利用Python批量保存51CTO博客
发布时间:2019-09-20 07:27:16编辑:auto阅读(2714)
- 程序是用户指定博客的用户名和需要抓取的页码数字,之后爬去所有与的文章标题和对应的url
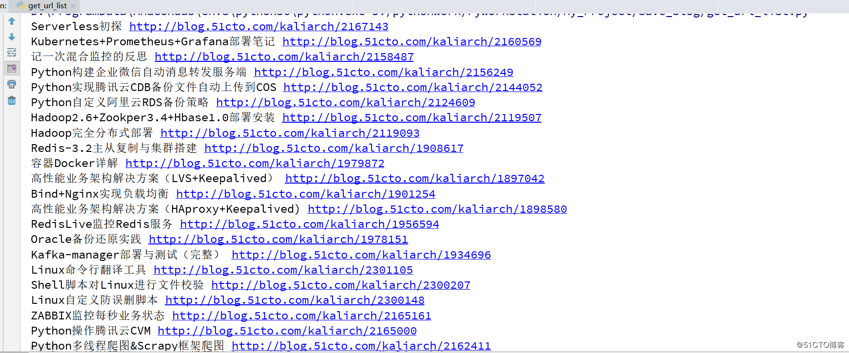
- 后期通过selenium模拟登录,直接请求
https://blog.51cto.com/blogger/publish/文章id可以直接导出markdown写的文件,这个直接导出没办法命名文件很尴尬,但是导出了总归好的,后期可以读文件来给文件命名
- 查看导出的markdown文件
一、背景
最近在整理博客,近在51CTO官网存在文章,想将之前写的全部保存到本地,发现用markdown写的可以导出,富文本的则不行,就想利用Python批量保存自己的博客到本地。
二、代码
#!/bin/env python
# -*- coding:utf-8 -*-
# _auth:kaliarch
import requests
import time
from bs4 import BeautifulSoup
from selenium import webdriver
class BlogSave():
# 定义headers字段
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36"
}
def __init__(self,blog_name,page_number,login_user_name,login_passwd):
self.login_url = 'http://home.51cto.com/index'
# 博客用户名
self.blog_name = blog_name
# 需要保存的博客多少页
self.page_number = page_number
# 登陆的用户
self.login_user_name = login_user_name
# 登陆的密码
self.login_passwd = login_passwd
# 本地的chreomedriver驱动
self.chromedirve = 'D:\chromedriver.exe'
# blog 导入url
self.blog_save_url = 'https://blog.51cto.com/blogger/publish/'
def get_urldict(self):
"""
爬去用户文章的url
:param pagenumber:
:return: urllist
"""
content_dict = {}
scrapy_urllist = ["https://blog.51cto.com/" + str(self.blog_name) + "/p" + str(page) for page in
range(1, int(self.page_number) + 1)]
for scrapy_url in scrapy_urllist:
response = requests.get(scrapy_url, headers=BlogSave.headers)
soup = BeautifulSoup(response.content, 'lxml', from_encoding='utf-8')
title_list = soup.find_all('a', class_='tit')
for content in title_list:
# 获取url
url = content['href']
title_soup = BeautifulSoup(requests.get(url, headers=BlogSave.headers).content, 'lxml', from_encoding='utf-8')
title = title_soup.find_all('h1', class_='artical-title')
# 获取标题
# print(title[0].get_text())
content_dict[title[0].get_text()] = url
print(title[0].get_text(),url)
return content_dict
def save_blog(self,url_list):
"""
通过模拟登陆保存博客文件
:return:
"""
browser = webdriver.Chrome(self.chromedirve)
# 打开url
browser.get(self.login_url)
time.sleep(2)
# 登陆
browser.find_element_by_id('loginform-username').send_keys(self.login_user_name)
browser.find_element_by_id('loginform-password').send_keys(self.login_passwd)
browser.find_element_by_name('login-button').click()
time.sleep(1)
for url in url_list:
browser.get(url)
time.sleep(1)
try:
browser.find_element_by_xpath('//*[@id="blogEditor-box"]/div[1]/a[14]').click()
time.sleep(2)
except Exception as e:
with open('fail.log','a') as f:
f.write(url + str(e))
def run(self):
# 获取标题和url字典
content_dict = self.get_urldict()
# 获取url列表
id_list = []
for value in content_dict.values():
id_list.append(str(value).split('/')[-1])
result_list = [ self.blog_save_url + str(id) for id in id_list ]
print("result_list:",result_list)
self.save_blog(result_list)
if __name__ == '__main__':
# blogOper = BlogSave('kaliarch',1)
# dict = blogOper.get_urldict()
# value_list = [ value for value in dict.values()]
# print(value_list)
blogOper = BlogSave(blog_name='kaliarch',page_number=5,login_user_name='xxxxxxxx@qq.com',login_passwd='xxxxxxxxxxxxx')
blogOper.run()三、测试
上一篇: C++使用boost.python编写P
下一篇: Python 数据处理,切片,替换,去重
- H3C基本命令大全
53501
- H3C IRF原理及 配置
40328
- Python exit()函数
34735
- python全系列官方中文文档
30485
- python 获取网卡实时流量
25366
- 1.常用turtle功能函数
25158
- python 获取Linux和Windows硬件信息
23572
- 天天基金网数据接口
18824
- Selenium使用代理IP&无头模式访问网站
15148
- Selenium&Pytesseract模拟登录+验证码识别
14660
- LangGraph Studio可视化
1122°
- LangSmith开发-应用入门
1048°
- LangGraph开发-多轮对话问答机器人
1118°
- LangGraph开发-条件分支/循环图实战
1133°
- LangGraph开发-生态介绍,入门demo实战
1167°
- LangChain-接入12306-HTTP MCP智能体
1317°
- LangChain接入自定义爬虫-MCP工具
1281°
- LangChain接入Filesystem-MCP工具
1258°
- LangChain搭建MCP服务端和客户端流程
1358°
- LangGraph与MCP技术概述
1299°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
