Python 常用模块续
发布时间:2019-07-23 09:43:37编辑:auto阅读(1746)
一、logging
用于记录日志并线程安全的模块
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
filename='log.txt',
filemode='w'
)
logging.debug("debug messages")
logging.info("info messages")
logging.warning("warning messages")
logging.error("error messages")
logging.critical("critical messages")日志文本结果
2018-03-23 10:33:43 AM - root - DEBUG -os_module: debug messages
2018-03-23 10:33:43 AM - root - INFO -os_module: info messages
2018-03-23 10:33:43 AM - root - WARNING -os_module: warning messages
2018-03-23 10:33:43 AM - root - ERROR -os_module: error messages
2018-03-23 10:33:43 AM - root - CRITICAL -os_module: critical messages日志基本配置选项:
| Format | Description |
|---|---|
| filename | 指定日志文件名 |
| filemode | 指定操作日志文件的模式,默认是‘a’ |
| format | 记录日志的格式 |
| datefmt | 记录日期时间的格式 |
| style | 样式 |
| level | 指定要记录的日志级别 |
| stream | 使用指定的流初始化,与filename不可同时配置 |
| handlers | 指定iterable,与filename和stream不兼容 |
日志等级:
| level | Numeric value |
|---|---|
| CRITICAL | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
日志格式: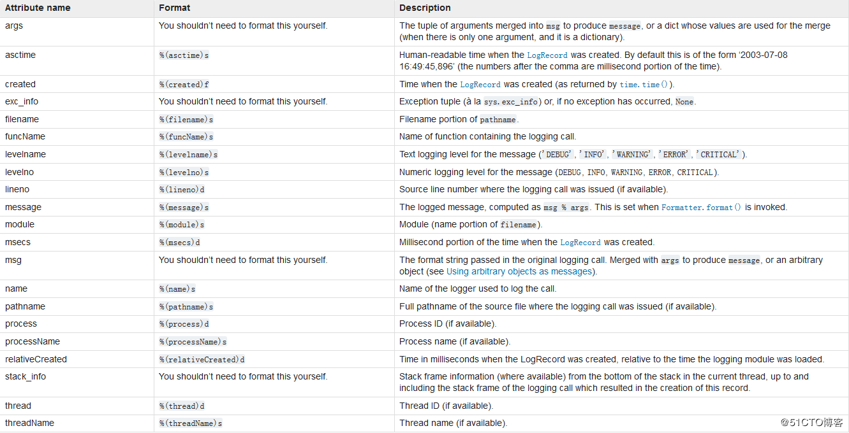
更多日志详细信息请猛击这里
二、json,pickle,shelve
在程序运行时保存数据的一种方法是把所有数据以格式化的方式写入一个简单的文本文件中,只要保存和装载的工具在所选格式上达成一致,我们就可以随心所欲地使用任何自定义格式。
1、pickle
pickle模块将内存中的Python对象转化为序列化的字节流,这是一种可以写入任何类似文件对象的字节串,同时,pickle模块也可以根据序列化的字节流重新构建原来内存中的对象。
转换并写入文件:
import pickle
db = {'name':'Eric Jia','age':'18','job':'ops','pay':200}
dbfile = open('pickle_db','wb')
pickle.dump(db,dbfile)
dbfile.close()从文件中读取数据:
import pickle
dbfile = open('pickle_db','rb')
pickle.load(dbfile)
dbfile.close()直接转换,不写入文件:
import pickle
db = {'name':'Eric Jia','age':'18','job':'ops','pay':200}
a = pickle.dumps(db)
print("a:",a)
b = pickle.loads(a)
print("b:",b)a: b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x08\x00\x00\x00Eric Jiaq\x02X\x03\x00\x00\x00ageq\x03X\x02\x00\x00\x0018q\x04X\x03\x00\x00\x00jobq\x05X\x03\x00\x00\x00opsq\x06X\x03\x00\x00\x00payq\x07K\xc8u.'
b: {'name': 'Eric Jia', 'age': '18', 'job': 'ops', 'pay': 200}2、json
json主要用于python数据类型与字符串之间的转换,用法与pickle一致
1、dump:转换为字符串存入文件
import json
db = {'name':'Eric Jia','age':'18','job':'ops','pay':200}
dbfile = open('json_db','w')
json.dump(db,dbfile)
dbfile.close()
2、load:从文件中取出并转换为Python数据对象
dbfile = open('json_db','r')
json.load(dbfile)
dbfile.close()
3、dumps,loads:直接转换,不写入文件
db = {'name':'Eric Jia','age':'18','job':'ops','pay':200}
a = json.dumps(db)
print(a)
b = json.loads(a)
print(b)3、shalve
pickle和json可以将python数据类型持久存储,假如你的文件系统可以处理任意多需要的文件,每个文件都是一个单独的pickle文件,这样可以避免修改一条记录时都要重新载入和存储整个数据库,这就需要将每个pickle文件名当作字典的键来存储,通过键值来访问数据,Python标准库为我们提供了一个名为shelves的模块来做这些事。
创建shelve数据库
N1 = {'name':'Eric Jia','age':'18','job':'ops','pay':200}
N2 = {'name':'Bob smith','age':'28','job':'java','pay':2000}
N3 = {'name':'David','age':'38','job':'go','pay':20000}
import shelve
db = shelve.open('make_db')
db['N1'] = N1
db['N2'] = N2
db['N3'] = N3
db.close()创建出的shelve数据库如下
重新打开shelve并通过键来取得数据
import shelve
db = shelve.open('make_db')
for key in db:
print(key,"=>",db[key])
db.close()
输出:
N1 => {'name': 'Eric Jia', 'age': '18', 'job': 'ops', 'pay': 200}
N2 => {'name': 'Bob smith', 'age': '28', 'job': 'java', 'pay': 2000}
N3 => {'name': 'David', 'age': '38', 'job': 'go', 'pay': 20000}小结:
1、shelve内部会使用pickle来序列化和反序列化记录,它的接口像pickle一样简单:与字典相同,只是增加了open和close调用。
2、pickle用于python特有的类型和python的数据类型间进行转换,是python独有的
3、json用于字符串和python数据类型间进行转换,所有程序语言都可用。
三、configparser
configparser模块用于对特定的配置进行操作,它与windows中的ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。在py2中是ConfigParser。configparser类方法:
import configparser
# 创建configparser实例
config = configparser.ConfigParser()
# 读取配置文件
config.read('user.conf')
# 返回配置文件中节序列
config.sections()
# 返回某个项目中的所有键的序列
config.options(section)
# 返回section节中,option的键值
config.get(section,option)
# 添加一个配置文件节点(str)
config.add_section(str)
# 设置section节点中,键名为option的值(val)
config.set(section,option,val)
# 写入配置文件
config.write(obj_file)
# 移除节点
config.remove_section(section)
# 移除键,值
config.remove_option(option,value)借助例子来理解configparser模块的使用
configparser.py文件
import configparser
# 创建configparser实例
config = configparser.ConfigParser()
# 添加51cto配置文件节点
config.add_section("51cto")
config.add_section("service")
# 为51cto节点添加键、值
config.set("51cto","blog","blog.51cto.com")
config.set("51cto","web","www.51cto.com")
config.set("service","mysql","3306")
# 写入51.conf文件
with open('51.conf', 'w') as configfile:
config.write(configfile)
# 读取配置文件
config.read('51.conf')
# 返回配置文件中节序列,键,值
for i in config.sections():
print(i)
for j in config.options(i):
print(j,":",config.get(i,j))
# 移除节点
config.remove_section('service')
with open('51.conf', 'w') as configfile:
config.write(configfile)
# 移除键
config.remove_option('51cto','web')
with open('51.conf', 'w') as configfile:
config.write(configfile)输出配置文件51.conf如下:
[51cto]
blog = blog.51cto.com
web = www.51cto.com更多configparser模块用法猛击这里
四、re
正则表达式是一种小型的、高度专业化的编程语言,在python中,他通过re模块实现。正则表达式模式被编译成一系列的字节码,然后由C编写的匹配引擎执行。字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
常用方法:
1、match:从起始位置开始根据模型去字符串中匹配指定内容,匹配单个,如果字符串与模式不匹配, 则返回 None。
re.match(pattern, string, flags=0)
示例:
import re
m = re.match("\d+","123abc")
if m :print(m.group())2、search:根据模型去字符串中匹配指定内容,匹配单个
re.search(pattern, string, flags=0)
示例:
import re
m = re.search("\d+","abc123abc")
if m :print(m.group())3、group:返回匹配的一个或多个子组
import re
a = "123abc456def"
# group(0):返回匹配到的全部结果
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) # 123abc456
# group(1):返回匹配到的第一组结果
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) # 123
# group(2):返回匹配到的第二组结果
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) # abc
# group(3):返回匹配到的第三组结果
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) # 456
# group(4):当前匹配模式没有第四组,拋IndexError错误
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(4))
##############
Traceback (most recent call last):
File "D:/fullstack/week1/day6/re_modules.py", line 10, in <module>
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(4))
IndexError: no such group
##############
# group(1,2,3):返回三组结果
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1,2,3)) # ('123', 'abc', '456')
# groups():返回匹配到的全部结果
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).groups()) # ('123', 'abc', '456')4、findall:返回字符串中模式的所有非重叠匹配项
re.findall(pattern, string, flags=0)
示例:
import re
a = "123abc456def"
m = re.findall("\d+",a)
if m:print(m)
# ['123', '456']5、finditer:返回迭代器对象,其余与findall返回一致
re.finditer(pattern, string, flags=0)
示例:
import re
a = "123abc456def"
m = re.finditer("\d+",a)
for i in m:print(i.group())
# 123
# 4566、sub:用于替换匹配的字符串
re.sub(pattern, repl, string, count=0, flags=0)
示例:
import re
a = "123abc456def"
m = re.sub("\d+","zxc",a)
print(m)
# zxcabczxcdef7、split:根据指定匹配进行分组
re.split(pattern, string, maxsplit=0, flags=0)
示例:
import re
a = "123abc456def"
m = re.split("\d+",a)
print(m)
# ['', 'abc', 'def']
上一篇: python实现主机批量管理
下一篇: python入门——条件语句、for、w
- H3C基本命令大全
53530
- H3C IRF原理及 配置
40353
- Python exit()函数
34756
- python全系列官方中文文档
30515
- python 获取网卡实时流量
25392
- 1.常用turtle功能函数
25183
- python 获取Linux和Windows硬件信息
23597
- 天天基金网数据接口
18871
- Selenium使用代理IP&无头模式访问网站
15174
- Selenium&Pytesseract模拟登录+验证码识别
14685
- LangGraph Studio可视化
1151°
- LangSmith开发-应用入门
1073°
- LangGraph开发-多轮对话问答机器人
1143°
- LangGraph开发-条件分支/循环图实战
1162°
- LangGraph开发-生态介绍,入门demo实战
1198°
- LangChain-接入12306-HTTP MCP智能体
1353°
- LangChain接入自定义爬虫-MCP工具
1311°
- LangChain接入Filesystem-MCP工具
1286°
- LangChain搭建MCP服务端和客户端流程
1383°
- LangGraph与MCP技术概述
1327°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
