莫名其妙,从去年年底开始,Python这个东西在中国,突然一下子就火起来了,直至现在,他的热度更是超越了java,成为软件工程师最为关注的话题。Python之所以能火起来,很大一方面是因为大数据、人工智能和机器学习越来越受人关注的原因,那么,伴随着Python的火热,他的薪资是否也相应的高了起来了呢?于是,针对这个话题,在今年暑假,我做了一个关于Python、java和大数据和安卓的工作岗位的调查。
Java火了几十年,工作也是所有编程语言中最容易找的,这里面有很大一部分原因是由于安卓还得由Java开发(即使现在出了Kotlin),那么Python和大数据的工作状态又是怎么样的呢?于是在这里,我从51job中爬取了这四个职业的相关情况。
一、项目介绍
主要目标
1、分析python、Java、大数据和Android岗位的薪资如何?
2、分析python、Java、大数据和Android岗位在全国的分布情况
3、python、Java、大数据和Android的前景到底如何?
环境
win7、python2、pycharm
技术
1、数据采集:scrapy、
2、数据存储:csv文件、json文件
3、数据清洗:pandas
4、可视化:matplotlib、百度地图API
二、爬取
在招聘网上分别搜索这四个职业,查看了一下url、页码和需要爬取的数据,求出xpath:
使用scrapy框架进行爬取,代码如下:
items:
import scrapy class Job51Item(scrapy.Item): # 职位名 jobname = scrapy.Field() # 公司名 company = scrapy.Field() # 工作地点 work_place = scrapy.Field() # 薪资 salary = scrapy.Field() # 职位链接 joblink = scrapy.Field()
spiders:
# -*- coding: utf-8 -*- import scrapy from ..items import Job51Item class JobSpider(scrapy.Spider): name = 'job' allowed_domains = ['51job.com'] offset = 1 # ------------ # 控制链 lang = '安卓' # 职位 page = 260 # 页码 # ------------ start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,%s,2,%d.html'%(lang,offset)] def parse(self, response): ajob = response.xpath('//div[@id="resultList"]/div[@class="el"]') for job in ajob: item = Job51Item() item['jobname'] = job.xpath('./p/span/a/@title').extract() item['company'] = job.xpath('./span[1]/a/text()').extract() item['work_place'] = job.xpath('./span[2]/text()').extract() item['salary'] = job.xpath('./span[3]/text()').extract() item['joblink'] = job.xpath('./p/span/a/@href').extract() yield item if self.offset <= self.page: self.offset += 1 yield scrapy.Request(url='https://search.51job.com/list/000000,000000,0000,00,9,99,%s,2,%d.html'%(self.lang,self.offset),callback=self.parse)
修改控制链中的lang和page变量,分别爬取4个职位。
运行scrapy:scrapy crawl job -o android1.csv
数据保存在一个csv文件中,会得到5个csv文件,对应4种职位,其中Android有Android和安卓:

接下来对文件去重合并:
# -*- coding: utf-8 -*- import pandas as pd java_job = pd.read_csv('data/job_java.csv') # print java_job.shape # (100000, 5) python_job = pd.read_csv('data/job_python.csv') # print python_job.shape # (41421, 5) bigdata_job = pd.read_csv('data/job_bigdata.csv') # print bigdata_job.shape # (61191, 5) android1_job = pd.read_csv('data/job_android1.csv') # print android1_job.shape # (31734, 5) android2_job = pd.read_csv('data/job_android2.csv') # print android2_job.shape # (12961, 5) df = pd.concat([java_job,python_job,bigdata_job,android1_job,android2_job]) # df = python_job.append(java_job).append(bigdata_job) # print df.shape # (202612, 10) # 添加Android12之后:(247308, 5) # df.to_csv('data/job.csv',index=False) df.drop_duplicates(inplace=True) print df.shape # (168544, 5) # (192781, 5) df = df.reindex(columns=[u'jobname', u'work_place', u'salary', u'company', u'joblink']) df.to_csv('data/job.csv',index=False)
文件:

部分文件结果截图:

接着跟进链接,爬取职位详细信息,如图:
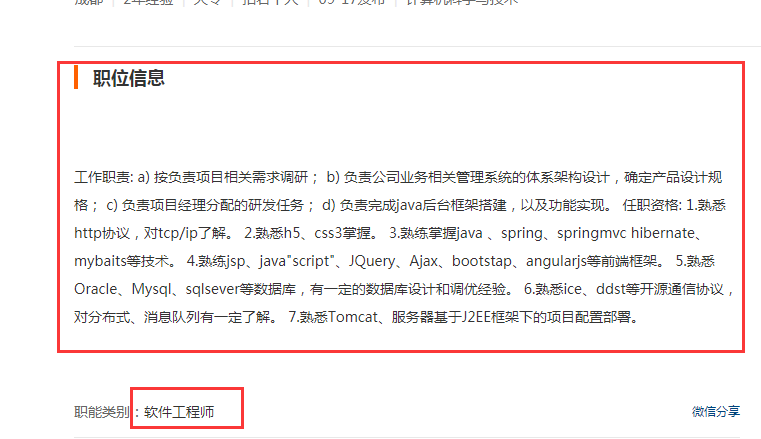
代码如下:
items:
class BaseJobItem(scrapy.Item): # 职位链接 job_link = scrapy.Field() # 职位信息 job_info = scrapy.Field() # 职能类型 job_type = scrapy.Field()
spiders:
# -*- coding: utf-8 -*- import scrapy from ..items import BaseJobItem import pandas as pd def get_link(): df = pd.read_csv('../data/job.csv',encoding='utf-8') return df['joblink'] class JobSpider(scrapy.Spider): name = 'basejob' allowed_domains = ['51job.com'] start_urls = get_link() def parse(self, response): item = BaseJobItem() job_info = response.xpath('//div[@class="bmsg job_msg inbox"]/p/text()').extract() job_type = response.xpath('//div[@class="bmsg job_msg inbox"]/div[@class="mt10"]/p[1]/span[@class="el"]/text()').extract() item['job_link'] = response.url item['job_info'] = job_info item['job_type'] = job_type return item
运行:scrapy crawl basejob -o basejob.csv
数据量有点大,话费了三个小时爬完。
效果如下:

文件有184M:

接下来将两个文件(job.csv和basejob.csv)合并:
# -*- coding: utf-8 -*- import pandas as pd df1 = pd.read_csv('./data/basejob.csv',header=0,encoding='utf-8',names=u'job_info,job_type,joblink'.split(',')) df2 = pd.read_csv('./data/job.csv',encoding='utf-8') # print df1.head() df = pd.merge(df1,df2,on='joblink') print df.sample(5) df = df.reindex(columns=u'jobname,work_place,salary,company,joblink,job_type,job_info'.split(',')) df.to_csv('./data/zhaoping.csv',index=False,encoding='utf-8') # ,index_label=u'jobname,work_place,salary,company,joblink,job_type,job_info'.split(',')
得到最终文件zhaoping.csv:

三、分析
这四种职业的薪资如何呢?针对这个问题,我将这些数据进行清洗,然后分析再使之可视化。
因为只需要分析薪资,所以知道职位和薪资的字段就行了,这里使用job.csv文件进行分析。
首先读取数据并清洗:
import pandas as pd df = pd.read_csv('data/job.csv', encoding='utf-8') df = df[~df['salary'].isna()] df['salary'] = df['salary'].apply(get_salary)
接下来将薪资格式化:
def get_salary(salary): """ 将薪资格式化 :param salary:薪资,如:1-1.5万/月 :return: 10K """ time = salary.split('/')[1] if salary.__contains__('-'): money = salary.split('/')[0][-1] salary_num = salary.split('-')[0] else: salary_num = re.search('\d+',salary.split('/')[0]).group() money = salary.split('/')[0].strip(salary_num) try: salary_num = float(salary_num) except: print salary,'=',money,salary_num if time == u'年': salary_num = salary_num/12 elif time == u'天': salary_num *= 30. elif time == u'小时': salary_num *= 30*12 if money == u'万': salary_num *= 10 elif money == u'元': salary_num /= 1000 return salary_num
获取不同语言的薪资待遇的对比并画图:
def diff_lang(): """ 获取不同语言的薪资待遇的对比 :return: """ lang = ['python','java',u'大数据',u'安卓','android'] avg_salary = map(get_avg_salary,lang) # 针对Android和安卓做特殊处理 lang = lang[:-1] avg_salary = avg_salary[:-2]+[sum(avg_salary[-2:])/len(avg_salary[-2:])] print lang print avg_salary for i,j in zip(lang,avg_salary): print '%s的平均薪资为:%.3fK' % (i.encode('utf-8'),j) p = plt.bar(lang,avg_salary) autolabel(p) plt.xlabel(u'编程语言') plt.ylabel(u'平均薪资') plt.title(u'python、java、大数据和安卓职业薪资待遇对比') plt.show()
还有获取某个编程语言的平均薪资的方法:
def get_avg_salary(lang='',city=''): """ 获取某个编程语言的平均薪资 :param lang: 编程语言名 :return: 平均薪资 """ jobdf = df[df['jobname'].str.contains(lang)] if city != '': jobdf = jobdf[jobdf['work_place'].str.contains(city)] if jobdf.shape[0] < 10: return sum_salary = jobdf['salary'] return sum_salary.astype(float).mean()
还有画图时显示柱状图上的数值的方法:
def autolabel(rects): """ 定义函数来显示柱状上的数值 :param rects:matplotlib.container.BarContainer :return: """ for rect in rects: height = rect.get_height() plt.text(rect.get_x(), 1.01*height, '%.1f' % float(height))
为了显示中文字还要声明一下字体:
plt.rcParams['font.sans-serif'] = ['kaiti']
运行diff_lang()函数:
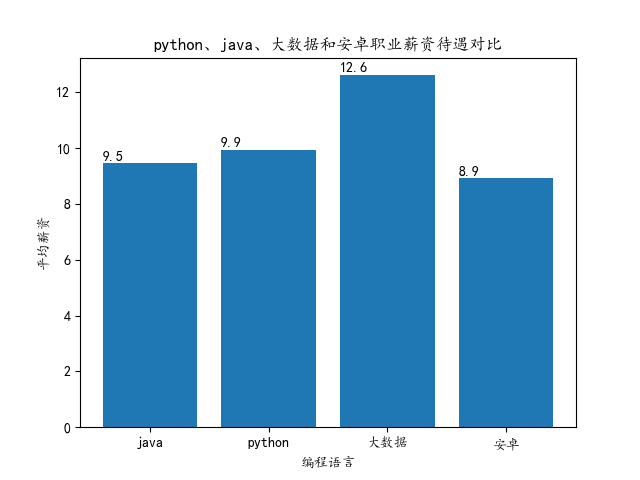
从图中可以看出,大数据的薪资是最高的,达到了1W以上,而Python和Java位居二三,却远远没有大数据的薪资高,而安卓在这几个职位中薪资是最低的。
然后对同一语言不通地区薪资的待遇进行分析对比:
def diff_place(): """ 获取同一语言不通地区薪资的待遇 :return: """ citys = list(df['work_place'].str.split('-').map(lambda x:x[0]).drop_duplicates()) citys.remove(u'朝阳') # 朝阳有点特殊,有些城市直接就是朝阳,不过数量太少,直接忽略了,所以这里做朝阳的特殊处理 lang = ['python', 'java', u'大数据',u'安卓','android'] # ls如:['python','北京'] ls = [[a,b] for a in lang for b in citys] # x是某种语言在某个城市的平均薪资 x = [get_avg_salary(*l) for l in ls] info = {} for i,j in zip(ls,x): # if j != None: # print i[0],i[1],j if not info.has_key(i[0]): info[i[0]] = {} info[i[0]]['city'] = [] info[i[0]]['avg_salary'] = [] if j != None: info[i[0]]['city'] += [i[1]] info[i[0]]['avg_salary'] += [j] # info的可能取值如:info = {"python": {"city": ["上海", "成都",...],"avg_salary": [11.974358974358974, 7.016129032258065, ...]},...} # 特殊处理:对安卓和Android的数据进行合并 info = get_android(info) with open('./data/inf.json','w') as inf: json.dump(info,inf) plt.figure(1,(12,6)) plt.title(u'python、java、大数据和安卓职业各城市薪资待遇对比(单位:K)') for l in lang[:-1]: plt.subplot(len(lang[:-1]),1,lang.index(l) + 1) so = zip(info[l]['city'],info[l]['avg_salary']) so.sort(key=lambda x:x[1],reverse=True) p = plt.bar(range(len(info[l]['city'])),map(lambda x:x[1],so),label=l) plt.xticks(range(len(info[l]['city'])),map(lambda x:x[0],so),rotation=45) autolabel(p) plt.tight_layout() plt.legend() plt.show()
对安卓和Android的数据进行合并:
def get_android(info): """ 对安卓和Android的数据进行合并 :param info: = {"python": {"city": ["上海", "成都",...],"avg_salary": [11.974358974358974, 7.016129032258065, ...]},...} :return: info """ citys = set(info['android']['city']+info[u'安卓']['city']) for city in citys: i,j = 0, 0 if city in info['android']['city']: i = info['android']['avg_salary'][info['android']['city'].index(city)] if city in info[u'安卓']['city']: j = info[u'安卓']['avg_salary'][info[u'安卓']['city'].index(city)] else: info[u'安卓']['city'].append(city) info[u'安卓']['avg_salary'].append(i) info[u'安卓']['avg_salary'][info[u'安卓']['city'].index(city)] = (i+j)/2 del info['android'] return info
最后得到同一语言不同地区薪资的待遇结果图如下:
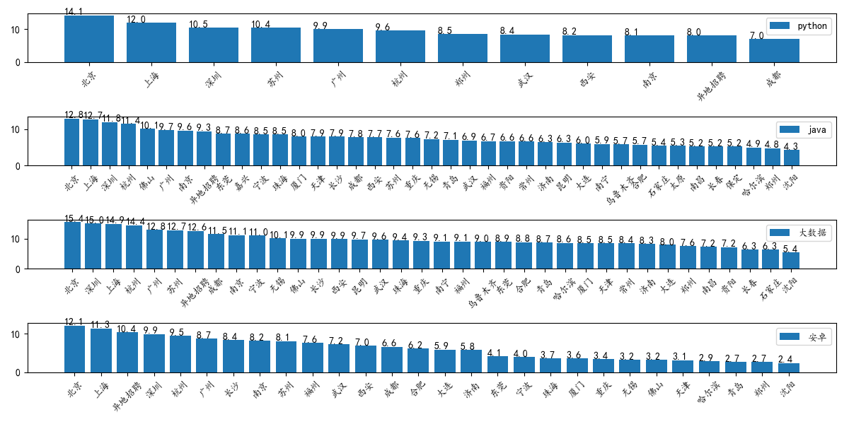
可以以热力图显示数据,这里使用百度的api:
# -*- coding: utf-8 -*- import json from urllib import urlopen, quote import sys reload(sys) sys.setdefaultencoding('utf-8') def getlnglat(address): url = 'http://api.map.baidu.com/geocoder/v2/' output = 'json' ak = 'FOtHtZ92dCKMjpx0XA05g8VEZn95QWOK' add = quote(address.encode('utf-8')) #由于本文城市变量为中文,为防止乱码,先用quote进行编码 uri = url + '?' + 'address=' + add + '&output=' + output + '&ak=' + ak print uri req = urlopen(uri) res = req.read() #将其他编码的字符串解码成unicode temp = json.loads(res) #对json数据进行解析 return temp file = open(r'./data/city.json','w') #建立json数据文件 with open(r'./data/test.json', 'r') as f: js = json.load(f) data = [] for k,v in js.iteritems(): c = {} c['city'] = k c['points'] = [] for i in range(len(v['city'])): if v['city'][i] == u'异地招聘': continue lnglat = getlnglat(v['city'][i]) # 采用构造的函数来获取经度 test = {} test['lng'] = lnglat['result']['location']['lng'] test['lat'] = lnglat['result']['location']['lat'] test['count'] = v['avg_salary'][i] c['points'].append(test) data.append(c) json.dump(data,file,ensure_ascii=False)
那么Python在不同地区薪资的待遇热力图如下,其中,越往中间颜色越深薪资越高:
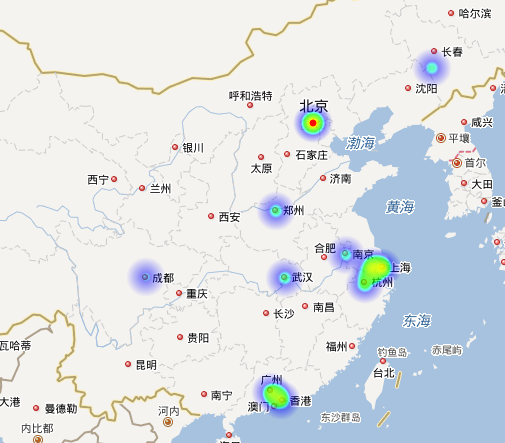
从上如看出Python 的主要工作地区集中在长江三角洲、珠江三角洲一带,而北京的薪资是最高的还有几个内地城市占比也不低。
那么看一下Java在不同地区薪资的待遇热力图:
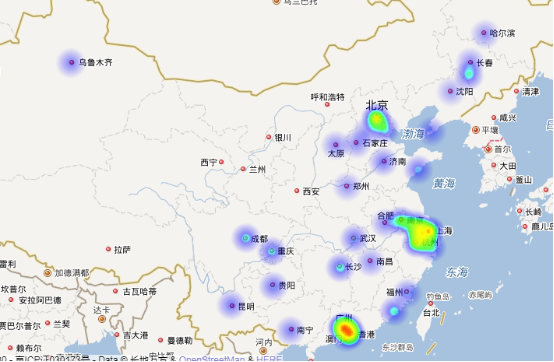
从图可以看出,Java工作地点同样是集中于那三带地区,不过相比于Python,他的主要工作地点更多,且最高薪资大多集中在珠江三角洲。
再看一下大数据在不同地区薪资的待遇热力图:
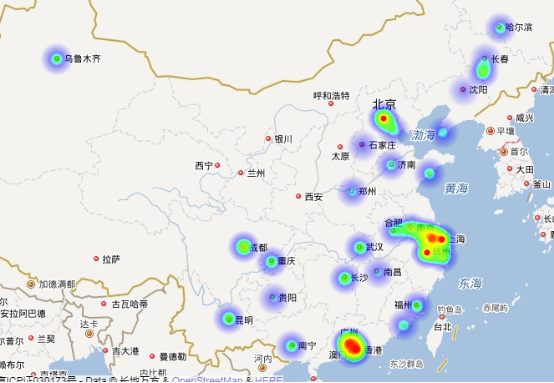
目测大数据和Java分布差别不大,不过从图中红色区域分布可以看出,大数据的薪资更高。
最后看一下安卓在不同地区薪资的待遇热力图:
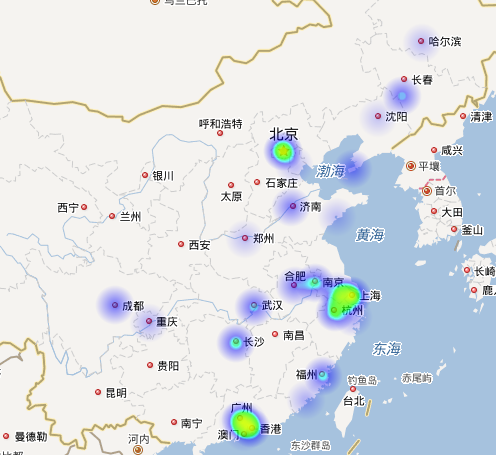
安卓的工作分布低于其他的几种(比Python略高点),而且薪资也也不如其他的几门语言。
从上述四个热力图分析不难看出:
1、大数据无论是工作地点还是薪资均高于其他三种职业;
2、Python火则火矣,薪资也不低,但工作地点还是太少;
3、Java仍旧是宝刀未老,其工作地点和薪资也仅次于大数据行业;
4、安卓终究过时了,薪资比不上其他三个职业,也就工作地点要比Python多点;
由此观之,大数据的发展空间是最大的,前途也是最好的,Java仍然是不二的选择,Android已过时,Python还待发展。
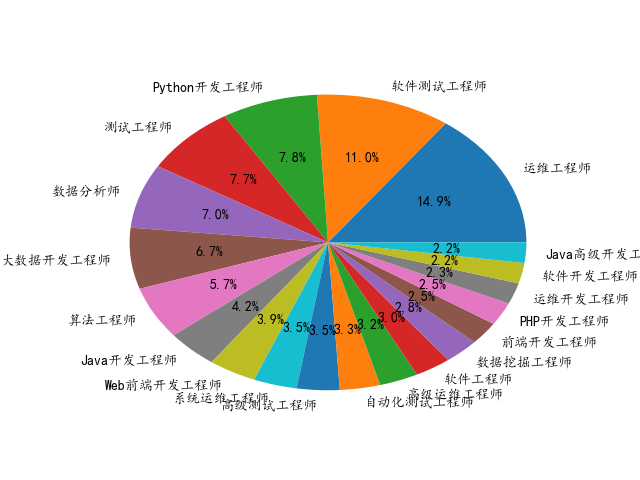
再看一下4种职位的岗位分析图
先看Python岗位的代码:
# -*- coding: utf-8 -*- import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['kaiti'] df = pd.read_csv('./data/job_python.csv',encoding='utf-8') s = df['jobname'].value_counts() job = s[s>150] plt.pie(x =job.values,labels=job.index,autopct='%2.1f%%') plt.show()
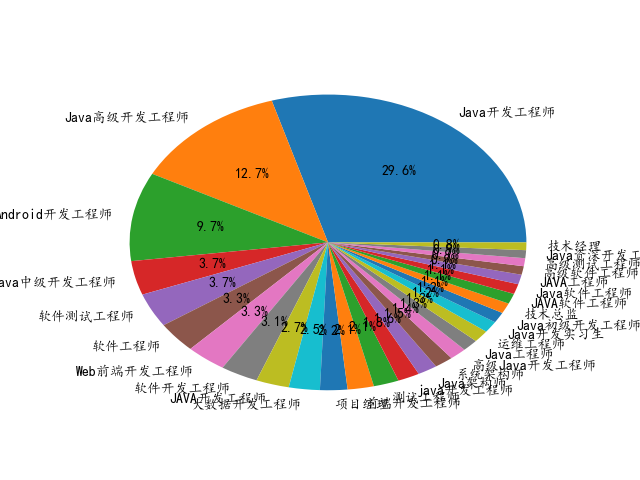
其他的同理,最后得到饼图:
Python:
Java:
大数据:

安卓:

最后来看一下Python语言的职能类型词云,代码:
# -*- coding: utf-8 -*- import pandas as pd df1 = pd.read_csv('./data/job_python.csv',encoding='utf-8') df2 = pd.read_csv('./data/zhaoping.csv', encoding='utf-8') df = pd.merge(df1,df2,on=list(df1.columns)) df = df[~df['job_info'].isna()] dfpy = df[df['job_info'].str.contains('python')] s = dfpy['job_type'].str.split(',').sum() # print pd.Series(s).value_counts() print s # 绘制词云图: from wordcloud import WordCloud import matplotlib.pylab as plt wl = " ".join(s) generate = WordCloud( # 'C:/Users/Windows/fonts/msyh.ttf' font_path = 'C:/Users/Windows/fonts/msyh.ttf', background_color='white', max_words=30, prefer_horizontal = 0.8, random_state=88 ).generate(wl) plt.figure(figsize=(8,5)) plt.imshow(generate) plt.axis("off") # plt.savefig(u'../day5-2/黑卡词云图.png') plt.show()
其他职业的也大致如此.
Python:

Java:

大数据:

安卓:

