一丶random模块
取随机数的模块
#导入random模块 import random #取随机小数: r = random.random() #取大于零且小于一之间的小数 print(r) #0.7028485217376959 r = random.uniform(1,2) #取大于一且小于二之间的小数 print(r) #1.2376900963409765 #取随机整数 r = random.randint(2,8) #取大于二且小于八之间的整数 print(r) #7 r = random.randrange(2,8,2) #取大于等于二且小于十之间的整数,每两个取一个 print(r) #6 #随机选择一个返回 r = random.choice(["a","123",["dasd"],"das"]) #123 print(r) #随机选择多个返回,返回的个数为函数的第二个参数 r = random.sample(["a","123",["dasd"],"das"],2) #['123', 'a'] print(r) #打乱列表顺序 item = [1,3,5,7,9] r = random.shuffle(item) #只打乱,无返回值 print(r) print(item)
练习题,随机生成大小写数字的验证码


def func(x=6,alpha=True): s = "" for i in range(x): num = str(random.randint(0,9)) if alpha: alpha_upper = chr(random.randint(65,90)) alpha_lower = chr(random.randint(97, 122)) num = random.choice([num,alpha_lower,alpha_upper]) s += num return s print(func(4,alpha=False)) print(func())
二丶time模块
表示时间的三种方式
在python中,通常有这三种方式来表示时间:时间戳,元组(struct_time),格式化的时间字符串:
(1)时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运行"type(time.time())",返回的是float类型.
(2)格式化的时间字符串(Format String): "1999-12-16"
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身 python中时间日期格式化符号:
(3)元组(strict_time):struct_time元组共有9个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,是否是夏令时)
| 索引(index) | 属性(Attribute) | 值(Values) |
| 0 | tm_year(年) | 2018 |
| 1 |
tm_mon(月) |
1-12 |
| 2 | tm_mday(日) | 1-31 |
| 3 | tm_hour(时) | 0-23 |
| 4 | tm_min(分) | 0-59 |
| 5 | tm_sec(秒) | 0-60 |
| 6 | tm_wday(deekday) | 0-6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1-366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
表示时间的几种格式:
#导入时间模块 import time # time.sleep(3) #程序走到这儿会等待3s钟 # 时间戳时间 浮点型数据类型,以s为单位 t = time.time() #1534752249.0591378 print(t) #格式化时间 print(time.strftime("%Y-%m-%d %H:%M:%S")) #strftime = str format time print(time.strftime('%c')) #国外时间格式 # 结构化时间 # 时间元组,localtime将一个时间戳转换成当时时区的struct_time struct_time = time.localtime() # 北京时间 print(struct_time) #time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, # tm_hour=16, tm_min=9, tm_sec=8, tm_wday=0, tm_yday=232, tm_isdst=0)
小结:时间戳是计算机能够识别的时间,时间字符串是人能够看懂的时间,元组则是用来操作时间的
几种格式之间的转换
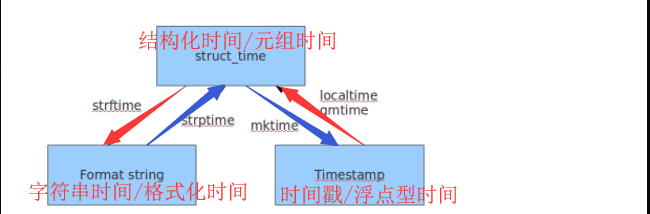
#时间戳时间转换成字符串时间 #获取当前时间戳 t = time.time() print(t) #1534753176.4760094 # 时间戳转换成结构化时间 ti = time.localtime(t) print(ti) #time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, # tm_hour=16, tm_min=19, tm_sec=36, tm_wday=0, tm_yday=232, tm_isdst=0) # 结构化时间转换成字符串时间 sti = time.strftime("%Y-%m-%d %H:%M:%S",ti) print(sti) #2018-08-20 16:22:06 # 字符串时间转换成时间戳时间 t = "2018-08-20 16:22:06" #字符串时间转换成结构化时间 st = time.strptime(t,"%Y-%m-%d %H:%M:%S") print(st) #time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, # tm_hour=16, tm_min=22, tm_sec=6, tm_wday=0, tm_yday=232, tm_isdst=-1) #结构化时间转换成时间戳 ti = time.mktime(st) print(ti) #1534753326.0
练习:
import time ti_old = "2018-8-19 22:10:8" ti_new = "2018-8-20 16:34:3" true_time=time.mktime(time.strptime(ti_old,'%Y-%m-%d %H:%M:%S')) time_now=time.mktime(time.strptime(ti_new,'%Y-%m-%d %H:%M:%S')) dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec)) #过去了0年0月0天18小时23分钟55秒
三丶sys模块
sys模块时与python解释器交互的一个接口
import sys print(sys.argv) #['D:/Learn/day18/1.1.py'] 程序本身的路径 for i in range(0,9): print(i) #0 sys.exit() #遇到sys.exit() 退出程序,正常退出时exit(0),错误退出sys.exit(1) print(sys.version) #获取Python解释程序的版本信息 #3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] print(sys.path) #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 #"C:\Program Files\Python36\python.exe" D:/Learn/day18/1.1.py #['D:\\Learn\\day18', 'D:\\Learn', 'C:\\Program Files\\Python36\\python36.zip', # 'C:\\Program Files\\Python36\\DLLs', 'C:\\Program Files\\Python36\\lib', # 'C:\\Program Files\\Python36', 'C:\\Program Files\\Python36\\lib\\site-packages', # 'E:\\pycharm\\PyCharm 2018.1.3\\helpers\\pycharm_matplotlib_backend'] print(sys.platform) #win32 返回操作系统平台名称
sys.argv登录验证:
# sys.argv 登录验证 import sys name = sys.argv[1] #sys.argv[0]的内容是文件的路径 password = sys.argv[2] # print(sys.argv) if name == 'mark' and password == '123': print('登录成功') else: sys.exit()
在命令行模式下 输入 python + 文件夹的位置 py文件后面可以输入字符串,以空格相隔


四丶os模块
os模块是与操作系统交互的一个接口
import os os.makedirs("name1/name2/name3") #可生成多层递归目录 os.mkdir("name1") #生成单级目录;相当于shell中mkdir dirname os.rmdir("D:/Learn/day18/name1") #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.removedirs("D:/Learn/day18/name1") #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.listdir("D:/Learn/day18/name1") #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove("name1") #删除一个文件 os.rename("oldname","newname") #重命名文件/目录 os.stat('path/filename') #获取文件/目录信息 os.system("bash command") #运行shell命令,直接显示 os.popen("bash command.read()") #运行shell命令,获取执行结果 os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd
# os.path os.path.abspath(path) #返回path规范化的绝对路径 os.path.split(path) #将path分割成目录和文件名 os.path.dirname(path) #返回path的目录,其实就是os.path.split(path)的第一个元素 os.path.basename(path)#返回path最后的文件名.如果path以/或\结尾,那么就会返回空值.即os.path第二个元素 os.path.exists(path) #如果path存在,返回True:如果path不存在,返回False os.path.isabs(path) #如果path是绝对路径,返回True os.path.isfile(path) #如果path是一个存在的文件,返回True.否则返回False os.path.isdir(path) #如果path是一个存在的目录,则返回True,否则返回False os.path.join(path1[,path2[,....]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) #返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) #返回path的大小
五丶 序列化模块
什么叫序列化 -----将原本的字典丶列表等内容转换成一个字符串的过程就叫做序列化
为什么要把其它数据类型转换成字符串呢? 因为能够在网络上传输的只能是bytes,能够存储在文件里的也只有bytes和str
序列化的目的
1.丶以某种存储形式使自定义对象持久化
2丶将对象从一个地方传递到另一个地方
3丶使程序更具维护性.

1丶json
json模块提供了四个功能:dumps丶dump丶loads丶load
dumps和loads是在内存中做数据转换
dumps :将数据类型转成字符串序列化
loads:字符串转成数据类型 反序列化
dump和load是直接将数据类型写入文件,直接从文件中读出数据类型
dump:数据类型写入文件序列化
load :文件读出数据类型 反序列化
import json dic = {'key':'value','key2':'value2'} ret = json.dumps(dic) #序列化,将字典转换成字符串 print(dic,type(dic)) print(ret,type(ret)) #注意,json转换完的字符串类型的字典中的字符串是由""表示的 res = json.loads(ret) #反序列化:将一个字符串格式的字典转换成字典格式 print(res,type(res))
# dump: f = open('json_file','w') dic = {'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) ##dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件 f.close() #load: f = open('json_file') dic2 = json.load(f) f.close() print(type(dic2),dic2)
json在所有语言之间都通用,json序列化的数据在python上序列化了,拿在java中也可以反序列化
能够处理的数据类型是非常有限的"字符串 列表 字典 数字
字典中的key只能是字符串
import json data = {'username':['李华','二愣子'],'sex':'male','age':16} json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False) print(json_dic2) #separators 分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就 # 是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。 #indent 应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示, # 否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json #sort_keys 将数据根据keys的值进行排序 #ensure_ascii 当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时 # 将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。
2.pickle
json和pickle都是用于序列化的两个模块
json用于字符串和python数据类型间进行转换
pickle用于python特有的类型和python的数据类型间进行转换
pickle模块也提供了四个功能:
dumps丶dump(序列化,存)
loads(反序列化,读)
load(不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
import pickle dic = {(1,2,3):{'a','b'},1:'abc'} str_dic = pickle.dumps(dic) print(str_dic) #一串二进制内容 dic2 = pickle.loads(str_dic) print(dic2) #字典{(1, 2, 3): {'a', 'b'}, 1: 'abc'} import time struct_time = time.localtime(1000000000) print(struct_time) #time.struct_time(tm_year=2001,...... f = open('pickle_file','wb') pickle.dump(struct_time,f) f.close() f = open('pickle_file','rb') struct_time2 = pickle.load(f) print(struct_time2.tm_year) #2001
