python爬虫之url中的中文问题
发布时间:2019-09-13 09:28:57编辑:auto阅读(2538)
在python的爬虫学习中,我们的url经常出现中文的问题,
我们想要访问的url就需要对url进行拼接,变成浏览器可以识别的url
在python中已经有了这样的模块了,这就是urlencode
urlencode需要对中文和关键字组成一对字典,然后解析成我们的url
在python2中是
urllib.urlencode(keyword)
在Python中是
urllib.parse.urlencode(keyword)
查看一下代码:
python2
import urllib
import urllib2
#例如我们需要在百度上输入个关键字哈士奇进行查询,但是哈士奇是中文的,我们需要对哈士奇进行编码
keyword = {"wd":"哈士奇"}
head_url = "http://www.baidu.com/s"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
wd = urllib.urlencode(keyword)
url = head_url +"?"+ wd
req = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(req)
html = response.read()
print(url)
print(html.count('哈士奇'))结果如下: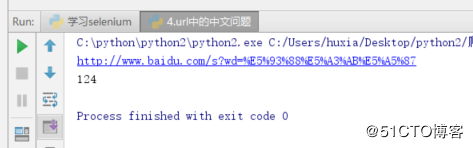
在python3中:
# -*- coding: utf-8 -*-
# File : url中出现的中文问题.py
# Author: HuXianyong
# Date : 2018-09-13 17:39
from urllib import request
import urllib
#例如我们需要在百度上输入个关键字哈士奇进行查询,但是哈士奇是中文的,我们需要对哈士奇进行编码
keyword = {"wd":"哈士奇"}
head_url = "http://www.baidu.com/s"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
wd = urllib.parse.urlencode(keyword)
url = head_url +"?"+ wd
req = request.Request(url,headers=headers)
response = request.urlopen(req)
html = response.read()
print(html.decode().count("哈士奇"))
print(url)结果如下: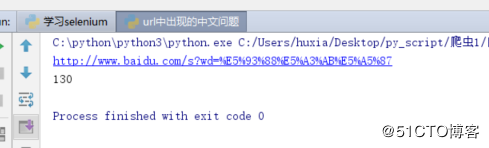
如果需要吧转换的字符变成中文
可以用unquota
如下:
python2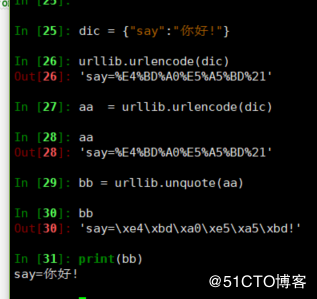
In [25]: dic = {"say":"你好!"}
In [26]: urllib.urlencode(dic)
Out[26]: 'say=%E4%BD%A0%E5%A5%BD%21'
In [27]: aa = urllib.urlencode(dic)
In [28]: aa
Out[28]: 'say=%E4%BD%A0%E5%A5%BD%21'
In [29]: bb = urllib.unquote(aa)
In [30]: bb
Out[30]: 'say=\xe4\xbd\xa0\xe5\xa5\xbd!'
In [31]: print(bb)
say=你好!
python3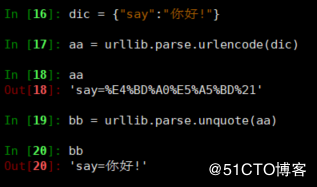
In [16]: dic = {"say":"你好!"}
In [17]: aa = urllib.parse.urlencode(dic)
In [18]: aa
Out[18]: 'say=%E4%BD%A0%E5%A5%BD%21'
In [19]: bb = urllib.parse.unquote(aa)
In [20]: bb
Out[20]: 'say=你好!'
但是如果我们的是post请求数据需要加在data里面这样就还需要对data做处理,不然会报字符串的错:
TypeError: POST data should be bytes or an iterable of bytes. It cannot be of type str.这样的解决方法是需要加上个编码data = urllib.parse.urlencode(formData).encode(encoding="UTF8")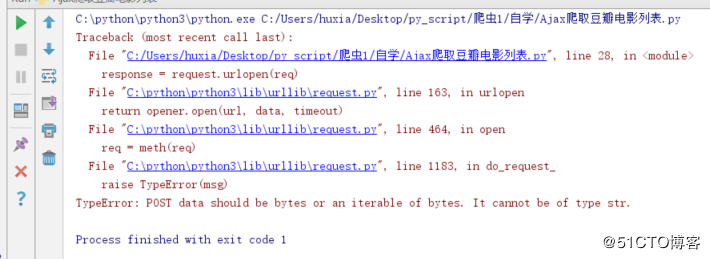
代码如下:
# -*- coding: utf-8 -*-
# File : Ajax爬取豆瓣电影列表.py
# Author: HuXianyong
# Date : 2018-09-14 14:35
import urllib
from urllib import request
url = "https://movie.douban.com/j/new_search_subjects?"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
formData = {
"sort": "S",
"range": "0,10",
"tags": "电影,魔幻",
"start": "0",
"genres": "剧情"
}
data = urllib.parse.urlencode(formData).encode(encoding="UTF8")
req = request.Request(url=url,data=data,headers=headers)
response = request.urlopen(req)
move_info = response.read().decode()
print(response.read().decode())
上一篇: python selenium系列(11
下一篇: python中的for循环对象和循环退出
- H3C基本命令大全
53518
- H3C IRF原理及 配置
40346
- Python exit()函数
34747
- python全系列官方中文文档
30503
- python 获取网卡实时流量
25378
- 1.常用turtle功能函数
25177
- python 获取Linux和Windows硬件信息
23589
- 天天基金网数据接口
18859
- Selenium使用代理IP&无头模式访问网站
15170
- Selenium&Pytesseract模拟登录+验证码识别
14676
- LangGraph Studio可视化
1145°
- LangSmith开发-应用入门
1067°
- LangGraph开发-多轮对话问答机器人
1136°
- LangGraph开发-条件分支/循环图实战
1152°
- LangGraph开发-生态介绍,入门demo实战
1188°
- LangChain-接入12306-HTTP MCP智能体
1344°
- LangChain接入自定义爬虫-MCP工具
1304°
- LangChain接入Filesystem-MCP工具
1277°
- LangChain搭建MCP服务端和客户端流程
1376°
- LangGraph与MCP技术概述
1319°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
