python3使用cookie免登录爬取
发布时间:2019-09-26 07:25:30编辑:auto阅读(2856)
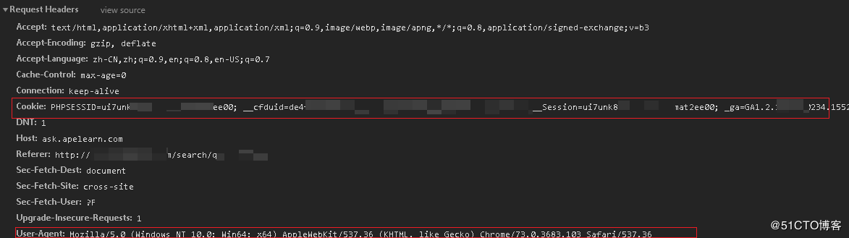
- 使用chrome,登录后在开发工具里查取
前言
由于一些论坛不登录验证,就不能查看帖子的内容和附件,所以需要登录验证,如果在代码中添加登录验证,那就增加了代码的复杂度,所以可以结合cookie来登录然后爬取需要的资料
cookie的获取
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author:Aiker Zhao
@file:jianli.py
@time:下午10:50
"""
import os
import re
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
from hashlib import md5
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Cookie': 'PHPSESSID=ui7unwxc3yf4glbdaqmat2ee00; __cfduid=de4fa38a23ad640f0bcdb4313560af62e1543723208; ape__Session=ui7uxxxxdfd4glbdaqmat2ee00; _ga=GA1.2.176343230234.1552443854'
}
def get_content():
url = 'http://ask.xxxx.com/question/xxxx' # url
response = requests.get(url, headers=headers).text.replace('<i class="fa fa-paperclip"></i>', '')
soup = BeautifulSoup(response, 'lxml')
# div = soup.select('#aw-mod-body ueditor-p-reset')
pattern = re.compile('<a\shref="(http://ask.apelearn.com/file.*?)".*?>(.*?)</a>', re.S)
p = soup.find_all('a')
for item in p:
# print(str(item))
result = re.findall(pattern, str(item))
if result:
# print(result)
for i in result:
url, name = i
# print(i)
yield {
'url': url,
'name': name
}
def download_doc(url, name):
print('正在下载', name, url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
save_doc(response.content, name)
return None
except RequestException:
print('请求文档出错', url)
return None
def save_doc(content, name):
try:
if name:
name_1 = re.sub('[:?!!:?【】]', '', name).split('.')[0] # 替换title中的特殊字符,避免建立文件出错
name_2 = name.split('.')[-1]
dir = 'z:\\jianli2\\'
if os.path.exists(dir):
pass
else:
os.mkdir(dir)
file_path = '{0}/{1}.{2}'.format(dir, name_1 + md5(content).hexdigest(), name_2)
# file_path = '{0}/{1}'.format(dir, name)
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
except OSError:
pass
def main():
# get_content()
for f in get_content():
url = f.get('url')
name = f.get('name')
download_doc(url, name)
if __name__ == '__main__':
main()
运行脚本
上一篇: 详解linux下安装python3环境
下一篇: Python3并发检验代理池地址
- H3C基本命令大全
53430
- H3C IRF原理及 配置
40271
- Python exit()函数
34670
- python全系列官方中文文档
30417
- python 获取网卡实时流量
25306
- 1.常用turtle功能函数
25097
- python 获取Linux和Windows硬件信息
23503
- 天天基金网数据接口
18033
- Selenium使用代理IP&无头模式访问网站
15089
- Selenium&Pytesseract模拟登录+验证码识别
14606
- LangGraph Studio可视化
1039°
- LangSmith开发-应用入门
977°
- LangGraph开发-多轮对话问答机器人
1039°
- LangGraph开发-条件分支/循环图实战
1048°
- LangGraph开发-生态介绍,入门demo实战
1085°
- LangChain-接入12306-HTTP MCP智能体
1237°
- LangChain接入自定义爬虫-MCP工具
1210°
- LangChain接入Filesystem-MCP工具
1185°
- LangChain搭建MCP服务端和客户端流程
1277°
- LangGraph与MCP技术概述
1211°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
