4.1 字符串
字符串str是在Python编写程序过程中,最常见的一种基本数据类型。字符串是许多单个子串组成的序列,其主要是用来表示文本。字符串是不可变数据类型,也就是说你要改变原字符串内的元素,只能是新建另一个字符串。
1、创建python字符串
1)单引号' ' 双引号" "创建字符串
要创建字符串,首先可以把字符串元素放在单引号、双引号中,如下图所示:


>>> str1='hello world' >>> str1 'hello world' >>> type(str1) <class 'str'> >>> str2="hello world" >>> type(str2) <class 'str'>
2)python字符串str( )方法
可以把str()作为一种方法来创建一个新的字符串,如下图所示:
>>> a=123 >>> b=str(a) >>> type(b) <class 'str'>
字符串str( )方法,就是把一个原本不是字符串类型的数据,变成字符串类型。
2、查找python字符串的值(子串\字符)
1)什么是字符串的索引(下标)
生活中的下标
超市储物柜

高铁二等座

绿皮车


字符串是许多单个子串组成的序列,序列中的子串按照从左到右的顺序,分别对应一个下标,下标值从0开始。
还有一种下标是反向取值,从右向左取值时会用到。这种下标从最右位开始向左计数,下标值从-1开始!如图所示:
2)python字符串的索引(下标)取值的操作方法
切片:x[开始,结束,步长]
>>> x = 'abcdefj' >>> x[2] 'c' >>> x[2:] 'cdefj' >>> x[2:5] 'cde' >>> x[-1:-4:-1] 'jfe' >>> x[::-1] 'jfedcba'
3、修改和删除python字符串
字符串和数字一样都是不可变数据类型,不能进行修改操作。要想修改或是删除原有字符串数据,最好的方法是重新创建一个字符串。
4、Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
|
转义字符 |
描述 |
|
\(在行尾时) |
续行符 |
|
\\ |
反斜杠符号 |
|
\' |
单引号 |
|
\" |
双引号 |
|
\a |
响铃 |
|
\b |
退格(Backspace) |
|
\e |
转义 |
|
\000 |
空 |
|
\n |
换行 |
|
\v |
纵向制表符 |
|
\t |
横向制表符 |
|
\r |
回车 |
|
\f |
换页 |
|
\oyy |
八进制数yy代表的字符,例如:\o12代表换行 |
|
\xyy |
十进制数yy代表的字符,例如:\x0a代表换行 |
|
\other |
其它的字符以普通格式输出 |
>>> print('xi\'an')
xi'an
5、Python字符串运算符
下表实例变量a值为字符串"Hello",b变量值为"Python":
|
操作符 |
描述 |
实例 |
|
+ |
字符串连接 |
a + b 输出结果: HelloPython |
|
* |
重复输出字符串 |
a*2 输出结果:HelloHello |
|
[] |
通过索引获取字符串中字符 |
a[1] 输出结果 e |
|
[ : ] |
截取字符串中的一部分 |
a[1:4] 输出结果 ell |
|
in |
成员运算符 - 如果字符串中包含给定的字符返回 True |
H in a 输出结果 1 |
|
not in |
成员运算符 - 如果字符串中不包含给定的字符返回 True |
M not in a 输出结果 1 |
|
r/R |
原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
print r'\n' prints \n 和 print R'\n' prints \n |
|
% |
格式字符串 |
请看一下章节 |
6、Python字符串格式化
python字符串格式化符号:
|
符 号 |
描述 |
|
%c |
格式化字符及其ASCII码 |
|
%s |
格式化字符串 |
|
%d |
格式化整数 |
|
%u |
格式化无符号整型 |
|
%o |
格式化无符号八进制数 |
|
%x |
格式化无符号十六进制数 |
|
%X |
格式化无符号十六进制数(大写) |
|
%f |
格式化浮点数字,可指定小数点后的精度 |
|
%e |
用科学计数法格式化浮点数 |
|
%E |
作用同%e,用科学计数法格式化浮点数 |
|
%g |
根据值的大小决定使用%f活%e |
|
%G |
作用同%g,根据值的大小决定使用%f活%e |
|
%p |
用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
|
符号 |
功能 |
|
* |
定义宽度或者小数点精度 |
|
- |
用做左对齐 |
|
+ |
在正数前面显示加号( + ) |
|
<sp> |
在正数前面显示空格 |
|
# |
在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
|
0 |
显示的数字前面填充'0'而不是默认的空格 |
|
% |
'%%'输出一个单一的'%' |
|
(var) |
映射变量(字典参数) |
|
m.n. |
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
示例:
小明的成绩从去年的72分提升到了今年的85分,请计算小明成绩提升的百分点,并用字符串格式化显示出'xx.x%',只保留小数点后1位:
[root@localhost 03-day]# vim 3-1.py #!/usr/bin/env python s1 = 72 s2 = 85 r = s2/s1*100 print('%.1f%%'%r) [root@localhost 03-day]# python 3-1.py 118.1%
7、Python字符串常用操作
当前字符串mystr = ‘hello world how are you’
1)find
string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1
>>> mystr = 'hello world how are you' >>> mystr.find("how") 12 >>> mystr.find("how",20,30) -1
2)index
string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常.
>>> mystr.index("how") 12 >>> mystr.index("how",20,30) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
python的字符串内建函数
|
方法 |
描述 |
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定 的 是 'ignore' 或 者'replace' |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find()函数,不过是从右边开始查找. |
|
|
类似于 index(),不过是从右边开始. |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
string.rpartition(str) |
类似于 partition()函数,不过是从右边开始查找. |
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 |
|
|
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
|
|
isdecimal()方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。 |
4.2 列表
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型。
1.创建列表
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
>>> list1 = ['physics','chemistry',1997,2000]
>>> list2 = [1,2,3,4,5]
2.访问列表中的值
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符
>>> print("list1[0]:",list1[0])
list1[0]: physics
>>> print("list2[1:5]:",list2[1:5])
list2[1:5]: [2, 3, 4, 5]
列表应用:显示文件名的后缀 # 需求文档:显示所有文件的后缀 # 1. 先列举一些常用的文件后缀 fileNames = ['01.py','02.txt','03.rar','04.c','05.cpp','06.php','07.java','index.html','finally.doc'] # 2. 思路 # 2.1 先把01.py文件后缀显示出来,如果这个成功,那么使用循环就完成了整个需求 tempName = fileNames[0] -------->"01.py" position = tempName.rfind(".")-------------> 从右边开始出现的第一次的位置,例如1 print(tempName[position:]) # 2.2 把上一步整体放在循环中,即可完成 for tempName in fileNames: position = tempName.rfind(".") print(tempName[position:]) [root@localhost 03-day]# vim 3-2.py #/usr/bin/env python fileNames = ['01.py','02.txt','03.rar','04.c','05.cpp','06.php','07.java','index.html','finally.doc'] for tempName in fileNames: position = tempName.rfind(".") print(tempName[position:] [root@localhost 03-day]# python 3-2.py .py .txt .rar .c .cpp .php .java .html .doc
3.列表的相关操作
1)添加元素(append、extend、insert)
append:在列表末尾添加新的对象
>>> names = ['zhangsan','lisi','wangwu']
>>> names.append('baoqiang')
>>> names
['zhangsan', 'lisi', 'wangwu', 'baoqiang']
list.extend(seq)
在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
>>> a = [1,2]
>>> b = [3,4]
>>> a.extend(b)
>>> a
[1, 2, 3, 4]
list.insert(index, obj)
将对象插入列表
>>> names.insert(1,'marong')
>>> names
['zhangsan', 'marong', 'lisi', 'wangwu', 'baoqiang']
2)修改元素
['zhangsan', 'marong', 'lisi', 'wangwu', 'baoqiang']
>>> names[2]='songzhe'
>>> names
['zhangsan', 'marong', 'songzhe', 'wangwu', 'baoqiang']
3)查找元素
in(存在)、not in(不存在)
>>> names
['zhangsan', 'marong', 'songzhe', 'wangwu', 'baoqiang']
>>> findName = input("请输入你要找的名字:")
请输入你要找的名字:wangwu
>>> if findName in names:
... print("找到了")
... else:
... print("没有找到")
...
找到了
list.index(obj)
从列表中找出某个值第一个匹配项的索引位置
['zhangsan', 'marong', 'songzhe', 'wangwu', 'baoqiang']
>>> names.index("marong")
1
>>> names.index("qianqi")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'qianqi' is not in list
list.count(obj)
统计某个元素在列表中出现的次数
>>> names.count("marong")
1
>>> names.count("qianqi")
0
4)删除元素
del 根据下表删除
>>> names
['zhangsan', 'marong', 'songzhe', 'wangwu', 'baoqiang']
>>> del names[3]
>>> names
['zhangsan', 'marong', 'songzhe', 'baoqiang']
list.pop([index])
移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
>>> names
['zhangsan', 'marong', 'songzhe', 'baoqiang']
>>> names.pop()
'baoqiang'
>>> names
['zhangsan', 'marong', 'songzhe']
list.remove(obj)
移除列表中某个值的第一个匹配项
>>> names
['zhangsan', 'marong', 'songzhe']
>>> names.remove('zhangsan')
>>> names
['marong', 'songzhe']
4.Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
|
Python 表达式 |
结果 |
描述 |
|
len([1, 2, 3]) |
3 |
长度 |
|
[1, 2, 3] + [4, 5, 6] |
[1, 2, 3, 4, 5, 6] |
组合 |
|
['Hi!'] * 4 |
['Hi!', 'Hi!', 'Hi!', 'Hi!'] |
重复 |
|
3 in [1, 2, 3] |
True |
元素是否存在于列表中 |
|
for x in [1, 2, 3]: print x, |
1 2 3 |
迭代 |
>>> [1,2,3]+['a','b','c']
[1, 2, 3, 'a', 'b', 'c']
>>> [1,2,3]*2
[1, 2, 3, 1, 2, 3]
>>> len([1,2,3])
3
5.列表的嵌套
>>> schoolNames = [['北京大学','清华大学'],
... ['中山大学','华南师大'],
... ['西安交大','西安电子科大','长安大学']]
>>> schoolNames
[['北京大学', '清华大学'], ['中山大学', '华南师大'], ['西安交大', '西安电子科大', '长安大学']]
遍历列表
>>> for temp1 in schoolNames:
... for temp2 in temp1:
... print(temp2)
... print("-----------")
...
北京大学
清华大学
-----------
中山大学
华南师大
-----------
西安交大
西安电子科大
长安大学
-----------
列表应用:
一个学校,有3个办公室,现在有8位老师等待工位的分配,请编写程序,完成随机分配
#!/usr/bin/env python
import random
#1. 定义一个列表,用来存储8位老师的名字
tearchers = ['xiaoming','xiaowang','laozhang','xiaoliu','laoli','xiaozhao','jenry','smith']
#2. 定义一个列表,这里有3个办公室,用来等待老师分配
offices = [[],[],[]]
#3.通过循环的方式把8位老师随机分配到3个办公室
#注意:所谓的随机分配,即获取一个随机的办公室号,然后把这个老师添加到里面
for name in tearchers:
index = random.randint(0,2)
offices[index].append(name)
#print(offices)
#4.输出每个办公室里面的老师的信息
[root@localhost 03-day]# python 3-3.py
办公室1
xiaoming
xiaowang
xiaoliu
smith
--------------------
办公室2
--------------------
办公室3
laozhang
laoli
xiaozhao
jenry
--------------------
[root@localhost 03-day]# python 3-3.py
办公室1
xiaoliu
laoli
xiaozhao
smith
--------------------
办公室2
xiaoming
xiaowang
jenry
--------------------
办公室3
laozhang
--------------------
4.3 元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
>>> tup1 = ('physics', 'chemistry', 1997, 2000)
>>> tup2 = (1,2,3,4,5)
>>> tup3 = 'a','b','b','d'
创建空元组
>>> tup4 = ()
>>> tup3[0]='A'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
基本操作
>>> tup1[0]
'physics'
>>> tup2[1:3]
(2, 3)
>>> tup1 + tup2
('physics', 'chemistry', 1997, 2000, 1, 2, 3, 4, 5)
>>> del tup3
>>> tup3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'tup3' is not defined
>>> len(tup2)
5
>>> tuple('123')
('1', '2', '3')
4.4 字典
字典是另一种可变容器模型,且可存储任意类型对象,如其他容器模型。
字典由键和对应值成对组成。字典也被称作关联数组或哈希表。基本语法如下:
>>> dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
每个键与值用冒号隔开(:),每对用逗号,每对用逗号分割,整体放在花括号中({})。
键必须独一无二,但值则不必。
值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
访问字典
>>> newNames = {'name1':'aaaa','name2':'bbbb','name3':'cccc'}
>>> newNames
{'name1': 'aaaa', 'name2': 'bbbb', 'name3': 'cccc'}
>>> newNames['name2']
'bbbb'
修改字典
>>> newNames['name3']='CCCC'
>>> newNames
{'name1': 'aaaa', 'name2': 'bbbb', 'name3': 'CCCC'}
radiansdict.get(key, default=None)
返回指定键的值,如果值不在字典中返回default值
>>> newNames.get('name2')
'bbbb'
>>> newNames.get('name4','dddd')
'dddd'
>>> newNames
{'name1': 'aaaa', 'name2': 'bbbb'}
删除字典
>>> del newNames['name3']
>>> newNames
{'name1': 'aaaa', 'name2': 'bbbb'}
>>>
#删除整个字典
>>> del newNames
>>> newNames
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'newNames' is not defined
#清空字典
>>> dict
{'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
>>> dict.clear()
>>> dict
{}
len 长度
>>> dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
>>> len(dict)
3
>>> len(dict['Beth'])
4
keys 返回key
>>> dict.keys()
dict_keys(['Alice', 'Beth', 'Cecil'])
values 返回value
>>> dict.values()
dict_values(['2341', '9102', '3258'])
items 以列表返回可遍历的(键, 值) 元组数组
>>> dict.items()
dict_items([('Alice', '2341'), ('Beth', '9102'), ('Cecil', '3258')])
遍历字典
>>> dict
{'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
>>> for key,values in dict.items():
... print(key,values)
...
Alice 2341
Beth 9102
Cecil 3258
>>> for key,values in dict.items():
... print("key=%s,values=%s"%(key,values))
...
key=Alice,values=2341
key=Beth,values=9102
key=Cecil,values=3258
遍历字典元素
>>> for item in dict.items():
... print(item)
...
('Alice', '2341')
('Beth', '9102')
('Cecil', '3258')
遍历key
>>> for key in dict.keys():
... print(key)
...
Alice
Beth
Cecil
遍历value
>>> for value in dict.values():
... print(value)
...
2341
9102
3258
遍历
通过for ... in ...:的语法结构,我们可以遍历字符串、列表、元组、字典等数据结构。
注意python语法的缩进
字符串遍历
>>> a_str = "hello itcast"
>>> for char in a_str:
... print(char,end=' ')
...
hello itcast
列表遍历
>>> a_list = [1, 2, 3, 4, 5]
>>> for num in a_list:
... print(num,end=' ')
...
1 2 3 4 5
元组遍历
>>> a_turple = (1, 2, 3, 4, 5)
>>> for num in a_turple:
... print(num,end=" ")
1 2 3 4 5
字典遍历
<1> 遍历字典的key(键)

<2> 遍历字典的value(值)

<3> 遍历字典的项(元素)

<4> 遍历字典的key-value(键值对)

想一想,如何实现带下标索引的遍历
>>> chars = ['a', 'b', 'c', 'd']
>>> i = 0
>>> for chr in chars:
... print("%d %s"%(i, chr))
... i += 1
...
0 a
1 b
2 c
3 d
enumerate()
>>> chars = ['a', 'b', 'c', 'd']
>>> for i, chr in enumerate(chars):
... print i, chr
...
0 a
1 b
2 c
3 d
1)生活中的字典


2)软件开发中的字典
公共方法
运算符
|
运算符 |
Python 表达式 |
结果 |
描述 |
支持的数据类型 |
|
+ |
[1, 2] + [3, 4] |
[1, 2, 3, 4] |
合并 |
字符串、列表、元组 |
|
* |
'Hi!' * 4 |
['Hi!', 'Hi!', 'Hi!', 'Hi!'] |
复制 |
字符串、列表、元组 |
|
in |
3 in (1, 2, 3) |
True |
元素是否存在 |
字符串、列表、元组、字典 |
|
not in |
4 not in (1, 2, 3) |
True |
元素是否不存在 |
字符串、列表、元组、字典 |
>>> "hello " + "itcast"
'hello itcast'
>>> [1, 2] + [3, 4]
[1, 2, 3, 4]
>>> ('a', 'b') + ('c', 'd')
('a', 'b', 'c', 'd')
*
>>> 'ab'*4
'ababab'
>>> [1, 2]*4
[1, 2, 1, 2, 1, 2, 1, 2]
>>> ('a', 'b')*4
('a', 'b', 'a', 'b', 'a', 'b', 'a', 'b')
in
>>> 'itc' in 'hello itcast'
True
>>> 3 in [1, 2]
False
>>> 4 in (1, 2, 3, 4)
True>>> "name" in {"name":"Delron", "age":24}
True
注意,in在对字典操作时,判断的是字典的键
python内置函数
Python包含了以下内置函数
|
序号 |
方法 |
描述 |
|
1 |
cmp(item1, item2) |
比较两个值 |
|
2 |
len(item) |
计算容器中元素个数 |
|
3 |
max(item) |
返回容器中元素最大值 |
|
4 |
min(item) |
返回容器中元素最小值 |
|
5 |
del(item) |
删除变量 |
cmp
>>> cmp("hello", "itcast")
-1
>>> cmp("itcast", "hello")
1
>>> cmp("itcast", "itcast")
0
>>> cmp([1, 2], [3, 4])
-1
>>> cmp([1, 2], [1, 1])
1
>>> cmp([1, 2], [1, 2, 3])
-1
>>> cmp({"a":1}, {"b":1})
-1
>>> cmp({"a":2}, {"a":1})
1
>>> cmp({"a":2}, {"a":2, "b":1})
-1
注意:cmp在比较字典数据时,先比较键,再比较值。
len
>>> len("hello itcast")
12
>>> len([1, 2, 3, 4])
4
>>> len((3,4))
2
>>> len({"a":1, "b":2})
2
注意:len在操作字典数据时,返回的是键值对个数。
max
>>> max("hello itcast")
't'
>>> max([1,4,522,3,4])
522
>>> max({"a":1, "b":2})
'b'
>>> max({"a":10, "b":2})
'b
'>>> max({"c":10, "b":2})
'c'
del
del有两种用法,一种是del加空格,另一种是del()
>>> a = 1
>>> a
1
>>> del a
>>> a
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
>>> a = ['a', 'b']
>>> del a[0]
>>> a
['b']
>>> del(a)
>>> a
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
多维列表/元祖访问的示例
>>> tuple1 = [(2,3),(4,5)]
>>> tuple1[0]
(2, 3)
>>> tuple1[0][0]
2
>>> tuple1[0][2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: tuple index out of range
>>> tuple1[0][1]
3
>>> tuple1[2][2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range>>> tuple2 = tuple1+[(3)]>>> tuple2
[(2, 3), (4, 5), 3]>>> tuple2[2]3>>> tuple2[2][0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not subscriptable
引用
想一想
>>> a = 1
>>> b = a
>>> b
1
>>> a = 2
>>> a
2
请问此时b的值为多少?
>>> a = [1, 2]
>>> b = a
>>> b
[1, 2]
>>> a.append(3)
>>> a
[1, 2, 3]
请问此时b的值又是多少?
引用
在python中,值是靠引用来传递来的。
我们可以用id()来判断两个变量是否为同一个值的引用。 我们可以将id值理解为那块内存的地址标示。
>>> a = 1
>>> b = a
>>> id(a)
13033816
>>> id(b)
# 注意两个变量的id值相同13033816
>>> a = 2>>> id(a)
# 注意a的id值已经变了13033792
>>> id(b)
# b的id值依旧13033816
>>> a = [1, 2]
>>> b = a
>>> id(a)
139935018544808
>>> id(b)
139935018544808
>>> a.append(3)
>>> a
[1, 2, 3]
>>> id(a)
139935018544808
>>> id(b)
# 注意a与b始终指向同一个地址139935018544808
139935018544808
可变类型与不可变类型
可变类型,值可以改变:
-
- 列表 list
- 字典 dict
不可变类型,值不可以改变:
-
- 数值类型 int, long, bool, float
- 字符串 str
- 元组 tuple
怎样交换两个变量的值?
4.4 集合
set (集合)。集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。集合对象还支持 union(联合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等数学运算。
1、创建集合
创建空集合
>>> s=set() >>> s set() >>> s1=set([]) #列表 >>> s1 set() >>> s2=set(()) #元组 >>> s2 set() >>> s3=set({}) #字典 >>> s3 set()
注意:想要创建空集合,你必须使用 set() 而不是 {}。后者用于创建空字典,我们在后面介绍的一种数据结构。
创建非空集合
>>> s1=set([1,2,3,4]) >>> s1 {1, 2, 3, 4} >>> s3=set({'a':2,'b':3,'c':4}) >>> s3 {'c', 'a', 'b'}
注意:字典转set集合,需要注意的是,只取了字典的key,相当于将字典中的dict.keys()列表转成set集合。
2、集合操作
1)集合添加
集合的添加有两种方式,分别是add和update。但是它们在添加元素时是由区别的:
-
- add()方法
把要传入的元素作为一个整体添加到集合中,如:
- add()方法
>>> s=set('one') >>> s {'e', 'o', 'n'} >>> s.add('two') >>> s {'e', 'two', 'o', 'n'}
-
- update()方法
是把要传入的元素拆分成单个字符,存于集合中,并去掉重复的字符。可以一次添加多个值,如:
- update()方法
>>> s=set('one') >>> s {'e', 'o', 'n'} >>> s.update('two') >>> s {'e', 'n', 't', 'w', 'o'}
2)集合删除
集合的删除操作使用的方法跟列表是一样的,使用的也是remove方法。如:
-
-
setVar.remove(element)
setVar :为一个set类型的变量
element :表示要查找并删除的元素
函数作用:
在集合setVar中查找element元素,如果存在则删除;如果没找到,则报错。
-
setVar.remove(element)
>>> s=set('one') >>> s {'e', 'o', 'n'} >>> s.remove('e') >>> s {'n', 'o'}
-
-
setVar.discard(element)
setVar :为一个set类型的变量
element :表示要查找并删除的元素
函数作用:
在集合setVar中查找element元素,如果存在则删除;如果没找到,则什么也不做。
-
setVar.discard(element)
>>> sList set([1, 2, 3, 4, 5]) >>> sList.discard(1) >>> sList set([2, 3, 4, 5])
-
-
s.pop()
s:为set类型的变量
函数作用:
删除并返回set类型的s中的一个不确定的元素,如果为空引发KeyError错误。
-
s.pop()
>>> sList set([2, 3, 4, 5]) >>> sList.pop() 2
-
-
s.clear()
s:set类型的变量
函数作用:
清空s集合中的所有元素
-
s.clear()
>>> sList set([3, 4, 5]) >>> sList.clear() >>> sList set([])
3)集合的遍历
集合的遍历跟序列的遍历方法完全一样。
>>> s=set('one') >>> s {'e', 'o', 'n'} >>> for i in s: print(i) ... ... e o n >>>
另一种遍历方式:
>>> s=set('one') >>> s {'e', 'o', 'n'} >>> for idex,i in enumerate(s): print (idex,i) ... ... 0 e 1 o 2 n >>>
3)集合其他方法
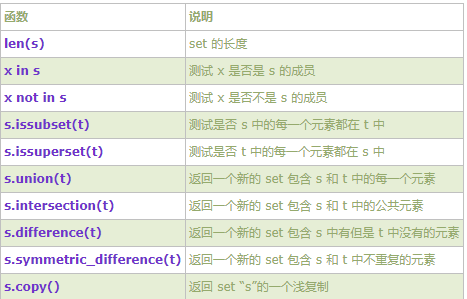
4)集合的操作方法
交集
Python中求集合的交集使用的符号是“&”,返回连个集合的共同元素的集合,即集合的交集。
>>> st1 = set('python') >>> st1 set(['h', 'o', 'n', 'p', 't', 'y']) >>> st2 = set('htc') >>> st2 set(['h', 'c', 't']) >>> st1 & st2 set(['h', 't'])
或者:
>>> st1.intersection(st2)
{'t', 'h'}
并集(合集)
Python中求集合的并集用的是符号“|”,返回的是两个集合所有的并去掉重复的元素的集合。
>>> st1 set(['h', 'o', 'n', 'p', 't', 'y']) >>> st3 = set('two') >>> st3 set(['o', 't', 'w']) >>> st1 | st3 set(['p', 't', 'w', 'y', 'h', 'o', 'n'])
或者:
>>> st1.union(st2)
{'n', 't', 'y', 'p', 'o', 'c', 'h'}
差集
Python中差集使用的符号是减号“-”。
>>> st1 set(['1', '3', '2', '5', '4', '7', '6']) >>> st2 = set('4589') >>> st2 set(['9', '8', '5', '4']) >>> st1 - st2 set(['1', '3', '2', '7', '6'])
或者:
>>> st1.difference(st2)
{'6', '3', '2', '1', '7'}
返回的结果是在集合st1中但不在集合st2中的元素的集合。
集合的不同
查看两个集合的不同之处,使用的difference函数,等价于差集。如:
s1.difference(s3)
这种不同指的是集合s3相对于集合s1,不同的地方,也就是所有在集合s1中,而不再集合s2中的的元素组成的新集合。
>>> s1 set([1, 2, 3, 4, 5]) >>> s2 set([1, 2, 3, 4]) >>> s1.difference(s2) set([5]) >>> s3 set(['1', '8', '9', '5']) >>> s1.difference(s3) set([1, 2, 3, 4, 5])
集合的范围判断
集合可以使用大于(>)、小于(<)、大于等于(>=)、小于等于(<=)、等于(==)、不等于(!=)来判断某个集合是否完全包含于另一个集合,也可以使用子父集判断函数。
定义三个集合s1,s2,s3:
>>> s1=set([1, 2, 3, 4, 5]) >>> s2=set([1, 2, 3, 4]) >>> s3=set(['1', '8', '9', '5'])
大于(>)或大于等于(>=)
>>> s1 > s2 True >>> s1 > s3 False >>> s1 >= s2 True
表示左边集合是否完全包含右边集合,如集合s1是否完全包含集合s2。
小于(<)或 小于等于(<=)
>>> s2 < s1 True >>> s1 < s3 False >>> s3 < s1 False
表示左边的集合是否完全包含于右边的集合,如集合s1是否完全包含于集合s2。
等于(==)、不等于(!=)
>>> s1 == s2 False >>> s2 == s3 False >>> s1 != s2 True
判断两个集合是否完全相同。
不可变集合frozenset
Python中还有一种不可改变的集合,那就是frozenset,不像set集合,可以增加删除集合中的元素,该集合中的内容是不可改变的,类似于字符串、元组。
>>> f = frozenset() >>> f frozenset([]) >>> f = frozenset('asdf') >>> f frozenset(['a', 's', 'd', 'f']) >>> f = frozenset([1,2,3,4]) >>> f frozenset([1, 2, 3, 4]) >>> f = frozenset((1,2,3,4)) >>> f frozenset([1, 2, 3, 4]) >>> f = frozenset({1:2, 'a':2, 'c':3}) >>> f frozenset(['a', 1, 'c'])
如果试图改变不可变集合中的元素,就会报AttributeError错误。
不可变集合,除了内容不能更改外,其他功能及操作跟可变集合set一样。
作业
1. 编程实现对一个元素全为数字的列表,求最大值、最小值
2. 编写程序,完成以下要求:
-
- 统计字符串中,各个字符的个数
- 比如:"hello world" 字符串统计的结果为: h:1 e:1 l:3 o:2 d:1 r:1 w:1
3. 编写程序,完成以下要求:
-
- 完成一个路径的组装
- 先提示用户多次输入路径,最后显示一个完成的路径,比如/home/python/ftp/share
4. 编写程序,完成“名片管理器”项目
-
- 需要完成的基本功能:
- 添加名片
- 删除名片
- 修改名片
- 查询名片
- 退出系统
-
- 程序运行后,除非选择退出系统,否则重复执行功能
