本文所讲的爬虫项目实战属于基础、入门级别,使用的是Python3.5实现的。
本项目基本目标:在猫眼电影中把top100的电影名,排名,海报,主演,上映时间,评分等爬取下来
爬虫原理和步骤
爬虫,就是从网页中爬取自己所需要的东西,如文字、图片、视频等,这样我们就需要读取网页,然后获取网页源代码,从源代码中用正则表达式进行匹配,把匹配成功的信息存入相关文档中。这就是爬虫的简单原理。
操作步骤:
1.确定抓取的数据字段(排名,海报,电影名,主演,上映时间,评分)
2.分析页面html标签结构,找到数据所在位置
3.选择实现方法及数据存储位置(存在在mysql 数据库中)
4.代码写入(requests+re+pymysql)
5.代码调试
确定抓取的页面目标URL:http://maoyan.com/board/4
1.导入库/模块
1 import re 2 import requests 3 import pymysql 4 from requests.exceptions import RequestException #捕获异常
2.请求头域,在网页中查看headers,复制User-Agent内容

请求一个单页内容拿到HTML,定义函数,构建headers,请求成功则代码为200,否则失败重新写入代码
1 def get_one_page(url): 2 try: 3 #构建headers 4 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} 5 response=requests.get(url,headers=headers) 6 if response.status_code==200: 7 return response.text 8 except RequestException: 9 return '请求异常'
3.解析HTML,用正则表达式匹配字符,为非贪婪模式.*?匹配
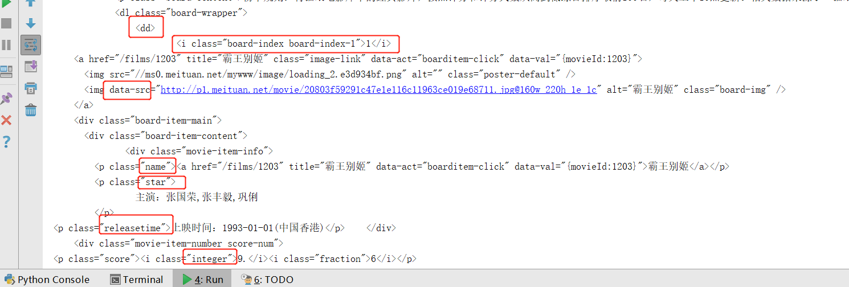
1 def parse_one_page(html): 2 # 创建一个正则表达式对象 3 #使用re.S可以使元字符.匹配到换行符 4 pattern=re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name">' 5 + '<a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' 6 + '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) 7 items = re.findall(pattern, html) 8 # print(items)
运行已经匹配好的第一页内容
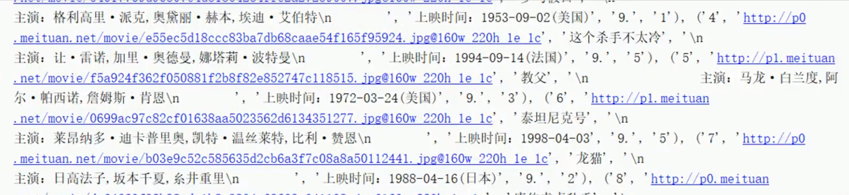
运行结果没有处理的如下:
4.进行数据处理,格式美化,按字段依次排列,去掉不必要的空格符
1 for item in items: 2 yield { 3 'index': item[0], 4 'image': item[1], 5 'title': item[2], 6 'actor': item[3].strip()[3:], # strip():删除前后空白 7 'time': item[4].strip()[5:], 8 'score': item[5] + item[6] 9 }
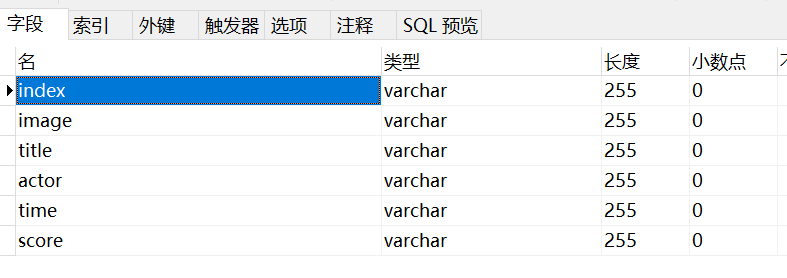
5.创建MySQL数据库,库名movie1表名maoyan,添加我们爬取的6个字段名
6.在python中创建数据库连接,把爬取的数据存储到MySQL
1 def write_to_mysql(content): 2 conn=pymysql.connect(host='localhost',user='root',passwd='123456', 3 db='movie1',charset='utf8') 4 cursor=conn.cursor() 5 index=content['index'] 6 image=content['image'] 7 title=content['title'] 8 actor=content['actor'] 9 time=content['time'] 10 score=content['score'] 11 sql='insert into maoyan values(%s,%s,%s,%s,%s,%s)' 12 parm=(index,image,title,actor,time,score) 13 cursor.execute(sql,parm) 14 conn.commit() 15 cursor.close() 16 conn.close()
调用主函数,运行后得到结果如下:

以上为调取的一页数据,只有TOP10的电影排名,如果需要得到TOP100,则要重新得到URL来构建
第一页的URL为:http://maoyan.com/board/4
第二页的URL为:http://maoyan.com/board/4?offset=10
第三页的URL为:http://maoyan.com/board/4?offset=20
得到页面都是以10来递增URL为:
url='http://maoyan.com/board/4?offset='+str(offset)
需要循环10次即可得到排名前100的电影,并把它写入到数据库中
1 def main(offset): 2 url='http://maoyan.com/board/4?offset='+str(offset) 3 html=get_one_page(url) 4 for item in parse_one_page(html): 5 print(item) 6 write_to_mysql(item) 7 8 if __name__=='__main__': 9 for i in range(0,10): 10 main(i*10)
运行后进入MySQL查看写入的数据

以上是爬取猫眼top100完整代码,如有错误请多指教。
