原理很简单,通过发送resquest请求获取服务器的response,再使用xpath提取其中我们需要的数据,然后保存到文件中。
先看看我爬取的结果:

首先,需要用到的模块有两个:
•requests
•lxml
- 第一步,我们先用Chrome的检查分析豆瓣250页面的http请求报头(Request URL):•

让我们把注意力放在箭头所指的start = 0处,当start = 0时,意味着发送的是第一页榜单的URL请求
豆瓣设定每页榜单只显示25部电影,故共有10页,每页的Resquest URL也不一样。
不过,每一页的Resquest URL都有一个很明显的规律,而这个规律帮了我们大忙。
让我们再看一张图:

这是250榜单的最后一页的URL请求,可以看到start的值已经变为了从第一页的0增长到了225
豆瓣250榜单共有10页,到此,规律已经很明显了,即:
每增长一页,start的值就增加25。
- 第二步,可以开始发送请求了
我们在上一步得到了规律,start 在每次请求中都 +=25
所以我们可以写一 个 for 循环,在循环内发送请求,并在其中定义一个变量 count ,使它在每次循环结束都 +=25,
先用 str.format(count) 函数来把count 赋给URL字符串,再发送请求
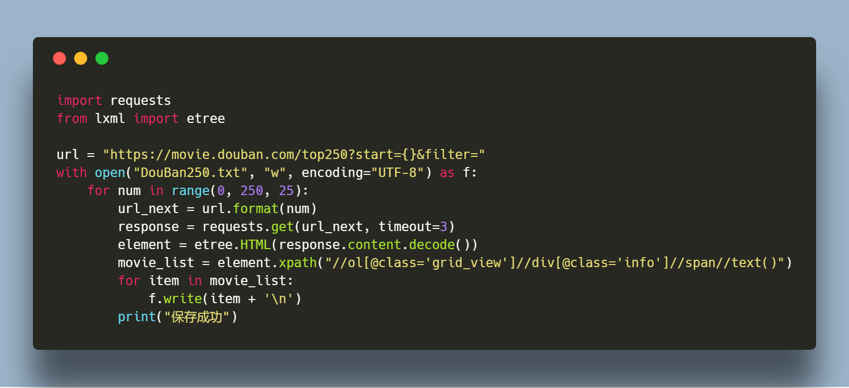
- 第三步,接收response,提取我们需要的数据
提取数据时,我用的是 etree.xpath() 函数,在形参输入xpath语言提取需要的数据标签即可,然后保存。
上代码↓