python url采集
发布时间:2019-09-14 09:45:54编辑:auto阅读(2652)
python利用百度做url采集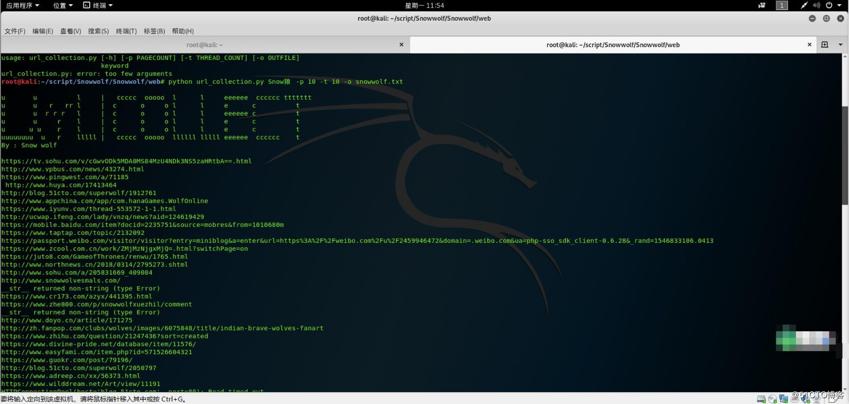
pip install tableprint
paramiko==2.0.8
语法:python url_collection.py -h输出帮助信息
python url_collection.py 要采集的信息 -p 页数 -t 进程数 -o 保存的文件名以及格式
新建文件touch url_collection.py
写入代码正式部分
#coding: utf-8
import requests
from bs4 import BeautifulSoup as bs
import re
from Queue import Queue
import threading
from argparse import ArgumentParser
logo="""
u u l | ccccc ooooo l l eeeeee cccccc ttttttt
u u r rr l | c o o l l e c t
u u r r r l | c o o l l eeeeee c t
u u r l | c o o l l e c t
u u u r l | c o o l l e c t
uuuuuuuu u r lllll | ccccc ooooo llllll lllll eeeeee cccccc t
By : Snow wolf
"""
print(logo)
arg = ArgumentParser(description='baidu_url_collect py-script by snowwolf')
arg.add_argument('keyword',help='keyword like inurl:.?id= for searching sqli site')
arg.add_argument('-p','--page', help='page count', dest='pagecount', type=int)
arg.add_argument('-t','--thread', help='the thread_count', dest='thread_count', type=int, default=10)
arg.add_argument('-o','--outfile', help='the file save result', dest='outfile', default='result.txt')
result = arg.parse_args()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'}
class Bd_url(threading.Thread):
def init(self, que):
threading.Thread.init(self)
self._que = que
def run(self):
while not self._que.empty():
URL = self._que.get()
try:
self.bd_url_collect(URL)
except Exception,e:
print e
pass
def bd_url_collect(self, url):
r = requests.get(url, headers=headers, timeout=3)
soup = bs(r.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for bq in bqs:
r = requests.get(bq['href'], headers=headers, timeout=3)
if r.status_code == 200:
print r.url
with open(result.outfile, 'a') as f:
f.write(r.url + '\n')def main():
thread = []
thread_count = result.thread_count
que = Queue()
for i in range(0,(result.pagecount-1)*10,10):
que.put('https://www.baidu.com/s?wd=' + result.keyword + '&pn=' + str(i))
for i in range(thread_count):
thread.append(Bd_url(que))
for i in thread:
i.start()
for i in thread:
i.join()if name == 'main':
main()
代码结束
上一篇: 3.redis集群部署3主3从
下一篇: python网络工具供以后使用
- H3C基本命令大全
53520
- H3C IRF原理及 配置
40348
- Python exit()函数
34749
- python全系列官方中文文档
30504
- python 获取网卡实时流量
25381
- 1.常用turtle功能函数
25179
- python 获取Linux和Windows硬件信息
23592
- 天天基金网数据接口
18860
- Selenium使用代理IP&无头模式访问网站
15171
- Selenium&Pytesseract模拟登录+验证码识别
14679
- LangGraph Studio可视化
1147°
- LangSmith开发-应用入门
1069°
- LangGraph开发-多轮对话问答机器人
1139°
- LangGraph开发-条件分支/循环图实战
1154°
- LangGraph开发-生态介绍,入门demo实战
1189°
- LangChain-接入12306-HTTP MCP智能体
1347°
- LangChain接入自定义爬虫-MCP工具
1307°
- LangChain接入Filesystem-MCP工具
1279°
- LangChain搭建MCP服务端和客户端流程
1379°
- LangGraph与MCP技术概述
1320°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
