用代理IP&无头模式访问网站
15171
- Selenium&Pytesseract模拟登录+验证码识别
14679
- LangGraph Studio可视化
1147°
- LangSmith开发-应用入门
1069°
- LangGraph开发-多轮对话问答机器人
1140°
- LangGraph开发-条件分支/循环图实战
1155°
- LangGraph开发-生态介绍,入门demo实战
1189°
- LangChain-接入12306-HTTP MCP智能体
1347°
- LangChain接入自定义爬虫-MCP工具
1307°
- LangChain接入Filesystem-MCP工具
1280°
- LangChain搭建MCP服务端和客户端流程
1379°
- LangGraph与MCP技术概述
1321°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
