1、Python大数据应用——部署Had
发布时间:2019-09-13 09:31:12编辑:auto阅读(2471)
Python大数据应用简介
简介:目前业界主流存储与分析平台以Hadoop为主的开源生态圈,MapReduce作为Hadoop的数据集的并行运算模型,除了提供Java编写MapReduce任务外,还兼容了Streaming方式,可以使用任意脚本语言来编写MapReduce任务,优点是开发简单且灵活。
Hadoop环境部署
1、部署Hadoop需要Master访问所有Slave主机实现无密码登陆,即配置账号公钥认证。
2、Master主机安装JDK环境
yum安装方式:yum install -y java-1.6.0-openjdk*
配置Java环境变量:vi /etc/profile
JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.41.x86_64
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=::$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
使配置文件生效:source /etc/profile 3、Master主机安装Hadoop
3.1、下载Hadoop,解压到/usr/local目录下
3.2、修改hadoop-env.sh中java环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.41.x86_643.3、修改core-site.xml(Hadoop core的配置文件)
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp/hadoop-${user.name}</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.1:9000</value>
</property>
</configuration>3.4、修改hdfs-site.xml(Hadoop的HDFS组件的配置项)
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/data/tmp/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>3.5、修改mapred-site.xml(配置map-reduce组件的属性,包括jobtracker和tasktracker)
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.1:9001</value>
</property>
</configuration>3.6、修改masters,slaves配置文件
masters文件
192.168.1.1slaves文件
192.168.1.1
192.168.1.2
192.168.1.34、Slave主机配置
4.1、配置和Master主机一样的JDK环境,目标路径保持一致
4.2、将Master主机配置好的hadoop环境复制到Slave主机上
5、配置防火墙
master主机
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50030 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50070 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 9000 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 90001 -j ACCEPTSlave主机
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50075 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50060 -j ACCEPT
iptables -I INPUT -s 192.168.1.1 -p tcp --dport 50010 -j ACCEPT6、检验结果
6.1、在Master主机上执行启动命令(在安装目录底下)
./bin/start-all.sh所示结果如下,表示启动成功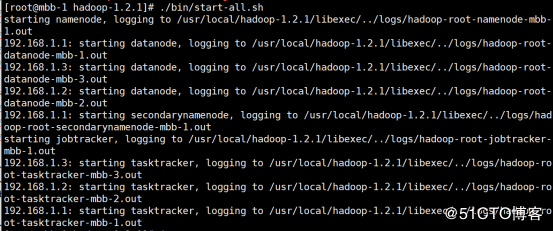
6.2、在Master主机上测试MapReduce示例
./bin/hadoop jar hadoop-examples-1.2.1.jar pi 10 100所示结果如下,表示配置成功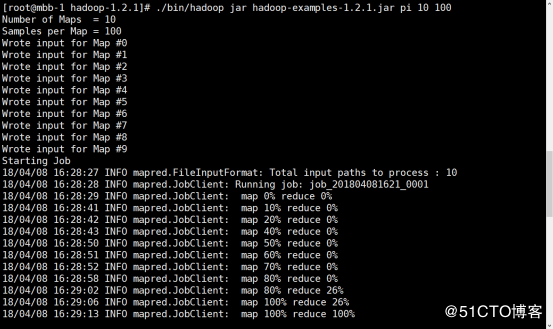
7、补充:访问Hadoop提供的管理页面
Map/Reduce管理地址:192.168.1.1:50030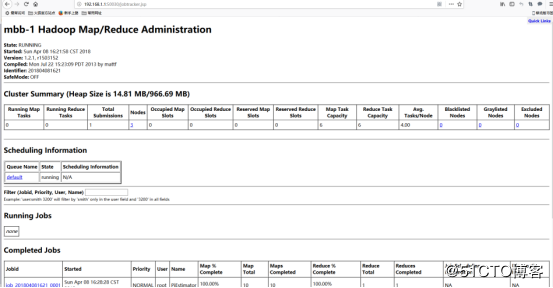
HDFS管理地址:192.168.1.1:50070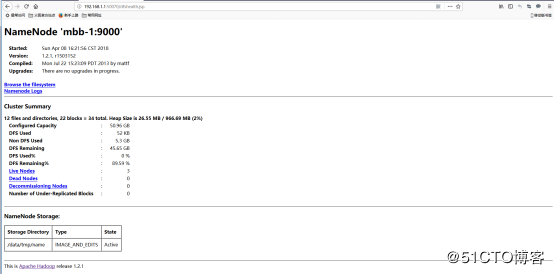
上一篇: Python自动化开发学习-RESTfu
下一篇: python代码优化案例分析
- H3C基本命令大全
53518
- H3C IRF原理及 配置
40346
- Python exit()函数
34747
- python全系列官方中文文档
30503
- python 获取网卡实时流量
25378
- 1.常用turtle功能函数
25177
- python 获取Linux和Windows硬件信息
23589
- 天天基金网数据接口
18858
- Selenium使用代理IP&无头模式访问网站
15170
- Selenium&Pytesseract模拟登录+验证码识别
14676
- LangGraph Studio可视化
1144°
- LangSmith开发-应用入门
1067°
- LangGraph开发-多轮对话问答机器人
1136°
- LangGraph开发-条件分支/循环图实战
1152°
- LangGraph开发-生态介绍,入门demo实战
1188°
- LangChain-接入12306-HTTP MCP智能体
1344°
- LangChain接入自定义爬虫-MCP工具
1303°
- LangChain接入Filesystem-MCP工具
1277°
- LangChain搭建MCP服务端和客户端流程
1376°
- LangGraph与MCP技术概述
1319°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
