Python自动化开发学习11-Rabb
发布时间:2019-09-14 09:46:48编辑:auto阅读(2230)
- fanout: 所有bind到此exchange的queue都可以接收消息,就是所有队列都能收(广播)
- direct: 通过routingKey和exchange决定哪个queue可以接收消息,默认就是这个但是还可以再设置
- topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息,就是部分队列可以收
- headers: 通过headers 来决定把消息发给哪些queue,这个号称用的少
RabbitMQ-消息队列
其他主流的MQ还有:ZeroMQ 和 ActiveMQ ,就知道一下好了。
安装RabbitMQ
我是在CentOS7上安装的,直接用yum安装,安装起来就比较简单了。
安装epel源
首先你得有EPEL源,没有的话可以安装一下:
$ yum epel-release安装rabbitmq-server
有了源之后就可以用yum一步安装上RabbitMQ了
$ yum rabbitmq-server好了,这样就安装完了。
其实,rabbitmq是用erlang语言实现的,这里用yum安装,把有依赖关系的erlang也一起安装好了。
启动rabbitmq
启动rabbitmq服务:
$ systemctl start rabbitmq-server如果你还想开启自动启动,就再enable一下。如果就是玩一下的话,每次开机自己手动start一下也行,就不要enable了。
$ systemctl enable rabbitmq-server开放防火墙端口
首先会用到5672端口,就先开放一下5672端口,如下
$ firewall-cmd --permanent --add-port=5672/tcp
$ firewall-cmd --reload安装第三方模块
最后我们还要在python上安装一个pika模块
好了所有准备工作算是完成了
准备开始学习
上面都是准备工作,现在可以开始了。
这里是官网:http://www.rabbitmq.com/getstarted.html
这个页面里有6个上手的例子和说明,下面就是把这6个例子拿来练练手,熟练使用方法。
简单的队列通信
官网上的 1 "Hello World!"
先写一个send端:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.3.108')) # 建立连接
channel = connection.channel() # 声明一个管道
channel.queue_declare(queue='hello') # 声明一个队列
# 下面一句就是发消息了
# exchange:暂时不知道
# routing_key:你的队列的名字
# body:你的消息的内容
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print("Send: 'Hello World!'") # 本地打印一下
connection.close() # 关闭,关闭队列就好了,管道不用关闭
# 关闭同时主要还是为了刷新缓冲区,把消息真正的传递给RabbitMQ然后是recv端:
import pika
# 建立连接、管道、队列,和send端一样
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.3.108'))
channel = connection.channel()
# 声明队列,只要声明一次就好了,之前send端也声明过了,但是重复声明并没有问题
# 不声明也没有关系,只要你确认这个队列已经声明过了
# 但是,我们并不确定之前是否声明了队列,所以每次都声明一下才是好的做法
channel.queue_declare(queue='hello')
# 准备一个回调函数,下面是一个标准的声明回调函数的格式,带4个参数
def callback(ch, method, properties, body):
print(ch) # 管道,就是channel
print(method) # 一般不用,不过能看到send端的basic_publish里的信息
print(properties) # 暂时不知道,后面会讲
print("Recv: %r" % body) # 注意,收到的是bytes格式
# 声明接收消息的语法,并没有开始收
# 声明回调函数,如果收到消息,就调用这个函数
# 从哪个队列里收消息
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print('等待接收消息,按 CTRL+C 退出')
# 这里开始持续接收消息,没有消息就阻塞
channel.start_consuming()send端是执行一次就发一条消息然后结束。
recv端看最后一句 channel.start_consuming() ,一旦start就会持续接收消息,已有消息就会调用回调函数,这里我们会把消息打印出来。
如果send端没有打开,则recv会一直阻塞等待消息。如果recv端没有打开,每次send的消息都会存在服务器上,直到有recv端接入接收消息。
消息分发轮训
还是上面的send端和recv端,试着开启多个recv端。查看send端发送的消息被哪个recv端接收到了。
每send一次消息,每次只会有一个recv端接收到。这是一个轮训机制,也就是负载均衡,把消息依次分发给recv端。
期间还可以再增加或者减少recv端的数量。
recv端的 channel.basic_consume 下有一个no_ack参数,默认是False。这个参数是控制recv端是否在调用完成回调函数后给send端一个确认的,默认是要开启确认的,之前我们都关掉了。就是执行后不确认,也就是服务端把一个消息分发出去后就不管了。客户端接收之后可能没能正常执行完毕,下面来模拟一下。
把no_ack参数设为False,或者删掉,默认就是False。然后回调函数里一定要加上一句表示确认消息处理完毕的语句 ch.basic_ack(delivery_tag=method.delivery_tag) 。
手动给回调函数加上一个time.sleep,让一条消息需要处理一段时间。我们在recv端开始处理消息但是没处理完之前把这个程序停了,观察其他recv端的情况。新的recv端如下:
import pika, time
# 建立连接、管道、队列,和send端一样
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
channel = connection.channel()
# 声明队列,只要声明一次就好了,之前send端也声明过了,但是重复声明并没有问题
# 不声明也没有关系,只要你确认这个队列已经声明过了
# 但是,我们并不确定之前是否声明了队列,所以每次都声明一下才是好的做法
channel.queue_declare(queue='hello')
# 准备一个回调函数,下面是一个标准的声明回调函数的格式,带4个参数
def callback(ch, method, properties, body):
for i in range(10):
print('\r%d' % i, end='', flush=True)
time.sleep(1)
print("\rTime's up")
print("Recv: %r" % body) # 注意,收到的是bytes格式
# 如果没有确认,服务端就不认为消息处理完成了
# 所以,依然会将这条消息留在队列里,准备分发给别的recv端处理
ch.basic_ack(delivery_tag=method.delivery_tag) # 确认消息处理完毕
# 声明接收消息的语法,并没有开始收
# 声明回调函数,如果收到消息,就调用这个函数
# 从哪个队列里收消息
channel.basic_consume(callback,
queue='hello',) # no_ack参数默认值是False,就是需要确认
print('等待接收消息,按 CTRL+C 退出')
# 这里开始持续接收消息,没有消息就阻塞
channel.start_consuming()默认的no_ack=False的模式,如果一个消息没有确认,但是连接断了,那么这个消息还会有别的recv端重新处理。只有在recv端确认了之后,才会从服务器的队列中清除。
消息持久化
官网上的 2 Work queues
先查看一下rabbitmq服务器上的信息,使用这个命令可以查看服务器上的队列:
$ rabbitmqctl list_queues此时应该可以看到之前的hello这个队列,后面有个数字,表示这个队列里还有多少条消息。因为是0,表示消息都收完了。如果还有消息,可以启动recv端把消息收下来,然后再确认一下服务端队列的情况。还有一种情况是no_ack=False之后,回调函数里没有加确认,那么所有需要确认的消息都会留在队列中,记得在recv端加上确认的语句把消息收完。
服务器中的队列会在服务重启后丢失,包括队列和队列中的消息。重启服务:
$ systemctl restart rabbitmq-server此时再启动send端发两条消息,不用收。
然后修改一下send端,修改声明队列的那一句,把队列名字改掉,加上durable参数设为True,后面一句发消息的语句里routing_key记得也把队列名字改了。还是发几条消息出来不收。
channel.queue_declare(queue='hello2', durable=True)此时再去确认一下服务器上的两个队列,以及队列中的消息数量,都应该有。再次重启服务后,检查队列信息。现在没有durable的队列彻底没了,durable设为True的队列,只是队列还在,但是消息还是没有,现在只是队列持久化了。还需要在发消息的语句里加上一个参数,把消息也声明为持久化。新的消息持久化的send端如下:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
channel = connection.channel()
channel.queue_declare(queue='hello2', durable=True) # 声明一个持久化的队列
channel.basic_publish(exchange='',
routing_key='hello2',
body='Hello2 World!',
properties=pika.BasicProperties(delivery_mode=2)
) # 声明这条消息也是要持久化的
print("Send: 'Hello World!'")
connection.close()此时发出的消息,会在服务器上实现持久化,就是重启服务或者关机,恢复后队列和消息都不会丢失,使用recv端可以继续收消息。
注意:重复声明队列的时候,队列的属性需要与已有的队列一致,否则运行到声明的语句会报错。
消息公平分发
上面已经试过了,消息可以轮训的分发到每一个recv端,实现负载均衡。但是现实环境中可能每个recv端的性能是不一样的,如果只是这种简单的轮训,那么处理快的机器可能是空闲状态,但是处理慢的机器可能会积累很多消息来不及处理。
通过在recv端加如下的一句语句:
channel.basic_qos(prefetch_count=1)表示这个recv端一次只处理一条消息,如果1条消息没处理完,就不会在给它发新的消息处理。这个数字还可能调整。
广播(消息发布\订阅)
官网上的 3 Publish/Subscribe
send端就是消息发布,recv端就是订阅。
之前的例子都是一对一发送消息的,消息只能发送到指定的队列中,用的是默认的exchange设置。通过定义exchange来实现更多的效果,比如广播效果。
Exchange在定义的时候有类型的,以决定到底是哪些Queue符合条件,可以接收消息:
消息发布的send端:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
channel = connection.channel()
# 定义一个广播模式的exchange,需要名字和类型
channel.exchange_declare(exchange='broadcast',
exchange_type='fanout')
# 不需要声明队列了,因为所有队列都能收
channel.basic_publish(exchange='broadcast',
routing_key='',
body='Hello World!')
print("Send: 'Hello World!'")
connection.close()订阅的recv端:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
channel = connection.channel()
# 定义广播的exchange,和send端一样,重复声明,确认exchange一定存在的情况下可以不要
channel.exchange_declare(exchange='broadcast',
exchange_type='fanout')
# 下面声明队列的时候,不指定队列名字,服务器会随机分配一个名字
# exclusive设为True,断开后服务器会将这个queue删除
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue # 获取自动分配的队列名字,下面收消息的时候要名字
channel.queue_bind(exchange='broadcast',
queue=queue_name) # 将队列绑定到exchange转发器
def callback(ch, method, properties, body):
print("Recv: %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
print('等待接收消息,按 CTRL+C 退出')
channel.start_consuming()这里send端比较简单,只需要定义好exchange是广播模式,然后把消息发出就好了。这里其实消息广播出去后就没了,把消息广播到所有的队列。现在是还没队列,那也算广播出去了,就是没了。
recv端,也是先和send端一样声明一个广播模式的exchange。这里依然是重复声明,得保证这个exchange已经存在。
recv接收消息必须要通过队列,这里使用了自动分配的队列名,并且一旦断开队列也会被服务器删除,然后获取到这个队列名保存到变量中之后还要使用。
将队列名和exchange绑定,绑定后这个队列就能收到exchange的消息了。后面接收消息就一样了。
RabbitMQ收发消息的机制
讲到这里,可以先来理解下一RabbitMQ收发消息的机制了。下面是图,左边是生产者客户端就是send端,有边是消费者客户端就是recv端。中间是服务器包括exchange和queue。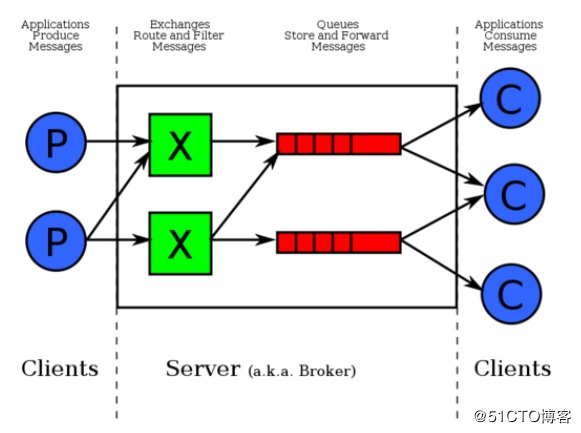
我们得保证exchange和queue都得已经存在,尝试连接一个不存在的会报错,一般都是send和recv两边都声明一下,重复声明是正确的做法,声明后服务器上就会建立对应的exchange或queue。
send端负责建exchange,将消息发送到exchange,可以指定多个exchange
recv端则是负责建queue,把queue绑定bind到exchange收取消息,可以指定多个queue
exchange如何将消息传递给queue,就需要我名来绑定了,也可以多次绑定(不是一对一的)。
第一个例子中,貌似直接把消息发到队列里了。RabbitMQ中的消息是无法直接发送到queue中的,总是要通过一个exchange才能把消息传到queue中。这里用空字符串表示一个默认的exchange,这是一个特殊的exchange,可以精确的消息发送到一个指定的queue中。然后recv端是多个客户端连接一个队列,一个客户端把消息收掉后,其他客户端旧收不到了。
广播的例子中,是正常定义好了exchange,把消息发到exchange里,此时还没有绑定到任何队列,所有的消息都会丢失。然后recv端会建立自己的queue,然后绑定到exchange,此时exchange里的消息就会复制一份到绑定过的queue了。每个recv端连接的是不同的队列,每个队列里有一份消息,所以不会影响别的recv端收消息。
有选择的接收消息
官网上的 4 Routing
exchanges中的消息还需要匹配routing_key。只有exchange和routing_key都匹配,才能收到消息。
sent端如下,每一条消息发送的时候,都指定了exchange和routing_key:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.3.108'))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange='direct_logs') # 默认类型就是'direct'
# 发送3条消息,每条的routing_key不同
severity_list = ['error', 'warning', 'info']
for severity in severity_list:
msg = "%s: %s" % (severity, 'Hello World!')
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=msg)
print("Send: %s" % msg) # 本地打印一下
connection.close() # 关闭,关闭队列就好了,管道不用关闭recv端,你需要把队列精确的匹配exchang和routing_key进行绑定,可以多次绑定
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.3.108'))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange='direct_logs')
# 声明自动分配的队列名
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 多次绑定多个routing_key
severity_list = ['error', 'warning', 'info'] # 使用这个列表可以收到3条消息
# severity_list = ['error'] # 使用这个列表,只能收到error的一条消息
for severity in severity_list:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
def callback(ch, method, properties, body):
print(method.exchange, method.routing_key) # method里的一些详细信息
print("Recv: %r" % body)
# 声明接收消息的语法
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
print('等待接收消息,按 CTRL+C 退出')
channel.start_consuming()例子中的 severity_list 可以控制收消息的范围。只会收到 severity_list 和 routing_key 匹配的消息。
更细致的消息过滤
官网上的 5 Topics
send端和上面的Routing的模式基本一样,只是exchange的type变成了topic。然后你的routeing_key可以写的更加复杂一点,规则如下:由1个或多个关键字组成,关键字之间以点分隔。
recv端接收的时候还是去匹配exchange和routing_key,只是这次的routing_key不是精确匹配了,而是可以有通配符,通配符就#和*,规则也很简单:
# : 匹配0个或多个关键字
* : 匹配1个关键字
比如,anonymous.info ,可以被 *.info 或 anonymous.* 匹配到,但如果是 a.anonymous.info.b 就无法被匹配到了,因为*号只能匹配一个关键字。
再比如, #.key_word.# 就可以匹配到所有含有 key_word 的消息(包括 routingkey='key_word' ),无论前后是否有别的关键字或者多个关键字,但是 key_word 必须是作为单独的关键字出现。比如 key_words (这里多了个s)就会被认为是另外一个关键字了。总之关键字之间要用点分隔开。
最后,用 # ,就是收所有了,就相当于广播了。
再不清楚试一下就明白了,send端:
import pika
def send(routing_key):
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic') # 只是类型变了
msg = "%s: %s" % (routing_key, 'Hello World!')
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=msg)
print("Send: %s" % msg)
connection.close()
if __name__ == '__main__':
routing_key = 'anonymous.info' # 修改你的routing_key
send(routing_key)recv端:
import pika
def recv(binding_key):
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
# 声明自动分配的队列名
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
def callback(ch, method, properties, body):
print("Recv: %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
print('等待接收消息,按 CTRL+C 退出')
channel.start_consuming()
if __name__ == '__main__':
binding_key = '*.info' # # 修改你的binding_key以匹配routing_key
recv(binding_key)Remote procedure call (RPC)
官网上的 6 RPC
上面都是单向的消息流,send端只有发,recv端只有收。使用RPC,recv端可以再把消息返回给send端。
这里先准备一个服务端,接收数据,把收到的数据转成数字,计算出一个结果(这里算一个之前用到过的斐波那契数列)。算出结果后还要发回给客户端。要往回发消息,就需要在回调函数里再调用一个发消息的方法。
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
# 这个函数不是这里的重点,
# 只是通过客户端发来的数,计算后把结果回复给客户端
def fib(n):
"""计算斐波那契数列"""
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
"""回调函数
先把消息转成数字
根据数字计算出结果
把计算结果发回去
回复一个任务已经完成
"""
n = body.isdigit() and int(body) or 0 # body必须是数字,否则按0处理
print(" [.] fib(%s)" % n)
response = fib(n)
# 下面是给吧结果回复给客户端
# 方法就是和send端发送数据的方法一样
# 但是这里不需要生成一个channel了,而是用接收数据已有的ch
# 回复的时候处理有计算结果,还要把收到的id发回去
# 客户端通过correlation_id把id发过来,服务的通过props.correlation_id接收
# 然后回复计算结果是再通过correlation_id把id发回给客户端
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(
correlation_id=props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag) # 回复任务已经处理完毕
channel.basic_qos(prefetch_count=1) # 一次只处理一个任务
# 从队列'rpc_queue'接收数据,然后调用回调函数'on_request'处理
channel.basic_consume(on_request,
queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()然后我们准备客户端,向服务端发起请求,获取计算后得到的结果。这里的客户端比较复杂,写成了一个类。
使用前先实例化,然后调用call方法把要发送的数据传入。发送的消息中还要包括用户接收计算结果的队列以及这条消息的id。
发送后,进入一个循环,反复调用一个非阻塞版的start_consuming。这个consume在实例化的时候,就已经生成了。一旦有消息进来会先调用回调函数,检查id和之前发出去的id是否一样,一样就赋值给 self.response 。此时满足了循环退出的条件,跳出循环返回接收到的计算结果。例子如下:
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(
pika.ConnectionParameters('192.168.246.11'))
self.channel = self.connection.channel()
# 自动生成一个队列,这个队列是用于接收计算结果的
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
# 从哪个队列收消息,这个是client,发起一个send,然后结果要通过recv收计算结果
# 队列在上面声明好了,回调函数后面写,不需要确认收到
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
"""接收计算结果的回调函数
比较本地id和接收到消息里的id是否一致
一致就确认是回复的计算结果
"""
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
"""把客户端的请求发送给服务端
就是send一条消息
消息send后是要等待回复的,所以消息中有接收回复的参数
"""
self.response = None # 存放收到的计算结果
self.corr_id = str(uuid.uuid4()) # 生成一个id随消息一同发出
# 下面是发送数据,比之前多了2个参数
# reply_to告知服务端用于回复计算结果的队列
# correlation_id告知服务端这个请求的id,服务端回复的时候会把这个id发出来,确认是这条消息的计算结果
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
# 消息发出后,就等待服务端回复了,下面是一个非阻塞的方法,确认消息是否收到
while self.response is None:
# 因为是非阻塞,所以这里会循环无数次
# 这个connection在实例化的时候就已经生成了接收数据的consume
# 下面这句就是一个非阻塞版的start_consuming
self.connection.process_data_events() # 非阻塞
# 计算结果会通过构造函数中定义的队列发回来
# 收到后会执行回调函数on_response
# 比较和之前的id一致后,确认是请求对应的回复
# 此时self.response会在回调函数中被赋值,下面就返回结果
return int(self.response)
if __name__ == '__main__':
fibonacci_rpc = FibonacciRpcClient() # 生成一个实例
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30) # 调用call方法,就是把消息发出去
print(" [.] Got %r" % response)作业
基于RabbitMQ rpc实现的主机管理:
可以对指定(多台)机器异步的执行多个命令
例子:
>>:run "df -h" --hosts 192.168.3.55 10.4.3.4
task id: 45334
>>: check_task 45334
>>:注意:每执行一条命令,即立刻生成一个任务ID,不需等待结果返回,通过命令check_task TASK_ID来得到任务结果
上一篇: Windows Server 2016
下一篇: python PIL模块
- H3C基本命令大全
53516
- H3C IRF原理及 配置
40346
- Python exit()函数
34747
- python全系列官方中文文档
30503
- python 获取网卡实时流量
25378
- 1.常用turtle功能函数
25177
- python 获取Linux和Windows硬件信息
23589
- 天天基金网数据接口
18857
- Selenium使用代理IP&无头模式访问网站
15170
- Selenium&Pytesseract模拟登录+验证码识别
14676
- LangGraph Studio可视化
1144°
- LangSmith开发-应用入门
1066°
- LangGraph开发-多轮对话问答机器人
1135°
- LangGraph开发-条件分支/循环图实战
1152°
- LangGraph开发-生态介绍,入门demo实战
1188°
- LangChain-接入12306-HTTP MCP智能体
1343°
- LangChain接入自定义爬虫-MCP工具
1301°
- LangChain接入Filesystem-MCP工具
1275°
- LangChain搭建MCP服务端和客户端流程
1376°
- LangGraph与MCP技术概述
1318°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
