最近发现一些网站,可以解析各大视频网站的vip。仔细想了想,这也算是爬虫呀,爬的是视频数据。
首先选取一个视频网站,我选的是 影视大全 ,然后选择上映不久的电影 “一出好戏” 。
分析页面
我用的是chrome浏览器,F12进入查看。选择NetWork的Doc,发现主体部分的数据是从这个网站获取的。
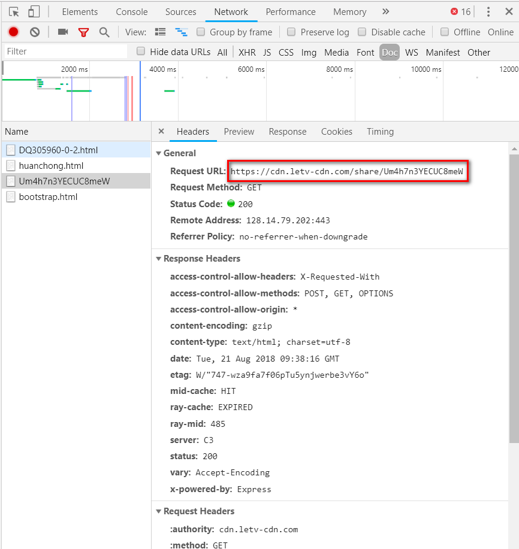
在地址栏输入这个链接,跳转到了视频来源的播放页面。
当然,在这个页面就可以直接观看视频了,但是我们要把视频下载下来。
寻找视频文件
仍然是之前那个页面,在Other中,我们发现了一些奇怪的东西。

查一下,m3u8是个啥东西。
m3u8是苹果公司推出一种视频播放标准,是m3u的一种,不过 编码方式是utf-8,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求。
这下就清楚了,这就是我们要找的东西。
点击Response,查看这个.m3u8的文件。观察发现,.ts后缀的文件地址是有规律的。我们只需要下载所有的.ts后缀文件,然后把它们整合成一个文件即可。
合并.ts文件
命令行:“copy /b F:\f\*.ts E:\f\new.ts”。
执行该命令后,F:\f目录下的全部TS文件就被合并成一个new.ts文件了(你原来的那堆文件仍然存在)。
这里使用copy命令的文件合并功能进行ts文件的合并,copy后面的 /b 参数表示把文件按二进制格式来合并,如果不加这个参数,则会把目标当成文本文件来合并,并在文件内添加不必要的标记,这会导致播放出错,所以必须加 /b 参数。
编写脚本,下载.ts文件
from urllib import request import urllib from time import sleep import socket class CatchVideo(object): def __init__(self): self.headers = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36" self.url = "" def set_url(self, i): if i < 1000: self.url = "https://cdn.letv-cdn.com/20180811/YLDUgCD6/1000kb/hls/DtrOg2412%03d.ts" % i else: self.url = "https://cdn.letv-cdn.com/20180811/YLDUgCD6/1000kb/hls/DtrOg2412%04d.ts" % i # 获取并下载ts文件 def dl_ts(self, i): rq = request.Request(self.url) rq.add_header('User-Agent', self.headers) response = request.urlopen(rq) resread = response.read() with open(str(i)+".ts", "wb") as f: f.write(resread) response.close()# 关闭urlopen方法,防止被ban def start_work(self): for i in range(0, 1563+1): self.set_url(i) try: self.dl_ts(i) print(str(i) + ".ts success") sleep(1) except urllib.error.URLError as e: print(e.reason) break except socket.timeout as e2: print(e2.reason) self.dl_ts(i) if __name__ == '__main__': catch_video = CatchVideo() socket.setdefaulttimeout(20) catch_video.start_work()
运行过程中,出现了两次报错,分别是:
- urllib.error.URLError :[WinError 10054] 远程主机强迫关闭了一个现有的连接
-
socket.timeout read读取超时
解决办法:
1.增加response.close,关闭urlopen方法。
2.增加time.sleep,有一秒缓冲时间
3.设置socket.setdefaulttimeout,给socket预留缓冲时间
还存在问题
实际运行过程中,脚本执行效率略低。之后会加入多线程,继续改进,增加运行效率。
参考博客:
https://blog.csdn.net/a33445621/article/details/80377424
https://blog.csdn.net/illegalname/article/details/77164521
更新代码,加入多进程
修改了start_work方法和主进程:
def start_work(self, i): self.set_url(i) try: self.dl_ts(i) print(str(i) + ".ts success") sleep(1) except urllib.error.URLError as e: print(e.reason) self.dl_ts(i) except socket.timeout as e2: print(e2.reason) self.dl_ts(i) if __name__ == '__main__': catch_video = CatchVideo() socket.setdefaulttimeout(20)# 设置socket层超时时间20秒 I = 0 while I < 1563+1: # 5个进程并发运行 p_l = [Process(target=catch_video.start_work, args=(i,)) for i in range(I, I+5)] for p in p_l: p.start() for p in p_l: p.join() I = I + 5
这里设置了5个进程同时运行,太多远程主机会拒绝请求。
OK,这样就能很快下载了。隔了几天终于想起来还有个电影没看,哈哈 ^_^
