Python3网络爬虫实战-2、请求库安
发布时间:2019-09-24 08:34:21编辑:auto阅读(2742)
- GitHub:https://github.com/mozilla/ge...
- 下载地址:https://github.com/mozilla/ge...
- 官方网站:http://phantomjs.org
- 官方文档:http://phantomjs.org/quick-st...
- 下载地址:http://phantomjs.org/download...
- API接口说明:http://phantomjs.org/api/comm...
- 官方文档:http://aiohttp.readthedocs.io...
- GitHub:https://github.com/aio-libs/a...
- PyPi:https://pypi.python.org/pypi/...
1.1.4 GeckoDriver的安装
在上一节我们了解了 ChromeDriver 的配置方法,配置完成之后我们便可以用 Selenium 来驱动 Chrome 浏览器来做相应网页的抓取。
那么对于 Firefox 来说,也可以使用同样的方式完成 Selenium 的对接,这时需要安装另一个驱动 GeckoDriver。
本节来介绍一下 GeckoDriver 的安装过程。
1. 相关链接
2. MAC安装方式
brew install GeckoDriver
3. 验证安装
配置完成之后,就可以在命令行下直接执行 geckodriver 命令测试。
命令行下输入:
geckodriver
这时控制台应该有类似输出,如图 1-20 所示:
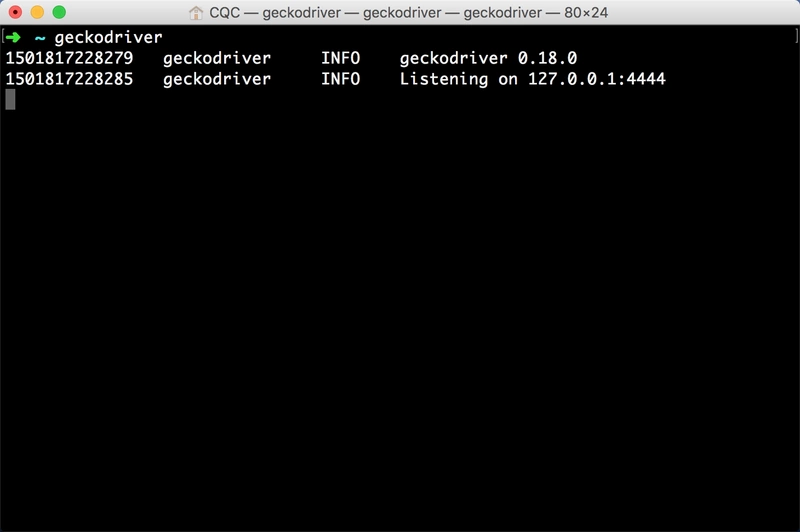
图 1-20 控制台输出
如果有类似输出则证明 GeckoDriver 的环境变量配置好了。
随后再在程序中测试,执行如下 Python 代码:
from selenium import webdriver
browser = webdriver.Firefox()
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎运行之后会弹出一个空白的 Firefox 浏览器,证明所有的配置都没有问题,如果没有弹出,请检查之前的每一步的配置。
如果没有问题,接下来我们就可以利用 Firefox 配合 Selenium 来做网页抓取了。
4. 结语
到现在位置我们就可以使用 Chrome 或 Firefox 进行网页抓取了,但是这样可能有个不方便之处,因为程序运行过程中需要一直开着浏览器,在爬取网页的过程中浏览器可能一直动来动去,着实不方便。目前最新的 Chrome 浏览器版本已经支持了×××面模式,但如果版本较旧就不支持。所以在这里还有另一种方便的选择就是安装一个×××面浏览器 PhantomJS,抓取过程会在后台运行,不会再有窗口出现,这样就方便了很多,所以在下一节我们再了解一下 PhantomJS 的相关安装方法。
1.1.5 PhantomJS的安装
如果我们使用 Chrome 或 Firefox 进行网页抓取的话,每次抓取的时候,都会弹出一个浏览器,比较影响使用。所以在这里再介绍一个×××面浏览器,叫做 PhantomJS。
PhantomJS 是一个×××面的,可脚本编程的 WebKit 浏览器引擎。它原生支持多种 web 标准:DOM 操作,CSS 选择器,JSON,Canvas 以及 SVG。
Selenium 支持 PhantomJS,这样在运行的时候就不会再弹出一个浏览器了,而且其运行效率也是很高的,还支持各种参数配置,使用非常方便,下面我们就来了解一下 PhantomJS 的安装过程。
1. 相关链接
2. MAC安装
brew cask install phantomjs3. 验证安装
在 Selenium 中使用的话,我们只需要将 Chrome 切换为 PhantomJS 即可。
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get('https://www.baidu.com')
print(browser.current_url)运行之后我们就不会发现有浏览器弹出了,但实际上 PhantomJS 已经运行起来了,在这里我们访问了百度,然后将当前的 URL 打印出来。
控制台输出如下:
https://www.baidu.com/如此一来我们便完成了 PhantomJS 的配置,在后面我们可以利用它来完成一些页面的抓取。
4. 结语
以上三节我们介绍了 Selenium 对应的三大主流浏览器的对接方式,在后文我们会对 Selenium 及各个浏览器的对接方法进行更加深入的探究。
1.1.6 Aiohttp的安装
之前我们介绍的 Requests 库是一个阻塞式 HTTP 请求库,当我们发出一个请求后,程序会一直等待服务器的响应,直到得到响应后程序才会进行下一步的处理,其实这个过程是比较耗费资源的。如果程序可以在这个等待过程中做一些其他的事情,如进行请求的调度、响应的处理等等,那么爬取效率一定会大大提高。
Aiohttp 就是这样一个提供异步 Web 服务的库,从 Python3.5 版本开始,Python 中加入了 async/await 关键字,使得回调的写法更加直观和人性化,Aiohttp的异步操作借助于 async/await 关键字写法变得更加简洁,架构更加清晰。使用异步请求库来进行数据抓取会大大提高效率,下面我们来看一下这个库的安装方法。
1. 相关链接
2. 安装
推荐使用 Pip 安装,命令如下:
pip3 install aiohttp另外官方还推荐安装如下两个库,一个是字符编码检测库 cchardet,另一个是加速 DNS 解析库 aiodns,安装命令如下:
pip3 install cchardet aiodns3. 测试安装
安装完成之后,可以在 Python 命令行下测试。
$ python3
>>> import aiohttp
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎如果没有错误报出,则证明库已经安装好了。
4. 结语
我们会在后面的实例中用到这个库,比如维护一个代理池,利用异步方式检测大量代理的运行状况,极大提高效率。
上一篇: Python3网络爬虫实战-8、APP爬
下一篇: Python3网络爬虫实战-4、存储库的
- H3C基本命令大全
53430
- H3C IRF原理及 配置
40272
- Python exit()函数
34671
- python全系列官方中文文档
30418
- python 获取网卡实时流量
25306
- 1.常用turtle功能函数
25099
- python 获取Linux和Windows硬件信息
23504
- 天天基金网数据接口
18052
- Selenium使用代理IP&无头模式访问网站
15089
- Selenium&Pytesseract模拟登录+验证码识别
14606
- LangGraph Studio可视化
1040°
- LangSmith开发-应用入门
978°
- LangGraph开发-多轮对话问答机器人
1040°
- LangGraph开发-条件分支/循环图实战
1048°
- LangGraph开发-生态介绍,入门demo实战
1087°
- LangChain-接入12306-HTTP MCP智能体
1237°
- LangChain接入自定义爬虫-MCP工具
1210°
- LangChain接入Filesystem-MCP工具
1185°
- LangChain搭建MCP服务端和客户端流程
1277°
- LangGraph与MCP技术概述
1211°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
