最近在学习web自动化测试,web自动化测试中元素定位是基本功也是很重要的一环,常用的元素定位方式网上都有很多的,一般采用强大的xpath方式来定位,xpath中又包含了很多其他方法。当然,在学习元素定位之前,需要要对前端要有一定的了解,比如HTML,CSS
百度输入框
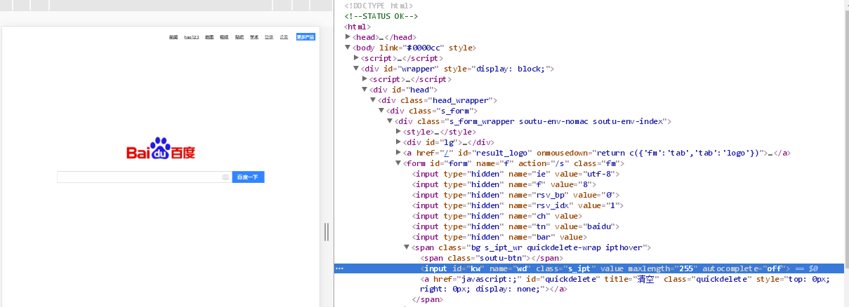
xpath元素定位的主要方法
首先要了解xpath中一些常用的语法规则和常用符号的意义,比如双斜杠// 单斜杠/ 星号* 等等
1. 绝对路径的方式
例如百度输入框的定位你可以写成 find_element_by_xpath("/html/head/body/script/div/script/.../span/input)。所以可以看到这种方式写起来实在是太长了,另一方面,如果百度页面做了更改,这个绝对路径会发生变化,自动化测试的脚本就需要重新维护。
2.相对路径的方式
采用相对路径的方式写xpath,百度的输入框可以这样定位 find_element_by_xpath("//form//span//input"),我是从input的父节点的父节点开始写的,显然这种方式比绝对路径更为方便,但若这个页面中还存在一个一样的相对路径,这个时候可能相对路径就会出错,因此仅靠这种方法写并不实用
3.使用元素索引定位
比如在上图的百度的页面中,标签form 下边有7个input,如果要定位第三个input 就可以写成 find_element_by_xpath(“//form//input[3]”)
4.使用节点中具有唯一性的属性进行匹配
这种方式就是从浏览器F12中,copy出来的xpath常见的方式,例如百度的输入框,input中的id具有唯一性,因此可以写成 find_element_by_xpath("//*[@id="kw"]"),id也可以换成name,classs属性,通常id具有唯一性,如果写的是auto-id说明是每次都变化的,不具有唯一性,不能用。后边说到的网易严选页面中就存在大量的auto-id
5.使用节点中部分属性匹配的方式
A.starts-with
例如百度输入框input中有一个属性 name=wd,我们可以这么定位 find_element_by_xpath("//input[strats-with(@name,'wd')]"),表示:找到一个input节点,它的特征是有一个以 wd开头的name属性,注意是starts,有个s,还有python+selenium的xpath中我只看到了starts-with的方法,不知道有没有ends-with的方式,在java+selenium中是有ends-with的方法。现在很多资料都没写清楚用的什么语言,容易误导人
B.contains
用contains方法,百度输入框的xpath定位可以这样写find_element_by_xpath("//input[contains(@name,'wd')]"),表示找到一个input节点,其中它的name包含wd
还可以采用文本的方式来匹配,如果节点没有其他唯一性的属性的情况,可以尝试使用节点中的文本信息来匹配,可以这么写:find_element_by_xpath("//input[contains(text(),'xx')]") 找到一个input节点,该节点中含有xx的文本信息。contains的方法虽然好用,但会牺牲一定效率,所以尽量给它范围和限制。contains可以用处理有的节点属性中包含空格的情况
6.使用前面几种方法的组合方式
比如定位上图的百度输入框,不使用方式4,采用组合的方法可以这样写find_element_by_xpath("//*[@id='form']/span[1]/input"),表示:这个元素是处于一个id属性为form的节点下的第一个span节点下的input。若百度的输入框元素没有唯一的id,也没有其他太多的信息时,我们选取它最近的一个父辈节点(这个节点含有唯一性的属性,比如唯一的id)再用绝对路径去找到它,当然能不用绝对路径的情况下尽量不用。如果有文本信息就可以用contains方法,组合的方式能解决很多常见的定位问题。
