Python3 实现妹子图爬虫
发布时间:2019-08-12 11:52:20编辑:auto阅读(3598)
- Python3 编程
- 使用 BeautifulSoup 解析 HTML 页面
- 使用 Request 爬取 Web 页面
- 使用正则表达式提取所需的关键信息
- urllib下载图片
- pip --version
- pip install PackageName
- pip install beautifulsoup4
- pip install requests
- 抓取每个专题的等信息
- 抓取每个专题的列表,并按列表新建文件夹
- 抓取每一个列表的图片,把每一个MM的写真图片按照文件夹保存到本地
- 通过
Request获得目标页面源码,之后通过BeautifulSoup解析概源码,通过正则表达式提取出专题链接 - from bs4 import BeautifulSoup
- import requests
- import urllib
- start_url="http://www.mzitu.com/"
- def get_mei_channel(url):
- web_data=requests.get(url)
- soup=BeautifulSoup(web_data.text,'lxml')
- channel=soup.select('body > div.main > div.sidebar > div.widgets_hot > span > a')
- for list in channel:
- print(list.get('href'))
- #获取妹子图首页热门专题的链接
- get_mei_channel(start_url)
- http://www.mzitu.com/tag/xiuren
- http://www.mzitu.com/tag/xinggan
- http://www.mzitu.com/tag/youhuo
- http://www.mzitu.com/tag/zhifu
- http://www.mzitu.com/tag/shuiyi
- http://www.mzitu.com/tag/qingchun
- http://www.mzitu.com/tag/xiaohua
- http://www.mzitu.com/tag/rosi
- http://www.mzitu.com/tag/bikini
- http://www.mzitu.com/tag/leg
- http://www.mzitu.com/tag/zouguang
- http://www.mzitu.com/tag/meitun
- http://www.mzitu.com/tag/tgod
- http://www.mzitu.com/tag/shishen
- http://www.mzitu.com/tag/heisi
- http://www.mzitu.com/tag/miitao
- http://www.mzitu.com/tag/ugirls
- http://www.mzitu.com/tag/mistar
- http://www.mzitu.com/tag/bololi
- http://www.mzitu.com/tag/yougou
- http://www.mzitu.com/tag/imiss
- http://www.mzitu.com/tag/dianannan
- #获取专题的列表页
- def get_page_from(channel,pages):
- channel=channel+'/page/{}'.format(pages)
- web_data=requests.get(channel)
- soup=BeautifulSoup(web_data.text,'lxml')
- if soup.find('body > div.main > div.main-content > div.currentpath'):
- pass
- else:
- lists = soup.select('#pins > li > span > a')
- for lists in lists:
- path='E:\MM\{}'.format(lists.get_text())
- isExists = os.path.exists(path)
- if not isExists:
- print("[*]偷偷新建了名字叫做" + path + "的文件夹")
- os.mkdir(path)
- else:
- # 如果目录存在则不创建,并提示目录已存在
- print("[+]名为" + path + '的文件夹已经创建成功')
- for i in range(1,101):
- get_list_info(lists.get('href'),i,path)
- # page_list.insert_one({'url': lists.get('href'), 'title': lists.get_text()})
- get_page_from('http://www.mzitu.com/tag/xiuren',1)
- #获取列表页的详细信息
- def get_list_info(url,page,mmpath):
- # url='http://www.mzitu.com/69075'
- web_data=requests.get(url)
- soup=BeautifulSoup(web_data.text,'lxml')
- src=soup.select('body > div.main > div.content > div.main-image > p > a > img')
- for src in src:
- image_url=src.get('src').split('net')[1].split('01.')[0]
- if page < 10:
- pages='0'+str(page)
- else:
- pages =str(page)
- url_split='http://i.meizitu.net'+image_url+'{}.jpg'.format(pages)
- try:
- html = urlopen(url_split)
- name = url_split.split('/')[5].split('.')[0]
- data = html.read()
- fileName = '{}\meizi'.format(mmpath) + name + '.jpg'
- fph = open(fileName, "wb")
- fph.write(data)
- fph.flush()
- fph.close()
- except Exception:
- print('[!]Address Error!!!!!!!!!!!!!!!!!!!!!')
- from multiprocessing import Pool
- from mmspider_channel import channel_list
- from mmspider_parase import get_page_from
- def get_pages_from(channel):
- for i in range(1,100):
- get_page_from(channel,i)
- if __name__ == '__main__':
- pool = Pool()
- # pool = Pool(processes=6)
- pool.map(get_pages_from,channel_list.split())
一.项目说明
1.项目介绍
本项目通过使用Python 实现一个妹子图图片收集爬虫,学习并实践 BeautifulSoup、Request,Urllib 及正则表达式等知识。在项目开发过程中采用瀑布流开发模型。
2.用到的知识点
本项目中将会学习并实践以下知识点:
爬取后的目录结构如下:(只爬取了一个专题的)

每个目录中都有一系列的图片:

(是不是感觉有点小激动,我也是嫌官网上的查看太麻烦了,so...爬下来慢慢看)
二.基础工具
1.安装Chrome,为了方便查看源代码,推荐开发者经常使用的Chrome浏览器
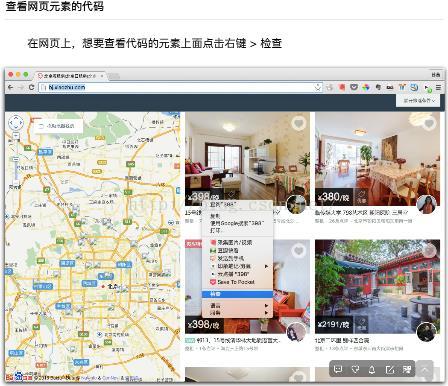
2.安装python3,如果你还不会安装,请看下基础安装python,然后安装pip,(打开你安装的文件夹,找到Script,将这个文件夹的路径添加到环境变量中)
使用下面命令测试下,当然window系统需要打开cmd输入

pip --version安装成功之后

3.window上安装Beautifulsoup,request,lxml
pip install PackageName
第二步,安装库BeautifulSoup4
pip install beautifulsoup4第三步,安装库Requests
pip install requests4.使用PyCharm进行开发,具体请自行google。
三.项目实现
1.目标
本个项目中我们将分别按照如下步骤:
2.程序结构
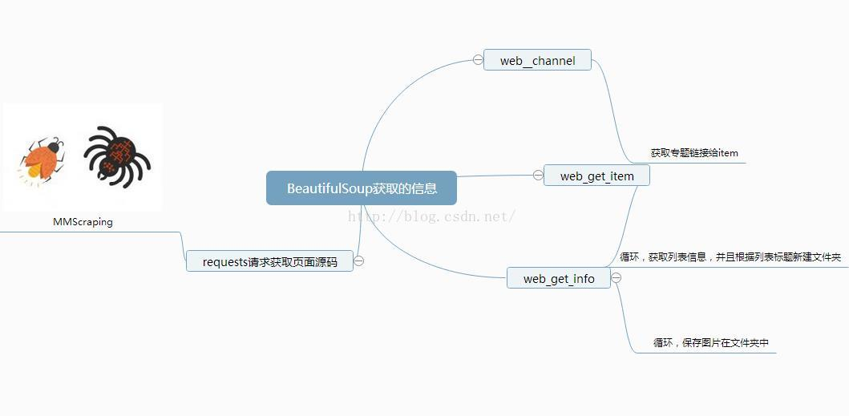
3.流程说明
from bs4 import BeautifulSoup
import requests
import urllib
start_url="http://www.mzitu.com/"
def get_mei_channel(url):
web_data=requests.get(url)
soup=BeautifulSoup(web_data.text,'lxml')
channel=soup.select('body > div.main > div.sidebar > div.widgets_hot > span > a')
for list in channel:
print(list.get('href'))
#获取妹子图首页热门专题的链接
get_mei_channel(start_url)http://www.mzitu.com/tag/xiuren
http://www.mzitu.com/tag/xinggan
http://www.mzitu.com/tag/youhuo
http://www.mzitu.com/tag/zhifu
http://www.mzitu.com/tag/shuiyi
http://www.mzitu.com/tag/qingchun
http://www.mzitu.com/tag/xiaohua
http://www.mzitu.com/tag/rosi
http://www.mzitu.com/tag/bikini
http://www.mzitu.com/tag/leg
http://www.mzitu.com/tag/zouguang
http://www.mzitu.com/tag/meitun
http://www.mzitu.com/tag/tgod
http://www.mzitu.com/tag/shishen
http://www.mzitu.com/tag/heisi
http://www.mzitu.com/tag/miitao
http://www.mzitu.com/tag/ugirls
http://www.mzitu.com/tag/mistar
http://www.mzitu.com/tag/bololi
http://www.mzitu.com/tag/yougou
http://www.mzitu.com/tag/imiss
http://www.mzitu.com/tag/dianannanRequest 获得每个专题链接的目标页面源码,之后通过 BeautifulSoup 解析概源码,通过正则表达式提取出列表链接,并提取列表标题,新建文件夹。
#获取专题的列表页
def get_page_from(channel,pages):
channel=channel+'/page/{}'.format(pages)
web_data=requests.get(channel)
soup=BeautifulSoup(web_data.text,'lxml')
if soup.find('body > div.main > div.main-content > div.currentpath'):
pass
else:
lists = soup.select('#pins > li > span > a')
for lists in lists:
path='E:\MM\{}'.format(lists.get_text())
isExists = os.path.exists(path)
if not isExists:
print("[*]偷偷新建了名字叫做" + path + "的文件夹")
os.mkdir(path)
else:
# 如果目录存在则不创建,并提示目录已存在
print("[+]名为" + path + '的文件夹已经创建成功')
for i in range(1,101):
get_list_info(lists.get('href'),i,path)
# page_list.insert_one({'url': lists.get('href'), 'title': lists.get_text()})
get_page_from('http://www.mzitu.com/tag/xiuren',1)Request 获得每个专题链接的目标页面源码,之后通过 BeautifulSoup 解析概源码,通过正则表达式提取出图片链接,本网站的图片是非常有规律的,这里用了点技巧来构造图片链接,以及做了异常处理,保存图片的到文件夹中
#获取列表页的详细信息
def get_list_info(url,page,mmpath):
# url='http://www.mzitu.com/69075'
web_data=requests.get(url)
soup=BeautifulSoup(web_data.text,'lxml')
src=soup.select('body > div.main > div.content > div.main-image > p > a > img')
for src in src:
image_url=src.get('src').split('net')[1].split('01.')[0]
if page < 10:
pages='0'+str(page)
else:
pages =str(page)
url_split='http://i.meizitu.net'+image_url+'{}.jpg'.format(pages)
try:
html = urlopen(url_split)
name = url_split.split('/')[5].split('.')[0]
data = html.read()
fileName = '{}\meizi'.format(mmpath) + name + '.jpg'
fph = open(fileName, "wb")
fph.write(data)
fph.flush()
fph.close()
except Exception:
print('[!]Address Error!!!!!!!!!!!!!!!!!!!!!')
from multiprocessing import Pool
from mmspider_channel import channel_list
from mmspider_parase import get_page_from
def get_pages_from(channel):
for i in range(1,100):
get_page_from(channel,i)
if __name__ == '__main__':
pool = Pool()
# pool = Pool(processes=6)
pool.map(get_pages_from,channel_list.split())项目目录如下
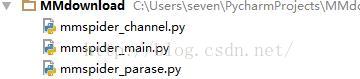
模块源码已经给出,具体自己整合吧!
转载自:http://blog.csdn.net/seven_2016/article/details/52245727
上一篇: Python 操作 AWS S3
下一篇: Python3的fo if while
- H3C基本命令大全
53526
- H3C IRF原理及 配置
40351
- Python exit()函数
34753
- python全系列官方中文文档
30511
- python 获取网卡实时流量
25389
- 1.常用turtle功能函数
25183
- python 获取Linux和Windows硬件信息
23594
- 天天基金网数据接口
18868
- Selenium使用代理IP&无头模式访问网站
15174
- Selenium&Pytesseract模拟登录+验证码识别
14681
- LangGraph Studio可视化
1150°
- LangSmith开发-应用入门
1072°
- LangGraph开发-多轮对话问答机器人
1143°
- LangGraph开发-条件分支/循环图实战
1159°
- LangGraph开发-生态介绍,入门demo实战
1196°
- LangChain-接入12306-HTTP MCP智能体
1351°
- LangChain接入自定义爬虫-MCP工具
1311°
- LangChain接入Filesystem-MCP工具
1286°
- LangChain搭建MCP服务端和客户端流程
1381°
- LangGraph与MCP技术概述
1326°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
