python3基础:文件操作
发布时间:2019-07-29 10:28:41编辑:auto阅读(2338)
相对路径和绝对路径
相对路径:顾名思义就是相对于当前文件的路径。网页中一般表示路径使用这个方法。
绝对路径:绝对路径就是主页上的文件或目录在硬盘上真正的路径。
比如 c:/apache/cgi-bin 下的,那么 c:/apache/cgi-bin就是cgi-bin目录的绝对路径
文件操作模式

文件操作常用方法:
open()函数:
open()函数,用来打开一个文件,返回新打开文件的描述符
语法:
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
file:文件名称
mode:指定文件的打开方式,其中,‘rt’为默认方式(t也就是text,代表文本文件)
encoding:编码或者解码方式。默认编码方式依赖平台,如果需要特殊
设置,可以参考codecs模块,获取编码列表。encoding不写的话默认用的是GBK
newline:换行控制,参数有:None,’\n’,’\r’,’\r\n。为None的话,写‘\r’‘\r\n’‘\n’的话全部转换成‘\n’
代码示例1:换行控制
>>> with open('b.txt','w+',encoding='utf-8') as fp:
... fp.write('a\r\nb\rc\nd')
...
8
>>> with open('b.txt',encoding='utf-8') as fp:
... fp.read()
...
'a\n\nb\nc\nd'
代码示例2:分别以r+/w+/a+方式读写文件
r+
>>> fp = open("e:\\a.txt","r+")
>>> fp.read()#文件指针在开头,不会清空文件,所以能读出内容
'a\n\nb\nc\nd'
>>> fp.tell()
10
>>> fp.write("hello")
5
>>> fp.seek(0,0)
0
>>> fp.read()
'a\n\nb\nc\ndhello'
>>> fp.close()
a+
>>> fp = open("e:\\a.txt","a+")
>>> fp.read()#文件指针在末尾,所以读出的是空字符串
''
>>> fp.tell()
15
>>> fp.seek(0,0)
0
>>> fp.read()#不会清空文件,所以文件指针回到开头后能读出内容
'a\n\nb\nc\ndhello'
>>> fp.tell()
15
>>> fp.seek(0,0)
0
>>> fp.write("world!")#不管游标在哪里,都是在最后去写入
6
>>> fp.seek(0,0)
0
>>> fp.read()#不管游标在哪里,都是在最后去写入
'a\n\nb\nc\ndhelloworld!'
>>> fp.close()
w+:w模式即使什么都没做都会把文件清空,而且没有提示
>>> fp = open("e:\\a.txt","w+")
>>> fp.tell()
0
>>> fp.read()#会把文件清空,所以读不出来
''
>>> fp.write("hello world!")
12
>>> fp.read()#write完成后是在文件的最后,所以读不出来
''
>>> fp.seek(0,0)
0
>>> fp.read()
'hello world!'
>>> fp.close()
with上下文管理的原理
实现了上下文管理,__enter__实现初始化的工作,并且返回一个值;所有程序执行完之后自动调用__exit__执行回收的工作
class Sample:
def __enter__(self):
print("In __enter__()")
return "Foo"
def __exit__(self,type,value,trace):
print("In __exit__()")
def get_sample():
return Sample()
with get_sample() as sample:#__enter__()返回的值赋给sample
print("sample:",sample)
运行结果:
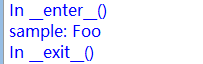
文件对象
底层文件描述符是一个数字,类似于句柄。一个文件被打开后,你就会得到一个文件描述符,然后就可以得到有关该文件的各种信息
属性 描述
file.closed 返回true如果文件已被关闭,否则返回false
file.mode 返回被打开文件的访问模式
file.name 返回文件的名称
代码示例:’’‘文件对象’’’
fp = open( "a.py",'w')
print ("文件是否关闭:", fp.closed)
print ("文件的访问模式:", fp.mode)
print ("文件名称:", fp.name)
#关闭文件
fp.close()
read([size]):读取文件
size为读取的长度,以byte为单位。如果不指定参数的话,表示一次性读取全部的文件内容,并以字符串形式返回,并且每一行的结尾会有一个"\n"符号。
代码示例:
>>> fp = open('cc.txt')
>>> fp.read()
'1234b67890\n'
>>> fp.close()
>>>
>>> fp = open('cc.txt')
>>> fp.read(5)
'1234b'
>>> fp.close()
readline([size]):读取文件
读取一行,如果给定了size有可能返回的只是一行的一部分,以字符串的形式返
回,并且结尾会有一个换行符"\n"。读完一行,文件操作标记移动到下一行的
开头。
代码示例:
>>> fp = open('f.txt')
>>> fp.readline(3)
'hel'
>>> fp.readline(3)
'lo '
>>> fp.readline(3)
'wor'
>>> fp.readline(3)
'ld!'
>>> fp.readline(3)#大于某行剩余的字符时只返回剩余的字符
'1\n'
>>> fp.readline(3)
'hel'
>>> fp.readline(3)
readlines([size]):读取文件
把文件每一行作为一个list的一个成员,是一个字符串,并且结尾会有一个换行符"\n",并返回这个list。这个函数的内部是通过循环调用readline()来实现的。如果指定了size参数,表示读取文件指定内容的长度,此时就有可能只能读取文件的一部分,并且结尾会有一个换行符"\n"。
readlines(hint=-1)
Read and return a list of lines from the stream. hint can be specified to control the number of lines read: no more lines will be read if the total size (in bytes/characters) of all lines so far exceeds hint.
‘test.txt’中有3行内容:
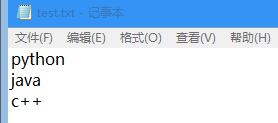
>>> fp = open('test.txt')
>>> fp.readlines()#读取全部文件内容并以列表返回
['python\n', 'java\n', 'c++\n']
>>> fp.seek(0,0)
0
>>> for i in range(16):
... print(fp.readlines(i))
... fp.seek(0,0)
...
['python\n', 'java\n', 'c++\n']#i=0
['python\n']#i=1
['python\n']#i=2
['python\n']#i=3
['python\n']#i=4
['python\n']#i=5
['python\n']#i=6
['python\n', 'java\n']#i=7
['python\n', 'java\n']#i=8
['python\n', 'java\n']#i=9
['python\n', 'java\n']#i=10
['python\n', 'java\n']#i=11
['python\n', 'java\n', 'c++\n']#i=12
['python\n', 'java\n', 'c++\n']#i=13
['python\n', 'java\n', 'c++\n']#i=14
['python\n', 'java\n', 'c++\n']#i=15
总结:
当指定的size等于0或者大于文件总大小时返回的都是全部文件内容;
当指定的size小于一行文件的字符数时返回的时一行文件;
同理。。。。
write(str):将字符串写入文件中
把str写到文件中,默认是不加换行符的,所以如果想换行的话,得手动加入换行符’\n’
代码示例:’’‘将a26 b25…z1输出到文件中’’’
with open('aa.txt','w+',encoding='utf-8') as fp:
for i in range(26,0,-1):
fp.write(chr(ord('z')-i+1)+str(i)+'\n')
writelines(seq):将序列写入文件中
把seq(序列)的内容全部写到文件中(多行一次性写入),也不会自动加入换行符。
注意:序列中的内容也必须是字符串类型的数据,才能成功写入文件
>>> fp = open("e:\\a.txt",'w')
>>> fp.writelines(["1\n","2\n","3\n"])
>>> fp.close()
close():关闭文件
刷新缓冲区里任何还没写入的信息,并关闭该文件,不能再进行写入。用 close()方法关闭文件是一个很好的习惯。如果文件关闭后,还对文件进行操作就会产生ValueError错误,但如果不及时关闭文件,有可能产生句柄泄露,丢失数据。而且不关闭文件的话占资源,浪费句柄数量,句柄数量有限 。
代码示例:
>>> fp = open('test.txt')
>>> fp.close()
>>> print('文件是否关闭:',fp.closed)
文件是否关闭: True
flush():将缓冲区指定内容写入硬盘
代码示例:
testList = ['test1\n', 'test2\n', 'test3', '文件操作']
fp = open( "bb.txt",'w+')
print (fp.read(),end="\n")
fp.writelines(testList)
fp.flush()
fp1 = open( "bb.txt",'r')
print (fp1.read(),end="\n")
fp.close()
fp1.close()
fileno():返回长整形的文件标签
>>> fp = open("a.txt")
>>> fp.fileno
<built-in method fileno of _io.TextIOWrapper object at 0x0000000000387B40>
>>> fp.fileno()
3
tell():返回文件操作标记的当前位置
以文件的开头为基准点
代码示例:
>>> fp = open('test.txt')
>>> fp.tell()
0
>>> fp.readline()
'python\n'
>>> fp.tell()
8
>>> fp.close()
seek(offset[,from]):文件定位
作用:改变当前文件的位置。
参数说明:
Offset:表示要移动的字节数;
From:指定开始移动字节的参考位置。如果from
设为0(默认值):将文件的开头作为移动字节的参考位置;
设为1:则使用当前的位置作为参考位置;
设为2:那么该文件的末尾将作为参考位置。
注意:
如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾
文件必须是以二进制形式打开的才能以当前位置或末尾为参考位置进行定位。
代码示例:
>>> fp =open('aa.txt')
>>> fp.read()
'a26\nb25\nc24\nd23\ne22\nf21\ng20\nh19\ni18\nj17\nk16\nl15\nm14\nn13\no12\np11\
nq10\nr9\ns8\nt7\nu6\nv5\nw4\nx3\ny2\nz1\n'
>>> fp.seek(-5,2)#以文本形式打开的文件,以末尾为参考位置报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
io.UnsupportedOperation: can't do nonzero end-relative seeks
>>>
>>> fp = open("a.txt","rb+")
>>> fp.read()
b'1234aaxxx\r\ngloryroad\r\nbxxxx\r\n'
>>> fp.tell()
29
>>> fp.seek(5,1)
34
>>> fp.seek(-5,1)
29
>>> fp.seek(-5,1)
24
>>> fp.read()
b'xxx\r\n'
>>> fp.seek(-5,1)
24
>>> fp.seek(2,1)
26
>>> fp.read()
b'x\r\n'
>>>
>>> fp =open('aa.txt','rb')
>>> fp.read()
b'a26\r\nb25\r\nc24\r\nd23\r\ne22\r\nf21\r\ng20\r\nh19\r\ni18\r\nj17\r\nk16\r\nl
15\r\nm14\r\nn13\r\no12\r\np11\r\nq10\r\nr9\r\ns8\r\nt7\r\nu6\r\nv5\r\nw4\r\nx3\
r\ny2\r\nz1\r\n'
>>> fp.seek(-5,2)
116
>>> fp.read()
b'\nz1\r\n'
>>> fp.seek(5,1)
126
>>> fp.read()
b''
>>> fp.seek(-5,1)
121
>>> fp.read()
b''
>>> fp.seek(-20,2)
101
>>> fp.read()
b'v5\r\nw4\r\nx3\r\ny2\r\nz1\r\n'
truncate([size]):裁剪文件
把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
代码示例:’’’’’’
fp = open('dd.txt','r+',encoding='utf-8')
fp.readline()
fp.truncate(20)
print(fp.tell())
print(fp.read())
fp.close()
‘’‘读取文件中指定的行数’’’
#方法一:
with open('dd.txt',encoding='utf-8') as fp:
print(fp.readlines()[1])
#方法二:
count=0
fp = open('dd.txt',encoding='utf-8')
for line in fp:
count+=1
if count ==2:
print(line)
fp.close()
linecache 模块
linecache 模块允许从任何文件里得到任何的行,并且使用缓存进行优化,常见的情况是从单个文件读取多行。
代码示例:’’’’’’
import linecache
file_content= linecache.getlines('c:\\1.txt')#所有文件内容以列表的形式缓存到内存
print (file_content)
file_content =linecache.getlines('c:\\1.txt')[0:4]
print (file_content)
file_content =linecache.getline('c:\\1.txt',2)#读取指定行
print (file_content)
file_content =linecache.updatecache('c:\\1.txt')
print (file_content)
#更新缓存
linecache.checkcache('c:\\1.txt')
#清理缓存,如果你不再需要先前从getline()中得到的行
linecache.clearcache()
1.3.pickle模块:持久化/序列化
python中的对象是不能保存的,关闭程序后所有的变量或者对象都没有了。持久地储存对象(序列化)可以在一个文件中储存任何Python对象,之后又可以把它完整无缺地取出来。
使用场景:用文件的方式存储数据,或者不同系统之间交换数据时使用
import pickle as p
shoplistfile = 'e:\\shoplist.data'
#the name of the file where we will store the object
shoplist = ['apple', 'mango', 'carrot']
animallist=['hippo','rabbit']
#Write to the file
f = open(shoplistfile, 'wb')
p.dump(shoplist, f) # dump the object to a file
p.dump(animallist,f)
f.close()
del shoplist # remove the shoplist
del animallist
#Read back from the storage
f = open(shoplistfile,'rb')
storedlist = p.load(f)#先进先出
animallist= p.load(f)
print (storedlist)
print (animallist)
注意:load时必须按dump时的先后顺序,没有办法判断反序列化之后的类型,所以必须要指定dump时的顺序,而且时先进先出
灵活使用可参考shelve模块也是 用来持久化任意的Python对象
上一篇: Python3学习笔记之is == in
下一篇: Python 3.7之使用web api
- H3C基本命令大全
53530
- H3C IRF原理及 配置
40352
- Python exit()函数
34754
- python全系列官方中文文档
30514
- python 获取网卡实时流量
25389
- 1.常用turtle功能函数
25183
- python 获取Linux和Windows硬件信息
23597
- 天天基金网数据接口
18869
- Selenium使用代理IP&无头模式访问网站
15174
- Selenium&Pytesseract模拟登录+验证码识别
14684
- LangGraph Studio可视化
1151°
- LangSmith开发-应用入门
1073°
- LangGraph开发-多轮对话问答机器人
1143°
- LangGraph开发-条件分支/循环图实战
1161°
- LangGraph开发-生态介绍,入门demo实战
1198°
- LangChain-接入12306-HTTP MCP智能体
1353°
- LangChain接入自定义爬虫-MCP工具
1311°
- LangChain接入Filesystem-MCP工具
1286°
- LangChain搭建MCP服务端和客户端流程
1382°
- LangGraph与MCP技术概述
1326°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
