python线程基础
发布时间:2019-09-20 07:36:53编辑:auto阅读(2382)
一 基本概念
1 并行和并发
1 并行,parallel
同时做某些事,可以互不干扰的同一时刻做几件事
如高速公路上的车道,同一时刻,可以有多个互不干扰的车运行
在同一时刻,每条车道上可能同时有车辆在跑,是同时发生的概念
2 并发,concurrency
也是同时做某事,但强调的是同一时段做了几件事。
并行是可以解决并发问题的。
2 并发的解决
1 队列,缓冲区
队列:排队就是队列,先进先出,解决了资源使用的问题。
缓冲区:排程的队列,其实就是一个缓冲地带,就是缓冲区
优先队列:对比较重要的事进行及时的处理,此处就是优先队列
2 争抢
只开一个窗口,有可能没秩序,也就是谁挤进去就给谁打饭
挤到窗口的人占据窗口,直到达到饭菜离开,其他人继续争抢,会有一个人占据窗口,可以视为锁定窗口,窗口就不能为其他人提供服务了,这是一种锁机制,抢到资源就上锁,排他性锁,其他人只能等候争抢也是一种高并发解决方案,但是,不好,因为有人可能长时间抢不到。
3 预处理
一种提前加载用户需要的数据的思路,如预热,预加载等,缓存中常用
缓存的思想就是将数据直接拿到,进行处理。
4 并行
可通过购买更多的服务器,或开多线程,进行实现并行处理,来解决并发问题,这些都是水平扩展,
5 提速
提高单个CPU性能,或者单个服务器安装更多的CPU,但此和多个服务器相比成本较高
6 消息中间件
通过中间的缓冲器来解决并发问题,如rabbitmq,activemq,rocketmq,kafka 等,CDN也算是一种
3 进程和线程概念
1 进程和线程
在实现了线程的操作系统中,线程是操作系统能够运算调度的最小单位,他被包含在进程中,是进程中的实际运作单位,一个程序的执行实例就是一个进程
进程(process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础
2 进程和线程的关系
程序是源代码编译后的文件,而这些文件存放在磁盘上,当程序被操作系统加载到内存中,就是进程,进程中存放着指令和数据(资源),它也是线程的容器。
Linux进程有父进程,子进程,windows中进程之间是平等关系
线程有时候被称为轻量级进程(LWP),是程序执行的最小单元,一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成
3 进程,线程的理解
现代操作系统提出进程的概念,每一个进程都认为自己独占所有计算机硬件资源,进程就是独立王国,进程间不能随便共享数据
线程就是省份,同一个进程内的线程可以共享进程的资源,每一个线程拥有自己独立的堆栈。
4 python中的进程和线程
进程会启动一个解释器进程,线程共享一个解释器进程
两个解释器进程之间是没有任何关系的,不同进程之间是不能随便交互数据的
大多数数据都是跑在主线程上的
4 线程的状态
1 概述
1 运行态: 该时刻,该线程正在占用CPU资源
2 就绪态:可随时转换成运行态,因为其他线程正在运行而暂停,该线程不占CPU
3 阻塞态: 除非外部某些事情发生,否则线程不能运行
4 终止: 线程完成,或退出,或被取消
2 线程状态转换
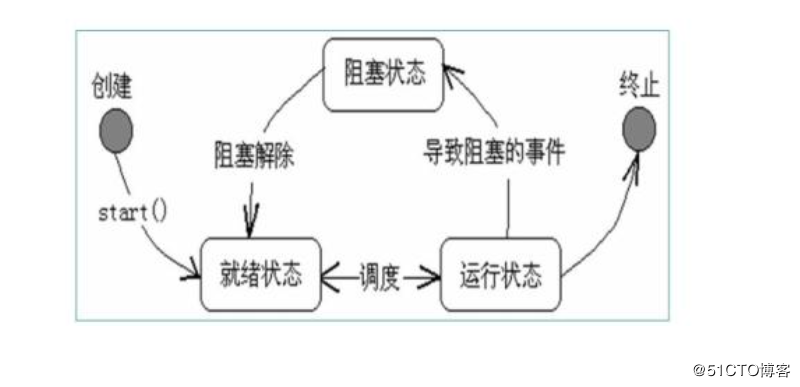
先创建进程,然后再创建一个线程
等待资源的运行
阻塞不能直接进入运行状态,必须先进入就绪状态
运行中的线程是可以被取消的
二 python线程开发
1 Thread类
签名
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):参数名及含义:
target:线程调用的对象,就是目标函数
name:为线程起名字(不同线程的名字可以重复,主要是通过线程TID进行区分的)
args:为目标函数传递参数,元祖
kwargs: 为目标函数关键字传参,字典
2 实例
1 基本创建
实例如下
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def test():
for i in range(5):
print (i)
print ('Thread over')
# 实例化一个线程
t=threading.Thread(target=test)
t.start() # 启动一个线程
随着函数的执行完成,线程也就结束了,子线程不结束,则主线程一直存在,此时的主线程是等待状态
通过threading.Thread创建一个线程对象,target是目标函数,name可以指定名称,但是线程没有启动,需要调用start方法。
线程之所以能执行函数,是因为线程中就是执行代码,而最简单的封装就是哈函数,所以还是函数调用。
函数执行完成,线程就退出了,如果不让线程退出,则需要使用死循环
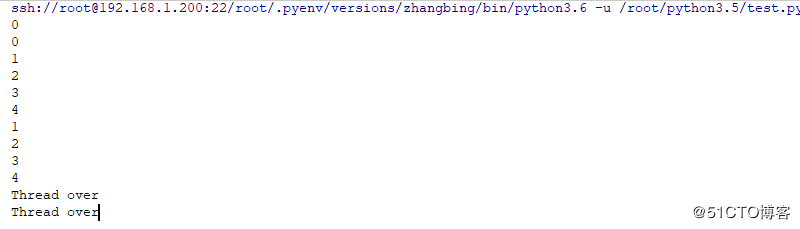
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def test():
for i in range(5):
print (i)
print ('Thread over')
# 实例化一个线程
t=threading.Thread(target=test,name='test1')
t.start() # 启动一个线程
t=threading.Thread(target=test,name='test2')
t.start() # 启动一个线程
# 上述两个线程是并行处理,如果是一个CPU,则是假的平衡结果如下
2 线程退出
python中没有提供线程退出的方式,线程在下面情况时退出、
1 线程函数内语句执行完毕
2 线程函数中抛出未处理的异常
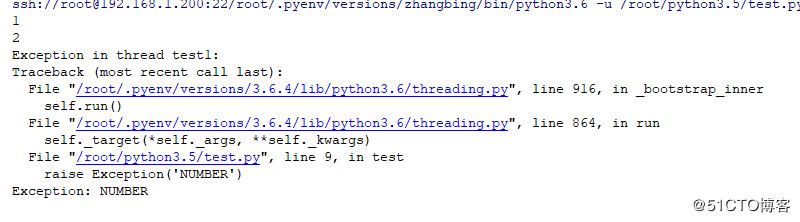
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def test():
count=0
while True:
count+=1
if count==3:
raise Exception('NUMBER')
print (count)
# 实例化一个线程
t=threading.Thread(target=test,name='test1')
t.start() # 启动一个线程异常导致的线程退出
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test():
count=0
while True:
count+=1
if count==3:
raise Exception('NUMBER')
print (count)
def test1():
for i in range(5):
time.sleep(0.1)
print ('test1',i)
# 实例化一个线程
t=threading.Thread(target=test,name='test')
t.start() # 启动一个线程
t=threading.Thread(target=test1,name='test1') #此处启用一个线程,看上述线程能否影响该线程的运行情况
t.start()结果如下
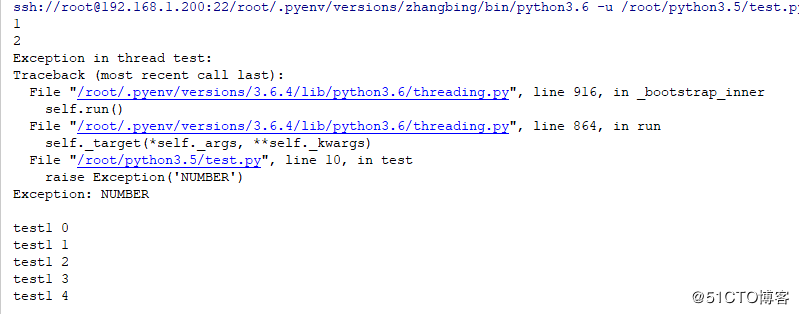
python中线程没有优先级,没有线程组的概念,也不能被销毁,停止,挂起,也就没有恢复,中断了,上述的一个线程的异常不能影响另一个线程的运行,另一个线程的运行是因为其函数运行完成了
3 线程传参
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test(count):
while True:
count+=1
if count==5:
raise Exception('NUMBER')
print (count)
# 实例化一个线程
t=threading.Thread(target=test,name='test',args=(0,)) #此处必须是元祖类型,否则会报错
t.start() # 启动一个线程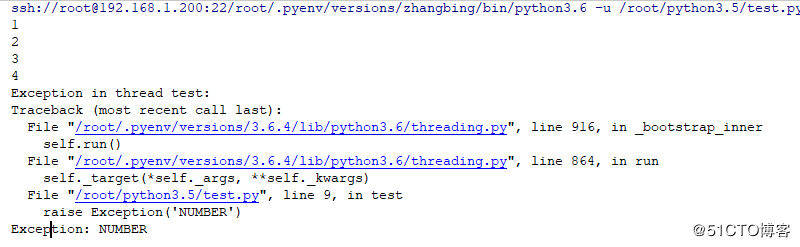
4 线程相关属性
current_thread() 返回当前线程对象
main_thread() 返回主线程对象
active_count() 当前处于alive状态的线程个数
enumerate() 返回所有活着的线程的列表,不包括已经终止的线程和未开始的线程
get_ident() 返回当前线程的ID,非0整数
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test(count):
while True:
print ("当前线程对象为{}当前处于活动的线程个数为{}".format(threading.current_thread(),threading.active_count()))
count+=1
if count==5:
break
print (count)
print('当前活着的线程列表为:', threading.enumerate())
# 实例化一个线程
t=threading.Thread(target=test,name='test',args=(0,)) #此处必须是元祖类型,否则会报错
t.start() # 启动一个线程
print ('当前活着的线程列表为:',threading.enumerate())
print ('当前处于活动的线程个数为{} ,当前主线程为{},当前线程ID为{}'.format(threading.active_count(),threading.main_thread(),threading.get_ident()))
结果如下
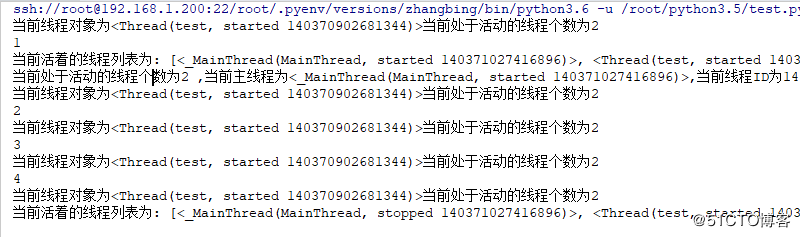
其线程的执行不是顺序的,其调用取决于CPU的调度规则,而主线程在子线程所有子线程退出之前都是active状态。
5 线程实例的属性和方法(getname和setname)
name : 线程的名字,只是一个标识,其可以重名,getname() 获取,setname()设置这个名词
ident:线程ID,其是非0整数,线程启动后才会有ID,否则为None,线程退出,此ID依旧可以访问,此ID可以重复使用
is_alive() 返回线程是否活着
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test(count):
while True:
count+=1
if count==5:
break
print (count)
print ('当前线程name 为{},ID 为{}'.format(threading.current_thread().name,threading.current_thread().ident))
# 实例化一个线程
t=threading.Thread(target=test,name='test',args=(0,)) #此处必须是元祖类型,否则会报错
t.start() # 启动一个线程
print ('主线程状态',threading.main_thread().is_alive())
print ('线程状态',threading.current_thread().is_alive())结果如下

3 start 和run 的区别与联系
1 基本概述
start() 启动线程,每一个线程必须且只能被执行一次
run() 运行线程函数
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('本线程ID为{},主线程ID为{}'.format(threading.current_thread().ident,threading.main_thread().ident))
print ('test')
t=MyThread(target=work,name='w')
t.start()结果如下

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('本线程ID为{},主线程ID为{}'.format(threading.current_thread().ident,threading.main_thread().ident))
print ('test')
t=MyThread(target=work,name='w')
t.run()
结果如下

结论如下:start 方法的调用会产生新的线程,而run的调用是在主线程中运行的,且run的调用只会调用自己的方法,而start 会调用自己和run方法
2 run 和 start 调用次数问题
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
time.sleep(3)
t.start() #再次启用线程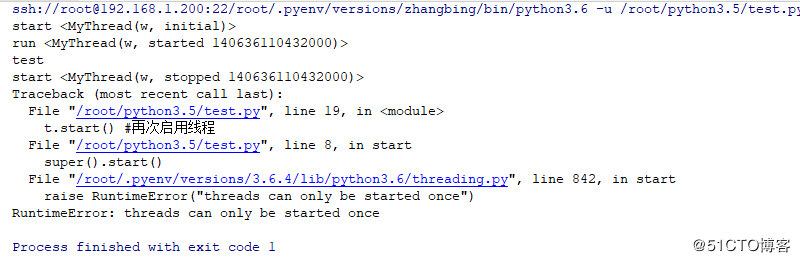
上述可知,线程在start是会调用start和run属性运行,且其不能再次启动线程一次。
调用run方法
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.run()
time.sleep(3)
t.run()结果如下
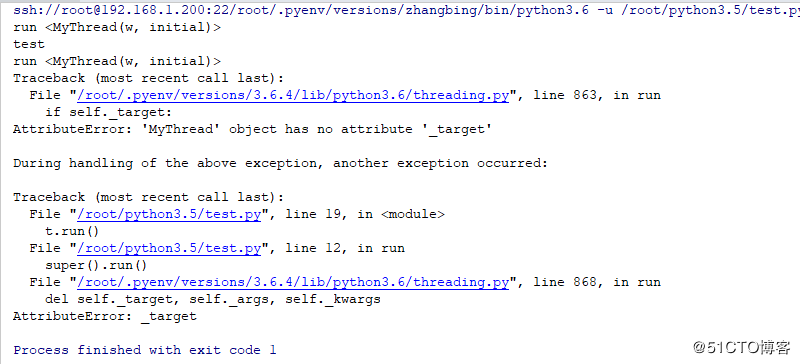
run 方法也只能调用一次
3 start和run 合用
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.run()
time.sleep(3)
t.start()结果如下
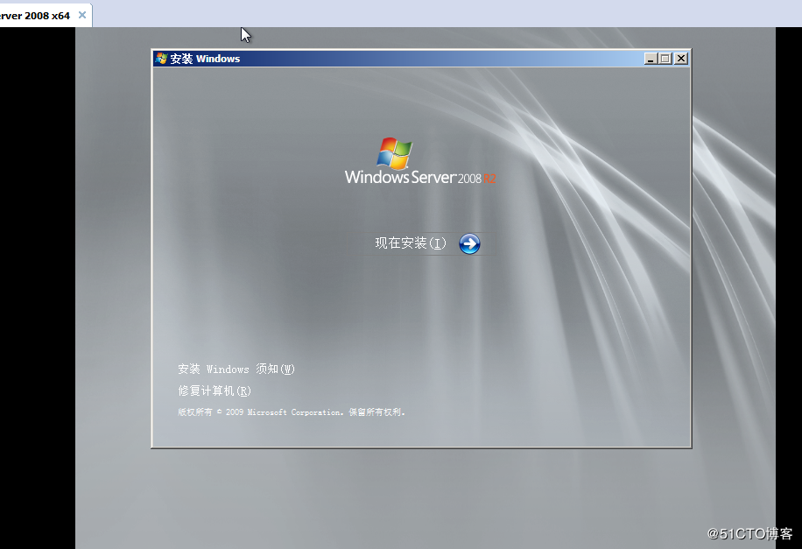
上述结果表明,run和start的调用不能出现在同一个线程中
4 解决同一代码中调用问题
重新构建一个新线程并启动
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
t=MyThread(target=work,name='w1')
t.start()结果如下

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.run()
t=MyThread(target=work,name='w1')
t.run()结果如下

5 run 和start 的作用
注释继承的run方法
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
# super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
t=MyThread(target=work,name='w1')
t.start()结果如下

禁用start方法
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # 自定义一个类,其继承Thread的相关start和run属性
def start(self) -> None:
print ('start',self)
#super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
t=MyThread(target=work,name='w1')
t.start()
结论:start()函数会调用run函数,而run()函数是用来运行函数的,start是创建线程的,在执行start()时run()必不可少,而在运行run()时因为不需要调用start(),因此其是非必须的。
start 会启用新的线程,其使用可以形成多线程,而run()是在当前线程中调用函数,不会产生新的线程,其均不能多次调用
4 多线程概述
一个进程中如果有多个线程,就是多线程,实现一种并发
线程的调度任务是操作系统完成的
没有开新的线程,这就是普通的函数调用,所以执行完t1.run(),然后执行t2.run(),这不是多线程
当使用start方法启动线程时,进程内有多个活动的线程并行工作,就是多线程
一个进程中至少有一个线程,作为程序的入口,这个线程就是主线程,一个进程至少有一个主线程
其他线程称为工作线程
python中的线程没有优先级的概念
5 线程安全
1 问题
此实例需要在ipython 中运行
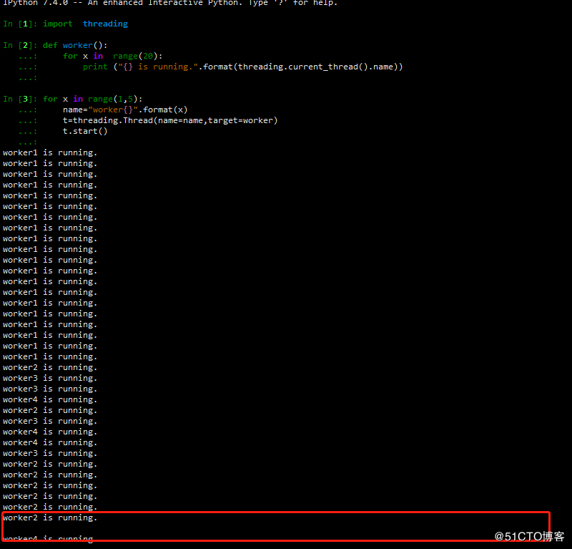
此处的print 会被打断,其中间有空格,此种情况称为线程不安全。
print 函数的执行分为两步:
1 打印字符串
2 换行,就在这之间发生了线程切换,其不安全
2 解决方式:
1 通过字符串的拼接来完成
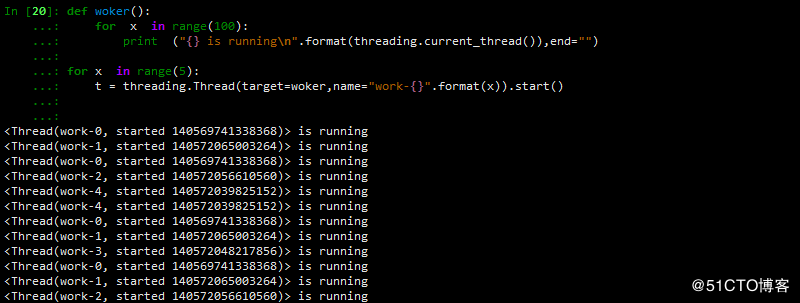
2 通过logging模块来处理,其输出过程中是不被打断的
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # 导入日志打印模块
logging.basicConfig(level=logging.INFO) #定义基本级别,默认是WARNING,此处修改为INFO
def woker():
for x in range(10):
msg="{} is running".format(threading.current_thread())
logging.info(msg) # 日志打印
for x in range(5):
t = threading.Thread(target=woker,name="work-{}".format(x)).start()结果如下
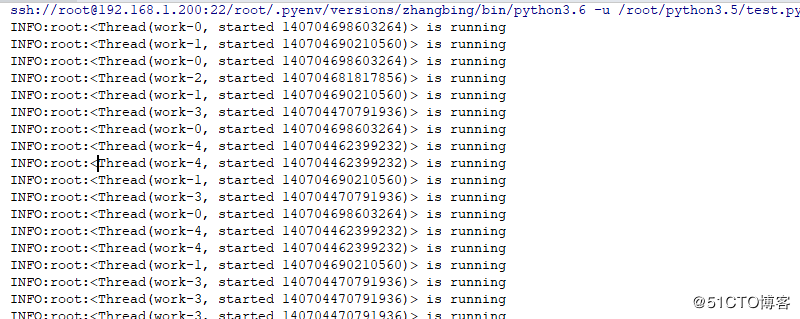
简单测试的时候使用print,在其他应用的时候必须使用logging,其是针对日志打印使用的技术,日志打印过程中是不能被中断的,
6 daemon 线程和 non-daemon线程
1 概述
这里的daemon线程不是Linux中的守护进程
进程靠线程执行代码,至少一个主线程,其他线程是工作线程
主线程是第一个启动的线程
父线程: 如果线程A中启动了一个线程B,A就是B的父线程
子线程: B就是A的子线程在python中,构建线程的时候,可以设置daemon属性,这个属性必须在start方法之前设置好,
相关源码

此处表明。若传入的daemon 不是None,则其表示默认传入的值,否则,及若不传入,则表示使用当前线程的daemon
主线程是non-daemon线程,及daemon=False
活着线程的列表的源码

此处表示活着的线程列表中一定会包含主线程,
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # 导入日志打印模块
logging.basicConfig(level=logging.INFO) #定义基本级别,默认是WARNING,此处修改为INFO
def woker():
for x in range(10):
msg="{} is running".format(threading.current_thread())
logging.info(msg) # 日志打印
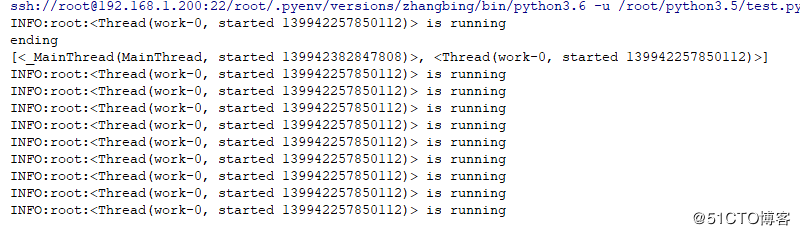
threading.Thread(target=woker,name="work-{}".format(0)).start()
print ('ending')
print (threading.enumerate()) #主线程因为其他线程的执行,因此其处于等待状态结果如下
2 daemon线程
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # 导入日志打印模块
logging.basicConfig(level=logging.INFO) #定义基本级别,默认是WARNING,此处修改为INFO
def woker():
for x in range(10):
msg="{} is running".format(threading.current_thread())
logging.info(msg) # 日志打印
threading.Thread(target=woker,name="work-{}".format(0),daemon=True).start() #主线程一般会在一定时间内扫描属性列表,若其中有non-daemon类型
# 的线程,则会等待其执行完成再退出,若是遇见都是daemon类型线程,则直接退出,
print ('ending')
print (threading.enumerate()) #主线程因为其他线程的执行,因此其处于等待状态结果如下

上述线程是daemon线程,因此主线程不会等待其完成后再关闭
3 non-daemon 和 damon
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # 导入日志打印模块
import time
logging.basicConfig(level=logging.INFO) #定义基本级别,默认是WARNING,此处修改为INFO
def woker():
for x in range(10):
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # 日志打印
time.sleep(0.5) #此处配置延迟,检验是否在non-daemon线程执行完成后及会直接关闭的情况
threading.Thread(target=woker,name="work-{}".format(0),daemon=True).start() #主线程一般会在一定时间内扫描属性列表,若其中有non-daemon类型
# 的线程,则会等待其执行完成再退出,若是遇见都是daemon类型线程,则直接退出,、
def woker1():
for x in ['a','b','c','d']:
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # 日志打印
threading.Thread(target=woker1,name="work-{}".format(0)).start() #主线程一般会在一定时间内扫描属性列表,若其中有non-daemon类型,则不会终止,
# 此处默认从父线程中获取属性,父线程中是non-daemon,因此此属性会一直运行,上面的会关闭,但不会影响这个
print ('ending')
print (threading.enumerate()) #主线程因为其他线程的执行,因此其处于等待状态结果如下

结果表示,当non-daemon线程执行完成后,不管damon是否执行完成,主线程将直接终止,不会再次运行。
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # 导入日志打印模块
import time
def woker1():
for x in ['a','b','c','d']:
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # 日志打印
logging.basicConfig(level=logging.INFO) #定义基本级别,默认是WARNING,此处修改为INFO
def woker():
for x in range(10):
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # 日志打印
time.sleep(1) # 此处配置1秒延时,使得主线程看不到孙子线程的non-daemon就关闭
T3=threading.Thread(target=woker1,name="woker{}".format(10),daemon=False) #此处启动的线程默认是non-daemon线程,但由于其父线程是daemon
# 及就是下面的T1线程,当T2线程执行完毕后线程扫描,发现没non-daemon线程,则直接退出,此时将不会继续执行T1 的子线程T3,虽然T3是non-daemon。因为其未启动
T3.start()
T1=threading.Thread(target=woker,name="work-{}".format(0),daemon=True)#主线程一般会在一定时间内扫描属性列表,若其中有non-daemon类型
T1.start()
# 的线程,则会等待其执行完成再退出,若是遇见都是daemon类型线程,则直接退出,
T2=threading.Thread(target=woker1,name="work-{}".format(0)) #主线程一般会在一定时间内扫描属性列表,若其中有non-daemon类型,则不会终止,
# 此处默认从父线程中获取属性,父线程中是non-daemon,因此此属性会一直运行,上面的会关闭,但不会影响这个
T2.start()
print ('ending')
print (threading.enumerate()) #主线程因为其他线程的执行,因此其处于等待状态
结果如下

可能孙子线程还没起来,主线程只看到了daemon线程。则直接进行关闭,
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # 导入日志打印模块
import time
def woker1():
for x in ['a','b','c','d']:
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # 日志打印
logging.basicConfig(level=logging.INFO) #定义基本级别,默认是WARNING,此处修改为INFO
def woker():
for x in range(10):
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # 日志打印
# time.sleep(1) # 此处配置1秒延时,使得主线程看不到孙子线程的non-daemon就关闭
T3=threading.Thread(target=woker1,name="woker{}".format(10),daemon=False) #此处启动的线程默认是non-daemon线程,但由于其父线程是daemon
# 及就是下面的T1线程,当T2线程执行完毕后线程扫描,发现没non-daemon线程,则直接退出,此时将不会继续执行T1 的子线程T3,虽然T3是non-daemon。因为其未启动
T3.start()
T1=threading.Thread(target=woker,name="work-{}".format(0),daemon=True)#主线程一般会在一定时间内扫描属性列表,若其中有non-daemon类型
T1.start()
# 的线程,则会等待其执行完成再退出,若是遇见都是daemon类型线程,则直接退出,结果如下
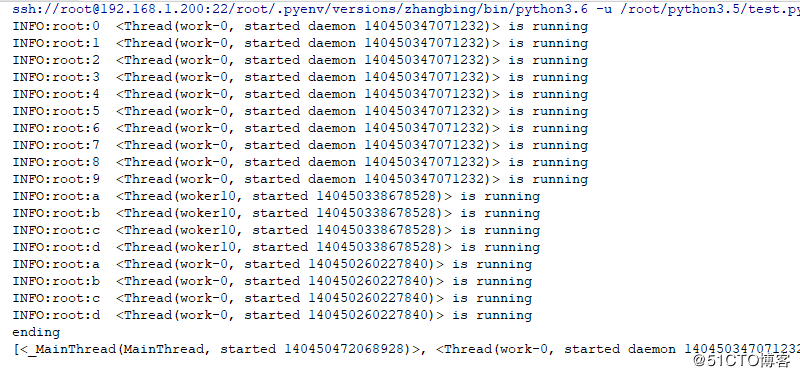
也可能是孙子线程已经起来了,主线程看到了non-daemon线程,因此未直接关闭,而是等待孙子线程执行完成后才进行关闭操作
相关属性
daemon 属性 表示线程是否是daemon线程,这个值必须在start()之前设置,否则会引发异常
isDaemon() 是否是daemon线程
setDaemon() 设置为daemon线程,必须在start方法之前设置
总结:
python中父线程和子线程没有直接的管理关系
python主线程是否杀掉线程,看的是daemon,若只有daemon,则直接删掉所有线程,自己结束,若还有子线程是non-daemon,则会等待
如果想让一个线程完整执行,则需要定义non-daemon属性
daemon 属性,必须在start 之前设置,否则会引发runtimeError异常
线程具有daemon属性,可以显示设置为True或False,也可以不设置,则去默认值None
如果不设置daemon,就区当前线程的daemon来设置它主线程是non-daemon线程,及daemon=False
从主线程创建的所有线程不设置daemon属性,则默认都是daemon=False,也就是non-daemon线程
python程序在没有活着的non-daemon线程运行时推出,也就是剩下的只有daemon线程,主线程才能退出,否则主线程就只能等待。
应用场景:
不关心什么时候开始,什么时候结束的时候使用daemon,否则可以使用non-daemonLinux的daemon是进程级别的,而python的daemon是线程级别的,其之间没有可比性的
daemon和non-daemon 启动的时候,需要注意启动的时机。
简单来说,本来并没有daemon thread,为了简化程序员工作,让他们不去记录和管理那些后台线程,创造了daemon thread 的概念,这个概念唯一的作用就是,当你把一个线程设置为daemon时,它会随着主线程的退出而退出。
主要应用场景:
1 后台任务,发送心跳包,监控,这种场景较多。
2 主线程工作才有用的线程,如主线程中维护了公共资源,主线程已经清理了,准备退出,而工作线程使用这些资源工作也没意义了,一起退出最合适
3 随时可以被终止的线程
7 join
join是标准的线程函数之一,其含义是等待,谁调用join,谁等待
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # 导入日志打印模块
import time
def foo(n):
for i in range(n):
print (i)
time.sleep(0.5)
t1=threading.Thread(target=foo,args=(10,),daemon=True)
t1.start() # 默认情况下,此线程只能执行少量此,一般不能全部执行
t1.join() # 通过join方法将原本不能执行完成的线程执行完成了结果如下
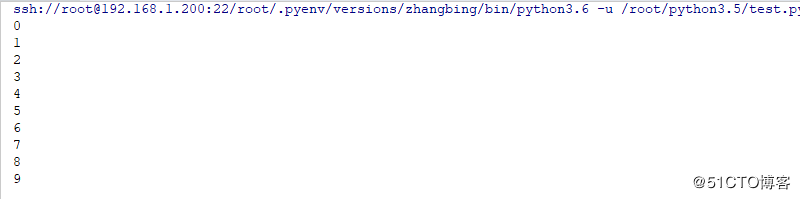
使用join方法,daemon线程执行完成后,主线程才退出,
join(timeout=None),是线程的标准方法之一。
timeout参数指定调用者等待多久,没有设置超时,则就一直等到被调用线程结束,调用谁的join方法,就是join谁,谁就要等待。一个线程中调用另一个线程的join方法,调用者将被阻塞,直到被调用者线程终止,一个线程可以被join多次
如果在一个daemon C 线程中,对另一个daemon线程D 使用了join方法,只能说明C要等待D,主线程退出,C和D是否结束,也不管他们谁等待谁,都要被杀掉。
join 方法,支持使用等待,但其会导致多线程变成单线程,其会影响正常的运行,因此一般会将生成的线程加入到列表中,进行遍历得到对应线程进行计算。
8 threading.local 类
python 提供了threading.local 类,将这个实例化得到一个全局对象,但是不同的线程,这个对象存储的数据其他线程看不到
1 局部变量
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def worker():
x=0 # 此处是局部变量
for i in range(10):
time.sleep(0.0001)
x+=1
print (threading.current_thread(),x)
for i in range(10):
threading.Thread(target=worker).start()结果如下
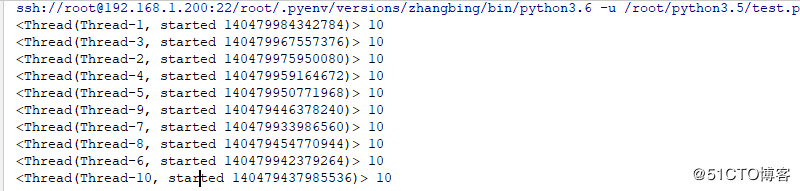
2 全局变量
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
x = 0 # 此处是一个全局变量
def worker():
for i in range(10):
global x
time.sleep(0.0001)
x+=1
print (threading.current_thread(),x)
for i in range(10):
threading.Thread(target=worker).start()结果如下
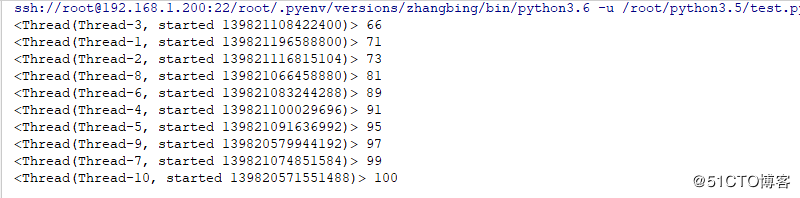
局部变量本身具有隔离效果,一旦变成全局变量,则所有的线程都将能够访问和修改。
3 使用类处理
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class A:
def __init__(self,x):
self.x=x
a=A(0)
def worker():
for i in range(100):
a.x=0
time.sleep(0.0001)
a.x+=1
print (threading.current_thread(),a.x)
for i in range(10):
threading.Thread(target=worker).start()结果如下
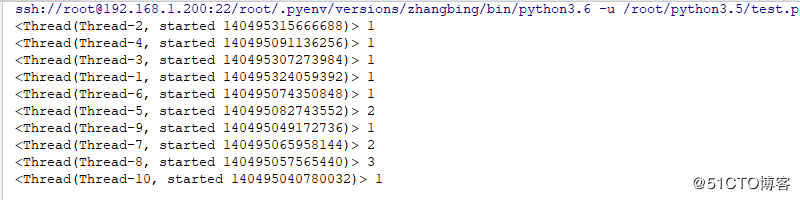
其不同线程的TID是不同的,可通过不同线程的TID进行为键,其结果为值,便可解决此种乱象
4 threading.local
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
a=threading.local() # 做到隔离,通过TID进行数据的隔离处理不同线程的不同数值问题
def worker():
a.x = 0
for i in range(100):
time.sleep(0.0001)
a.x+=1
print (threading.current_thread(),a.x)
for i in range(10):
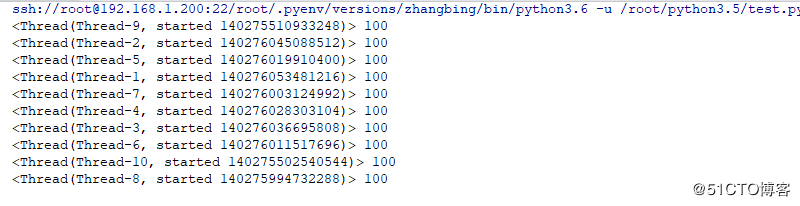
threading.Thread(target=worker).start()结果如下
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
a=threading.local() # 做到隔离,通过TID进行数据的隔离处理不同线程的不同数值问题
def worker():
a.x = 0
for i in range(100):
time.sleep(0.0001)
a.x+=1
print (threading.current_thread(),a.x)
print (threading.get_ident(),a.__dict__) #此处打印线程TID和字典
for i in range(10):
threading.Thread(target=worker).start()结果如下
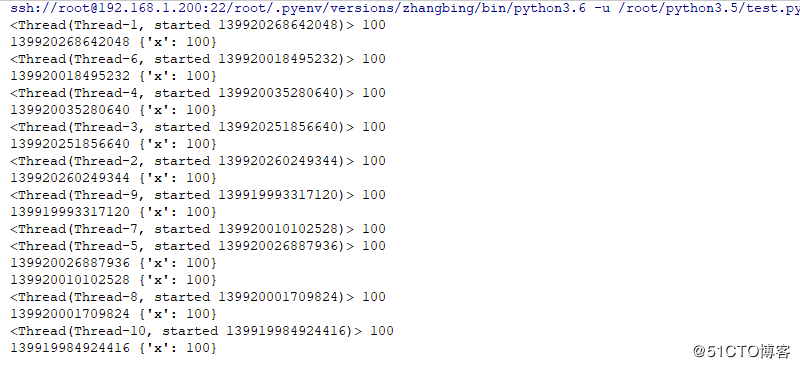
5 源代码

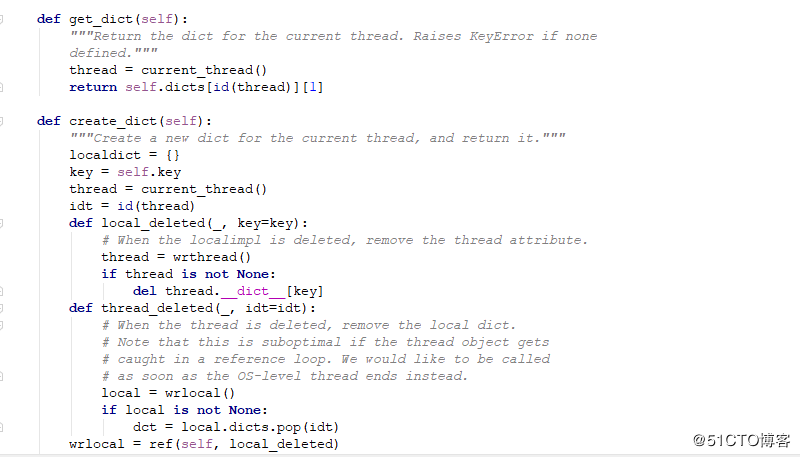
self.key 是 前面的加上id
通过字典实现,线程ID的地址是唯一的,但跨进程的线程ID 不一定是相同的进程中的线程地址可能是一样的。每一个进程都认为自己是独占资源的,但不一定就是 。
6 实践
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
X='abc'
ctx=threading.local()
ctx.x=123
def work():
print (X)
print (ctx)
print (ctx.x) #此时的字典中ctx此ctx.x属性,因此其不能打印,其是在线程内部,每个dict对应的值都是独立的
print ('end')
threading.Thread(target=work).run() # 此处是本地线程调用,则不会影响
threading.Thread(target=work).start()结果如下

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
X='abc'
ctx=threading.local()
ctx.x=123
def work():
print (X)
print (ctx)
ctx.x=100 #内部线程中定义一个局部变量,则可以执行和被调用
print (ctx.x) #此时的ctx 无此属性,因此其不能打印,其是在线程内部,
print ('end')
threading.Thread(target=work).run() # 此处是本地线程调用,则不会影响
threading.Thread(target=work).start()结果如下
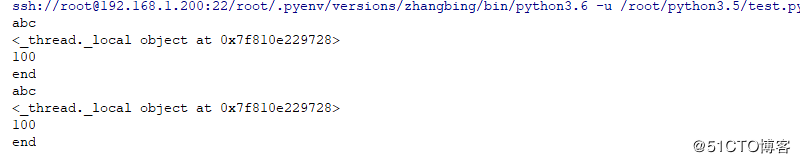
7 结论
threading.local类构件了一个大字典,其元素的每一线程实例的地址为Key和线程的引用线程单独的字典的映射(栈),通过threading.local 实例就可以在不同的线程中,安全的使用线程独有的数据,做到了线程间数据的隔离,如同本地变量一样
8 延迟执行Timter
1 源码
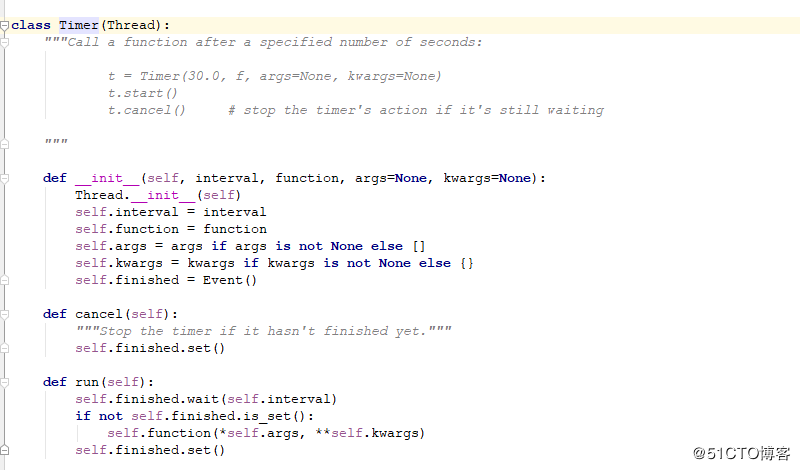
上述可看到,其第一个字段便是时间
2 基本实例
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import datetime
start_time=datetime.datetime.now()
def add(x,y):
print (x+y)
print("函数执行时间为{}".format((datetime.datetime.now() - start_time).total_seconds()))
t=threading.Timer(3,add,args=(3,4))
t.start() #此处会延迟3秒执行结果如下

此处是延迟执行线程,而不是延迟执行函数,本质上还是线程
3 t.cancel() 线程的删除
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import datetime
import time
def add(x,y):
print (x+y)
t=threading.Timer(6,add,args=(3,4)) # 此处表示6秒后出结果
t.start()
time.sleep(5)
t.cancel() #线程被删除只要是没真正执行的线程,都能够被cancel删除

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import datetime
import time
def add(x,y):
time.sleep(5)
print (x+y)
t=threading.Timer(6,add,args=(3,4)) # 此处表示6秒后出结果
t.start()
time.sleep(10)
t.cancel()结果如下 
start方法后,timer对象会处于等待状态,等待interval之后,开始执行function函数,如果在执行函数之前等待阶段,使用了cancel方法,就会跳过执行函数结束。
如果线程已经开始执行了,则cancel就没有任何效果了
4 总结
Timer是线程Thread的子类,就是线程类,具有线程的能力和特征
它的实例是能够延迟执行目标函数的线程,在真正的执行目标函数之前,都可以cancel它 。
上一篇: anaconda python更换清华源
下一篇: python链表
- H3C基本命令大全
53501
- H3C IRF原理及 配置
40328
- Python exit()函数
34735
- python全系列官方中文文档
30485
- python 获取网卡实时流量
25366
- 1.常用turtle功能函数
25158
- python 获取Linux和Windows硬件信息
23572
- 天天基金网数据接口
18823
- Selenium使用代理IP&无头模式访问网站
15146
- Selenium&Pytesseract模拟登录+验证码识别
14660
- LangGraph Studio可视化
1122°
- LangSmith开发-应用入门
1048°
- LangGraph开发-多轮对话问答机器人
1118°
- LangGraph开发-条件分支/循环图实战
1133°
- LangGraph开发-生态介绍,入门demo实战
1166°
- LangChain-接入12306-HTTP MCP智能体
1317°
- LangChain接入自定义爬虫-MCP工具
1281°
- LangChain接入Filesystem-MCP工具
1258°
- LangChain搭建MCP服务端和客户端流程
1357°
- LangGraph与MCP技术概述
1298°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
