Python Day16 Django
发布时间:2019-07-30 09:44:56编辑:auto阅读(2131)
-
在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag.
-
在app中创建templatetags模块(模块名只能是templatetags)
- 建任意 .py 文件,如:my_filters_tags.py
-
在使用自定义simple_tag和filter的html文件中导入之前创建的 my_filters_tags.py
{% load my_filters_tags %} - 在模板中使用simple_tag和filter(如何调用)
使用过滤器:注意,过滤器最多接收两个参数{{ l.0|multi_filter:20 }} 结果: 2220 - python manage.py makemigrations --> 用小本本记录 app/models.py文件的任何改动
- python manage.py migrate --> 把上面的改动翻译成SQL语句,然后去数据库中执行
创建Django项目的简单流程
创建一个django project
django-admin startproject 项目名
在项目名目录下创建应用python manage.py startapp blog
在project/settings.py中加入app
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config', #类似这样
]设计url
在project/urls.py中
from app01.views import * #由于把模板放在了app/views.py中,因此这里需要引入url(r'^timer/', timer), # timer(request)
构建视图函数
在app/views.py中
先引入HttpResponse
from django.shortcuts import render, HttpResponse, redirect
from .models import *from django.shortcuts import render,HttpResponse
def timer(request):
import time
ctime=time.time()
return render(request,"timer.html",{"ctime":ctime})创建模板
在templates中创建timer.html
<p>当前时间:{{ ctime }}</p>
启动django项目
命令行启动:python manage.py runserver 8080 #此处注意python这个命令的环境变量
在pycharm中启动:
MTV模型
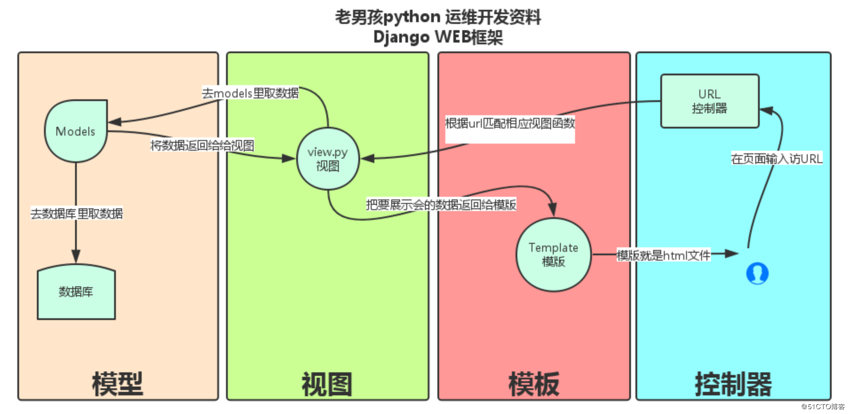
Django的MTV分别代表:
Model(模型):负责业务对象与数据库的对象(ORM)
Template(模版):负责如何把页面展示给用户
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
此外,Django还有一个urls分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
URL控制器(路由层)
简单配置
rlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]参数说明:
一个正则表达式字符串
一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
可选的要传递给视图函数的默认参数(字典形式)
一个可选的name参数
分组
NOTE:
1 一旦匹配成功则不再继续
2 若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。
3 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是^articles 而不是 ^/articles。
4 每个正则表达式前面的'r' 是可选的但是建议加上。
一些请求的例子:
注意下列例子中的$符号,代表以什么结尾,'^books/(\d+)/$'表示books后面只能跟一个路径比如/books/3/,
如果没有$符号的话,/books/2012/12这样的例子也会被匹配到,
捕获一个值,在它周围放置一对圆括号就可以当做参数传给要后面匹配的函数
注意,下面的例子叫做无名分组,按照位置传参
/books/3/
url(r'^books/(\d+)/$', book_detail),
调用函数book_detail(request, 3)/books/2012/12
url(r'^books/(\d+)/(\d+)/$', book_achrive),
调用函数books_achrive(request, 2012, 12)/articles/2005/03/
url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive),
Django 将调用函数views.month_archive(request, '2005', '03')有名分组
上面的示例使用简单的、没有命名的正则表达式组(通过圆括号)来捕获URL 中的值并以位置 参数传递给视图。
在更高级的用法中,可以使用命名的正则表达式组来捕获URL 中的值并以关键字 参数传递给视图。
在Python 正则表达式中,命名正则表达式组的语法是(?P<name>pattern),其中name 是组的名称,pattern 是要匹配的模式。
/books/2012/12/
url(r'^books/(?P<year>\d+)/(?P<month>\d+)/$', book_achrive),
传参books_achrive(request, year=2012, month=12)注意,有名分组相当于关键字传参,在views中的函数接收参数时名字就不能随便起了,
这个例子里要接收 def timer(request, year, month):
分发
URLconf 不检查请求的方法。换句话讲,所有的请求方法 —— 同一个URL的POST、GET、HEAD等等 —— 都将路由到相同的函数
将url匹配文件写到不同的app中有利于解耦,因此用到url分发
第一步,在url后面引入include
第二部,在app目录总新建urls.py文件
语法:
from django.conf.urls import url, include
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^app01/', include('app01.urls')),
]第三部,将project/urls.py中的内容拷贝到app/urls.py文件中,然后删掉不要的
此时,访问网页时,url地址需要加上/app01/
反向解析
访问网页的url由于业务变化等关系可能会变动,此时引用他们的地方就会面临更改的问题。
在URL控制器(project/urls.py)中,给匹配规则起个别名可以解决这个问题,这就叫做反向解析
在需要URL 的地方,对于不同层级,Django 提供不同的工具用于URL 反查:
在模板中:使用url 模板标签。
在Python 代码中:使用django.core.urlresolvers.reverse() 函数。
在更高层的与处理Django 模型实例相关的代码中:使用get_absolute_url() 方法。
例子:
from django.conf.urls import url
from . import views
urlpatterns = [
#...
url(r'^login/', login, name="xxx"),
#...
]你可以在模板的代码中使用下面的方法获得它们:<form action="{% url 'xxx' %}" method="post">
MTV--View(视图层)
请求对象 request
request.GET
一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象
request.POST
一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。
request.method
一个字符串,表示请求使用的HTTP 方法。必须使用大写。
例如:"GET"、"POST"
request.path
一个字符串,表示请求的路径组件(不含域名)。
例如:"/music/bands/the_beatles/"
除此之外还有其他很多request属性
响应对象
Httpresponse()
返回给定的字符串
例如:
def timer(request):
import time
ctime = time.time()
return HttpResponse(ctime)render()
结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的HttpResponse 对象。
例如:return render(request, "timer.html", {"ctime": ctime})
redirect()
接受一个URL参数,表示跳转到指定的URL。
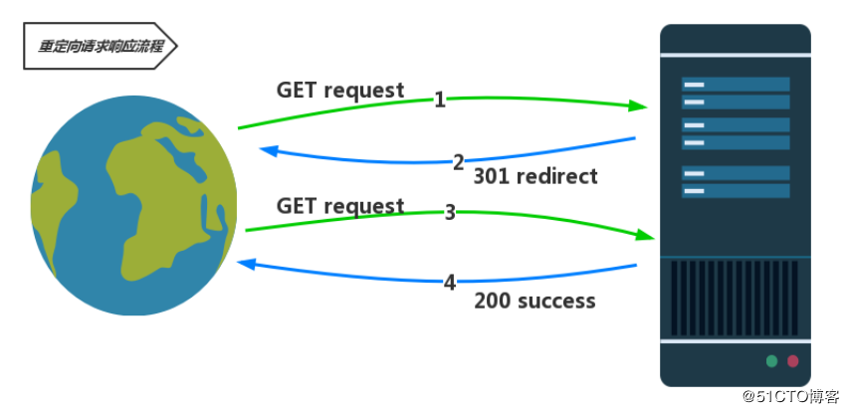
跳转
例如:return redirect("/app01/timer/")
MTV--Template(模板层)
我们templates下面新建的html文件就叫做模板
python的模板:HTML代码+模板语法
模版包括在使用时会被值替换掉的变量,和控制模版逻辑的标签
模板语法之变量
渲染变量 {{ }}
举例1:
视图函数
def temp_func(request):
l = [111, 222, 333]
return render(request, "temp.html", {"l": l})在模板中调用
<body>
<p>{{ l }}</p>
</body>此时页面显示:[111, 222, 333]
举例2:
<body>
<p>{{ l.0 }}</p>
</body>此时页面显示:111
(这种取值方式类似索引)
举例3:
视图函数:
def temp_func(request):
l = [111, 222, 333]
dic = {"name": "dzm", "age": 18}
return render(request, "temp.html", {"l": l, "dic":dic})模板:
<body>
<p>{{ dic }}</p>
<p>{{ dic.name }}</p>
</body>此时页面显示:
{'name': 'dzm', 'age': 18}
dzm举例4:
除此之外还可以引用类
还可以在视图函数中建一个类的对象列表
然后引用这个列表
视图函数:
def temp_func(request):
class Person(object):
def __init__(self,name,age):
self.name = name
self.age = age
alex = Person("alex", 45)
egon = Person("egon", 36)
Person_list = [alex, egon]
return render(request, "temp.html", locals())在模板中引用这个类对象列表
<p>{{ egon.name }}</p>
<p>{{ Person_list.0.name }}</p>结果:
egon
alex还可以引用对象的方法{{ dic.name.upper }}
特殊技能
如果需要传递的参数太多,可以使用如下方法:return render(request, "temp.html", locals())
locals()可以直接将函数中所有的变量全部传给模板
过滤器
举例1:(add)
视图函数:
def temp_func(request):
l = [111, 222, 333]
return render(request, "temp.html", locals())
模板:
<p>{{ l.1|add:100}}</p>
结果:
322(加了100)举例2:(date)
视图函数:
增加
now = datetime.datetime.now()
模板:
{{ now|date:"Y-m-d" }}
显示:
2018-04-18举例3:(filesizeformat)
将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)
模板:
{{ value|filesizeformat }}举例4:(safe)
Django的模板中会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全。
但是有的时候我们可能不希望这些HTML元素被转义。
如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。
视图函数:
s = "<a href='http://www.baidu.com'>hello</a>"
模板:
<p>{{ s|safe }}</p>模板之标签
渲染标签 {% %}
for循环
举例1:for循环
遍历每一个元素:
{% for Person in Person_list %}
<p>{{ Person.name }}:{{ Person.age }}</p>
{% endfor %}结果:
alex:45
egon:36遍历一个字典:
{% for key,val in dic.items %}
<p>{{ key }}:{{ val }}</p>
{% endfor %}注:循环序号可以通过{{forloop}}显示
举例:
<p>{{ forloop.counter }} {{ Person.name }}:{{ Person.age }}</p>
forloop.counter0 #从0开始
forloop.counter #从1开始计数if
{% if %}会对一个变量求值,如果它的值是“True”(存在、不为空、且不是boolean类型的false值),对应的内容块会输出
{% if l.0 > 100 or l.0 < 0 %}
<p>无效</p>
{% elif l.0 > 80 and l.0 < 100 %}
<p>优秀</p>
{% else %}
<p>凑活吧</p>
{% endif %}csrf_token
这个标签用于跨站请求伪造保护
没有这个标签的POST请求会被拦截
提示Forbidden (403) CSRF verification failed. Request aborted.
使用方法:
<form action="{% url 'xxx' %}" method="post">
{% csrf_token %}
<p>用户名 <input type="text" name="user"></p>
<p>密码 <input type="password" name="pwd"></p>
<input type="submit">
</form>添加{% csrf_token %}后,浏览器向web服务器发送GET请求时会给浏览器返回一个键值对,等同于一个令牌。
有了这个令牌后这个网页再提交POST请求时web服务器会做验证,之后才会通过
自定义过滤器和标签
from django import template
register = template.Library()
@register.filter
def multi_filter(x,y):
return x * y
@register.simple_tag
def multi_tag(x,y):
return x * y使用标签:
{% multi_tag 20 40 %}
结果:
800MTV--Model(模型层)
ORM---对象关系映射
类名 ------表名
类属性 ------表字段
类实例对象 ------表记录
创建表(建立模型)
举例一张Book表:
| id | title |
|---|---|
| 1 | python |
| 2 | java |
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=6, decimal_places=2)
create_time = models.DateField()
def __str__(self): #这个方法定义了当object调用str()时应该返回的值
return self.titleid 字段是自动添加的
CharField需要max_length参数来指定VARCHAR数据库字段的大小
DecimalField括号里的6代表最多6位数字,2表示必须有两位小数,1111.22这样的形式
一旦你建立好数据模型之后,django会自动生成一套数据库抽象的API,可以让你执行关于表记录的增删改查的操作
技巧
通过logging可以查看翻译成的sql语句
在settings.py的最后添加如下内容
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}数据迁移,执行两个命令
方法1:在Terminal中输入
方法2:在pycharm中启动manage.py控制台
makemigrations
migrate
添加记录
方式1:
obj新添加记录对象
obj = Book.objects.create(title="python", publish_id=2)
或者
publish_obj = Publish.objects.filter(id=2).first()
obj = Book.objects.create(title="python", publish=publish_obj)
方式2:
obj=Book(title="java")
obj.save()
单表记录操作与查询API
查询记录API(QuerySet)
从数据库中查询出来的结果一般是一个集合,这个集合叫做 QuerySet
<1> all(): 查询所有结果 Returns a new QuerySet
all() QuerySet <QuerySet [<Book: Book object>, <Book: Book object>]>
book_list = Book.objects.all()
print(book_list)
<2> filter(kwargs): 它包含了与所给筛选条件相匹配的对象 Returns a new QuerySet
后面加.first()才是对象**
filter() QuerySet <QuerySet [<Book: Book object>]> <QuerySet [<Book: python>]>
book_list = Book.objects.filter(price=123, title="python") #两个条件是且的关系
print(book_list)
book = Book.objects.filter(price=123, title="python")[0]
print(book) # model对象 python
<3> get(kwargs): 返回与所给筛选条件相匹配的对象**,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误,返回的是object
get() model对象 python get()的结果只能有一个
book = Book.objects.get(price=123, title="python")
print(book)
<5> exclude(**kwargs): 取反,它包含了与所给筛选条件不匹配的对象 Returns a new QuerySet
<4> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
ret = Book.objects.all().values("title")
print(ret) # <QuerySet [{'title': 'python'}, {'title': 'go'}]>values的本质就是一个循环,类似下面模拟的过程
temp=[]
for obj in Book.objects.all():
temp.append({
"title":obj.title
})<9> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
<6> order_by(*field): 对查询结果排序
<7> reverse(): 对查询结果反向排序
<8> distinct(): 去重,从返回结果中剔除重复纪录 Returns a new QuerySet
ret = Book.objects.all().values("price").distinct()
print(ret)
<10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
用的是SQL:SELECT COUNT(*)
c = Book.objects.all().count()
print(c)
<11> first(): model对象,返回第一条记录
<12> last(): 返回最后一条记录
<13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
判断有没有记录,本质是在select语句后面加上 LIMIT 1,这样就避免遍历整个数据表
ret = Book.objects.all().exists()
if ret:
print("ok")
需要注意两点,第一谁可以调用这个api,第二这个api返回的是什么
QuerySet 支持链式查询
找出名称含有abc, 但是排除年龄是23岁的
Person.objects.filter(name__contains="abc").exclude(age=23)
删除记录
Book.objects.filter(price=123,title="python").delete()
更新记录
Book.objects.filter(price=123,title="python").update(title="python123")
双下划线之单表查询
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
models.Tb1.objects.filter(name__contains="ven")
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
Book.objects.filter(title__startswith="py") # __startswith以什么开头
Book.objects.filter(price__lt=120) # 小于
Book.objects.filter(price__gt=120) # 大于
startswith,istartswith, endswith, iendswith多表操作
表关系与操作
一对多关系:关联字段
多对多关系:创建关系表
增删操作举例
增
.add 增加
book_obj.author.add(1, 2, 3)
book_obj.author.add(*[1, 2, 3])删
.remove(1,2) 删除book_obj.author.remove(*[1, 2])
.clear() 清空book_obj.author.clear()
还有个.set() 先清空再添加
举例说明
models中
from django.db import models
# Create your models here.
class Book(models.Model): # 书籍表
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=6, decimal_places=2)
create_time = models.DateField()
memo = models.CharField(max_length=32, default="") # 注意这个字段是后加的,因此默认为空
publish = models.ForeignKey(to="Publish", default=1) # 关联字段
author = models.ManyToManyField("Author") # 创建关系表
def __str__(self):
return self.title
class Publish(models.Model): # 出版社表
name = models.CharField(max_length=32)
email = models.CharField(max_length=32)
class Author(models.Model): # 作者表
name = models.CharField(max_length=32)解释
上面是书籍、出版社、作者三张表
其中出版社对书籍是一对多的关系,使用如下语句创建关联字段
publish=Foreignkey(to="Publish",to_field="")
作者与书籍之间是多对多的关系,这就需要创建关系表,这个关系表此处由ORM代为创建
author = models.ManyToManyField("Author") # 创建关系表
其实还有个OneToOneField代表一对一
author这个字段是桥梁作用,通过它与Author表产生关系,从而创建关系表app01_book_author
注意了:
Book里这个author只是这个类的属性,在最终生成的数据库表中并没有这个字段,只是用于orm生成关系表
最终会生成四张表
app01_author # 作者表
app01_book # 书籍表
app01_publish # 出版社表
app01_book_author # 自动生成的作者与书籍之间的关系表
views中:
def addbook(request):
if request.method == "POST":
title = request.POST.get("title")
price = request.POST.get("price")
date = request.POST.get("date")
publish_id = request.POST.get("publish_id")
# 注意了,get只能取到最后一个值,author_id_list传过来的是一个列表, 所以要使用getlist
author_id_list = request.POST.getlist("author_id_list")
print(author_id_list)
# 绑定一对多的关系,书籍与出版社的关系
obj = Book.objects.create(title=title, price=price, create_time=date, publish_id=publish_id)
# 绑定书籍与作者的多对多的关系,列表前面加个*等于把所有内容都传过去,不用自己写for循环, 会自动save
obj.author.add(*author_id_list)
return redirect("/books/")
else:
publish_list = Publish.objects.all()
author_list = Author.objects.all()
return render(request, "addbook.html", locals())templates中
.pk就是主键
publish.pk就是Publish这张表的主键,在templates可以直接引用
.add 增加
.remove(1,2) 删除
.clear() 清空
多表查询
一对多查询
book_obj = Book.objects.filter(id=6).first()
#book_obj.publish: 与这本书籍关联的出版社对象
print(book_obj.publish.name)
print(book_obj.publish.email)多对多查询
book_obj = Book.objects.filter(id=6).first()
#book_obj.author.all(): 与这本书关联的作者对象的集合,Queryset
print(book_obj.author.all())
返回结果:(models中的相关类加了__str__)
<QuerySet [<Author: alex>, <Author: egon>]>templates中显示多个作者的方法
<td>
{% for author in book.author.all %}
{{ author.name }}
{% if not forloop.last %}
,
{% endif %}
{% endfor %}
</td>多表的数据更新等操作
def editbook(request, id):
if request.method == "POST":
title = request.POST.get("title")
price = request.POST.get("price")
date = request.POST.get("date")
publish_id = request.POST.get("publish_id")
author_id_list = request.POST.getlist("author_id_list")
Book.objects.filter(id=id).update(title=title, price=price, create_time=date, publish_id=publish_id)
book = Book.objects.filter(id=id).first()
book.author.set(author_id_list)
return redirect("/books/")
else:
publish_list = Publish.objects.all()
author_list = Author.objects.all()
edit_obj = Book.objects.filter(id=id).first()
return render(request, "editbook.html", locals())
上一篇: python装饰器 运行时间
下一篇: java与as3的socket通信
- H3C基本命令大全
53530
- H3C IRF原理及 配置
40353
- Python exit()函数
34754
- python全系列官方中文文档
30514
- python 获取网卡实时流量
25389
- 1.常用turtle功能函数
25183
- python 获取Linux和Windows硬件信息
23597
- 天天基金网数据接口
18871
- Selenium使用代理IP&无头模式访问网站
15174
- Selenium&Pytesseract模拟登录+验证码识别
14684
- LangGraph Studio可视化
1151°
- LangSmith开发-应用入门
1073°
- LangGraph开发-多轮对话问答机器人
1143°
- LangGraph开发-条件分支/循环图实战
1161°
- LangGraph开发-生态介绍,入门demo实战
1198°
- LangChain-接入12306-HTTP MCP智能体
1353°
- LangChain接入自定义爬虫-MCP工具
1311°
- LangChain接入Filesystem-MCP工具
1286°
- LangChain搭建MCP服务端和客户端流程
1382°
- LangGraph与MCP技术概述
1326°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
