目录
一. 正则表达式
二. 特殊的元字符
三. python3的re模块方法
四. python3的re模块练习
五. 第一章课后练习题
六. re模块综合应用之计算器
一. 正则表达式
正则表达式是由一堆字符和特殊符号组成的字符串。它可以为我们提供高级的文本搜索,匹配,替换功能。当然,正则表达式也不是python独有的一种模式,而是凌驾于语言之上的一种跨平台的通用标准。当我们学会了正则表达式之后,将会能够更加容易的处理我们的文本和数据。让我们开始正则之旅吧。
二. 特殊的元字符
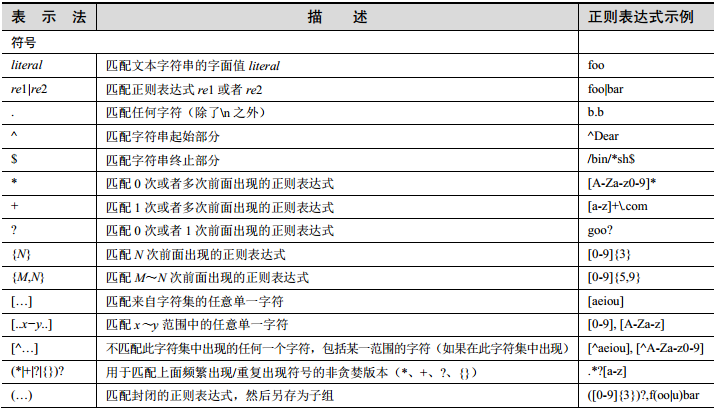
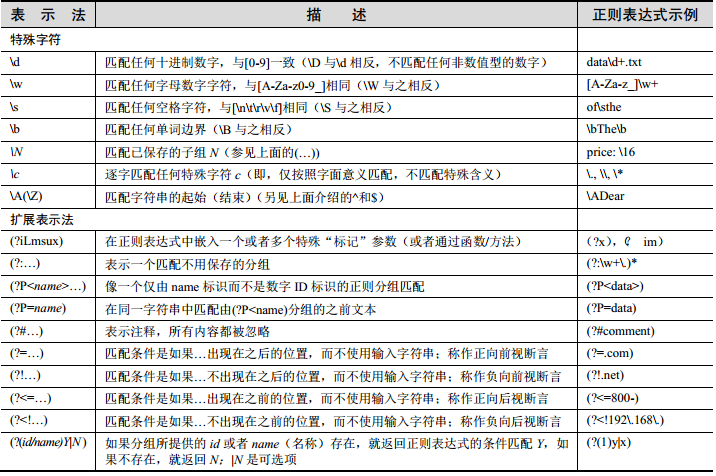
正则表达式本质上就是一堆字符串,只不过构成这个字符串的每一个字符都是有特别意义的,我们想要去真正的去了解正则表达式,就必须要清楚的记得特殊字符的含义。下图是python核心编程中关于元字符的描述。虽然有很多,但是你一定要背会(当然在学的过程中你会发现其实也没有那么难背,用着用着就记住了,但是还是提醒,不管是什么方法,一定要记住)。
在我们真正开始正则表达式之前,我们首先要了解一个工具,那就是python的re模块,快速的了解,只需要知道通过这个模块我们可以查看写出来的正则表达式是否准确就可以了。之后我们会再去详细的查看,使用方法如下:
>>> re.search('^s.*$', 'sllsljegleg')# 第一个参数:就是我们写出来的正则表达式(从表面上看就是字符串)第二个参数:就是我们匹配的字符串,如果匹配到了就返回值
<_sre.SRE_Match object; span=(0, 11), match='sllsljegleg'> # 最后match后面的就是我们匹配到的字符串
>>> re.search('^s.*$', 'llsljegleg') # 如果没有匹配到就没有显示
>>>
第一类: 位置匹配
位置匹配就是专门用来描述位置的元字符,有四个: 【^,$, \A,\Z】(注意是有大小写之分的),^ 和\A都表示字符串的开头,$ 和\Z都表示字符串的结尾,为什么会有两个元字符去表示同一个事物呢?这是因为在一些国际键盘上是没有脱字符的,所以设计的时候又设计了\A和\Z来表示。
>>> re.search('^From','From to China') # 以From开头的字符串
<_sre.SRE_Match object; span=(0, 4), match='From'>
>>> re.search('/bin/tcsh$', 'python /bin/tcsh') # 以/bin/tcsh结尾的字符串
<_sre.SRE_Match object; span=(7, 16), match='/bin/tcsh'>
>>> re.search('^Subject:hi$', 'Subject:hi') # 如果前面有脱字符,后面美元符,就代表只匹配里面的值,此例中就是只匹配Subject:hi
<_sre.SRE_Match object; span=(0, 10), match='Subject:hi'>
>>>
需要匹配【$】和脱字符【^】的时候怎么做呢,通过【\】斜杠进行转义
>>> re.search('\$', '$') 通过\转义就可以匹配到$ 符了
<_sre.SRE_Match object; span=(0, 1), match='$'>
>>> re.search('\^\$', 'hello ^$')
<_sre.SRE_Match object; span=(6, 8), match='^$'>
>>>
【\A, \Z】的用法和^$的用法是一样的


>>> re.search('\AFrom','From to China') # 以From开头的字符串
<_sre.SRE_Match object; span=(0, 4), match='From'>
>>> re.search('/bin/tcsh\Z', 'python /bin/tcsh') # 以/bin/tcsh结尾的字符串
<_sre.SRE_Match object; span=(7, 16), match='/bin/tcsh'>
>>> re.search('\ASubject:hi\Z', 'Subject:hi') # 如果前面有脱字符,后面美元符,就代表只匹配里面的值,此例中就是只匹配Subject:hi
<_sre.SRE_Match object; span=(0, 10), match='Subject:hi'>
>>>
【\b】匹配任何单词边界
>>> s = 'this island is beautiful'
>>> import re
>>> re.search(r'\bis', s) # 此时我们会发现匹配到了索引为5,7的字符,也就是说island这个前面的is匹配到了
<_sre.SRE_Match object; span=(5, 7), match='is'>
>>> re.search(r'\bis\b', s) # 如果加上\b界定上单词边界之后就会之匹匹厄后面的is了,因为前面的is并不是一个单词
<_sre.SRE_Match object; span=(12, 14), match='is'>
>>>
第二类: 重复匹配
重复匹配就是将之前匹配的正则表达式重新匹配多少次。重复匹配是正则表达式中基本上最常用的模式。
【*】匹配前面正则表达式0次或者多次
>>> re.search('\d\d*', '1') # 第一个\d匹配一个数字,第二个\d本来也是匹配一个数字,但是后面加上了一个*,代表前面可以不匹配,也可以匹配一次或者多次
<_sre.SRE_Match object; span=(0, 1), match='1'>
>>> re.search('\d\d*', '12') # 这个就是第二个\d匹配了1次
<_sre.SRE_Match object; span=(0, 2), match='12'>
>>> re.search('\d\d*', '123') # 这个就是第二个\d匹配了2次
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>>
【+】匹配前面正则表达式1次或者多次
>>> re.search('\d\d+', '1') # 第一个\d匹配到了1,但是第二个\d后面有+代表最少匹配一次,但是字符串没有数字了,所以就没有匹配到值
>>> re.search('\d\d+', '12') # 这个代表第二个\d匹配了一次
<_sre.SRE_Match object; span=(0, 2), match='12'>
>>> re.search('\d\d+', '123') # 这个代表第二个\d匹配了两次
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>>
【?】匹配前面正则表达式0次或者1次
>>> re.search('\d\d?', '1') # 第一个\d匹配到了1,但是第二个\d后面有?说明可以匹配0次,也就是不匹配 <_sre.SRE_Match object; span=(0, 1), match='1'> >>> re.search('\d\d?', '12') # 第二个\d匹配了1次 <_sre.SRE_Match object; span=(0, 2), match='12'> >>> re.search('\d\d?', '123') # 虽然匹配到了,但是发现匹配到的值还是12,最多只能匹配一次 <_sre.SRE_Match object; span=(0, 2), match='12'>
>>>
【{n}】匹配前面正则表达式n次
>>> re.search('\d\d{2}', '12')
>>> re.search('\d\d{2}', '1')
>>> re.search('\d\d{2}', '123') # {2}代表前面的\d必须要匹配两次,所以只能匹配到123
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> re.search('\d\d{2}', '1234')
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>>
【{n, m}】匹配前面正则表达式n到m次
>>> re.search('\d\d{2,4}', '12')
>>> re.search('\d\d{2,4}', '123') # {2,4}代表匹配前面\d2次到4次,因此我们可以发现最少要匹配两次,最多要匹配4次
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> re.search('\d\d{2,4}', '1234')
<_sre.SRE_Match object; span=(0, 4), match='1234'>
>>> re.search('\d\d{2,4}', '12345')
<_sre.SRE_Match object; span=(0, 5), match='12345'>
>>> re.search('\d\d{2,4}', '123456')
<_sre.SRE_Match object; span=(0, 5), match='12345'>
>>>
重复匹配的例子
# 1. 匹配字符d或b之后跟着一个o最后可以跟着一个t也可以不跟着一个t的例子
>>> re.search('[db]ot?', 'do')
<_sre.SRE_Match object; span=(0, 2), match='do'>
>>> re.search('[db]ot?', 'dot')
<_sre.SRE_Match object; span=(0, 3), match='dot'>
>>> re.search('[db]ot?', 'bo')
<_sre.SRE_Match object; span=(0, 2), match='bo'>
>>> re.search('[db]ot?', 'bot')
<_sre.SRE_Match object; span=(0, 3), match='bot'>
>>>
# 2. 匹配9-16位的信用卡号
>>> re.search('[0-9]{9, 16}', '1234567890') # 注意不能加空格
>>> re.search('[0-9]{9,16}', '1234567890')
<_sre.SRE_Match object; span=(0, 10), match='1234567890'>
>>>
# 3. 匹配全部有效的html标签
>>> re.search('</?[^>]+>', '</>') #/?代表/可以不出现,代表的是开头的标签,也可以出现1次,代表的是结尾的标签,[^>]代表的是除了>的任何字符,后面跟上+,也就是说除了>的任何字符出现一次或者多次
<_sre.SRE_Match object; span=(0, 3), match='</>'>
>>> re.search('</?[^>]+>', '<hello>')
<_sre.SRE_Match object; span=(0, 7), match='<hello>'>
>>>
第三类: 范围匹配
范围匹配是通过一个或者一组特殊的字符代表一个范围的数据。例如:【\d】代表的是0-9的数字数字。【大写字母的都是与之相反的】
【.】点代表的是除了换行符之外的任意的字符的匹配
>>> re.search('f.o', 'fao') # 匹配字母f和o之间的任何一个字符
<_sre.SRE_Match object; span=(0, 3), match='fao'>
>>> re.search('f.o', 'f#o')
<_sre.SRE_Match object; span=(0, 3), match='f#o'>
>>> re.search('f.o', 'f9o')
<_sre.SRE_Match object; span=(0, 3), match='f9o'>
>>> re.search('..', 'js') # 匹配任意的两个字符
<_sre.SRE_Match object; span=(0, 2), match='js'>
>>> re.search('..', 'ss')
<_sre.SRE_Match object; span=(0, 2), match='ss'>
>>>
【\d】表示0-9的任何十进制数字
>>> re.search('\d', '1') # 匹配0-9的任何一个字符
<_sre.SRE_Match object; span=(0, 1), match='1'>
>>> re.search('\d', '2')
<_sre.SRE_Match object; span=(0, 1), match='2'>
>>> re.search('\d', 'z') # z不是0-9所以匹配不到
>>>
【\w】字母数字下划线 相当于[a-zA-0-9_]的缩写
>>> re.search('\w', '1') # 字母数字下滑先都可以匹配到,而且也只是匹配一个字符
<_sre.SRE_Match object; span=(0, 1), match='1'>
>>> re.search('\w', 'a')
<_sre.SRE_Match object; span=(0, 1), match='a'>
>>> re.search('\w', '_')
<_sre.SRE_Match object; span=(0, 1), match='_'>
>>> re.search('\w', '#') # 因为#不在范围之内,所以没有匹配到
>>>
\d和\w的一些例子
#1. 一个数字字母组成的字符串和一串由数字组成的字符串
>>> re.search('\w+-\d+', 'ab123sejg-123456') # \w代表数字字母,+代表前面的数字字母可以出现一次或者多次,也就是把字母数字组成的字符串表示好了,\d+也是一样的效果,代表的是一串由数字组成的字符串
<_sre.SRE_Match object; span=(0, 16), match='ab123sejg-123456'>
>>>
#2. 以字母开头,其余字符是字母或者数字
>>> re.search('^[A-Za-z]\w*', 'a123lsege')
<_sre.SRE_Match object; span=(0, 9), match='a123lsege'>
>>>
#3. 美国电话号码的格式 800-555-1212
>>>
>>> re.search('\d{3}-\d{3}-\d{4}', '800-555-1212') # \d代表的是一个数字{3}代表的是前面的数字出现三次,也就是把800给匹配出来了,然后就是单纯的一个-,后面的也是一个效果,组合起来就把电话号码给匹配出来了。
<_sre.SRE_Match object; span=(0, 11), match='800-555-1212'>
>>>
# 4. 电子邮件地址xxx@yyy.com
>>> re.search('\w+@\w+\.com', 'hwt@qq.com') # 首先\w+匹配一个数字字母下划线的字符串,然后一个单纯的@,然后又是一个字符串, 之后\.因为做了转义,代表的就是一个单纯的.
<_sre.SRE_Match object; span=(0, 10), match='hwt@qq.com'>
>>>
【\s】匹配空格字符
>>> re.search('of\sthe', 'of the') # 就是匹配一个空格字符, 无论是换行符,\t\v\f都是可以匹配到的
<_sre.SRE_Match object; span=(0, 6), match='of the'>
>>>
【[a-b]】中括号代表a-b的一个范围,代表的是从a-b的字符之间匹配一个字符
应用一:创建字符串
>>> re.search('[A-Z]', 'D') # 匹配A-Z之间的一个字符,所以D就可以匹配了,之间不能有空格
<_sre.SRE_Match object; span=(0, 1), match='D'>
>>>
>>> re.search('[ab][cd]', 'ac') # 从第一个方框中取出一个值与第二个方框中取出一个值进行组合,注意不能匹配到ab和cd,如果想匹配ab和cd需要通过择一匹配符号也就是[|]
<_sre.SRE_Match object; span=(0, 2), match='ac'>
>>> re.search('[ab][cd]', 'ad')
<_sre.SRE_Match object; span=(0, 2), match='ad'>
>>> re.search('[ab][cd]', 'ac')
<_sre.SRE_Match object; span=(0, 2), match='ac'>
>>> re.search('[ab][cd]', 'ad')
<_sre.SRE_Match object; span=(0, 2), match='ad'>
>>>
【[^ a -b]】匹配除了a-b之外的任何一个字符
# 1. z后面跟着任何一个字符然后再跟着一个0-9之间的数字
>>> re.search('z.[0-9]', 'z#0')
<_sre.SRE_Match object; span=(0, 3), match='z#0'>
>>> re.search('z.[0-9]', 'z#1')
<_sre.SRE_Match object; span=(0, 3), match='z#1'>
>>>
# 2. 除了aeiou之外的任何字符
>>> re.search('[^aeiou]', 's')
<_sre.SRE_Match object; span=(0, 1), match='s'>
>>>
# 3. 除了制表符或者换行符之外的任何一个字符
>>> re.search('[^\n\t]', 'aljg')
<_sre.SRE_Match object; span=(0, 1), match='a'>
>>>
第四类: 分组匹配
分组匹配严格意义上来讲并不是一个匹配的元字符,因为它本身并不会影响匹配的结果,只是会把匹配的结果按照括号分开,然后存储到一定的位置,便于我们之后使用的。那为什么要有分组呢?因为在很多的时候我们并不是对于匹配出来的字符感兴趣的,有时候我们只是对于匹配字符的某一个块感兴趣,可能还会对这一块进行一系列的操作。这就需要分组来帮我们做这件事了。
分组相对来说较为简单,但是却相当重要,简单在于它并不会影响我们的匹配结果,重要在数据匹配之后大部分都要用到这个分组。
【 () 】,在之后介绍group和groups的时候会提到
>>> import re
>>> re.search('(\d+)([a-z])(\.)(\w+)', '123c.sleg234') # 这个和下面匹配的结果是一样的,意思是加上括号分组的时候并不会对匹配的结果产生影响
<_sre.SRE_Match object; span=(0, 12), match='123c.sleg234'> # 它只是通过分组给我们返回了一系列的数据,我们可以通过group(s)方法获得而已
>>> re.search('\d+[a-z]\.\w+', '123c.sleg234')
<_sre.SRE_Match object; span=(0, 12), match='123c.sleg234'>
>>>
第五类:择一匹配符
【|】竖杠代表的是从几个正则表达式中得到一个
>>> re.search('ab|cd', 'ab') # 从左边的ab和cd中匹配相应的数据,但是不会匹配ac,这也是和[]的区别
<_sre.SRE_Match object; span=(0, 2), match='ab'>
>>> re.search('ab|cd', 'cd')
<_sre.SRE_Match object; span=(0, 2), match='cd'>
>>> re.search('ab|cd', 'ac')
>>>
第六类:扩展表示法
扩展表示法等之后真正用到了再回来看吧

三. python3re模块方法
方法一: compile编译
程序是我们写出来的一堆字符串,计算机是看不懂的,因此想要让我们写出来的代码可以正常的计算机中执行,就必须将代码块编译成字节码(也就是程序能够理解的语言)。而complie编译就是这个原理,也就是我提前将字符串编译成一个对象,之后你要进行使用的时候不必再进行编译了,直接调用此对象就可以了。对于只调用一次的正则表达式用不用此方法都是可以的,但是对于那些需要调用多次的正则表达式而言,提前编译就能够大大的提升执行性能。complie方法就是为了做这样的一件事的。
>>> import re
>>> s = '\d+' # 这个是自己写的正则表达式
>>> int_obj = re.compile(s) # 通过complie方法将s编译成对象,之后就直接可以通过这个对象直接去调用方法,可以节省性能
>>> print(int_obj.search('123'))
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> print(int_obj.search('123'))
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> print(int_obj.search('123'))
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> print(int_obj.search('123'))
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>>
方法二:group 和 groups方法
(1).group和groups方法都是在正则表达式匹配成功之后调用的方法,如果没有匹配成功调用此方法会报错
(2).group方法会得到一个如下的列表【当前匹配的字符串, 分组一,分组二........】没有分组就只有一个元素
(3).groups方法会得到一个如下的元组 ( 分组一,分组二......), 没有分组就是空空列表
(4).这两个方法只能是search和match成功匹配到的对象才可以使用。
以美国电话号码匹配为例s1 = '\d{3}-\d{3}-\d{4}'
(1).没有分组的情况下
>>> s1 = '\d{3}-\d{3}-\d{4}' # 美国电话号码的格式匹配正则表达式
>>> s2 = '(\d{3})-(\d{3})-(\d{4})' # 将美国的电话号码进行分组
>>> tel = '099-898-2392' # 这是一个电话格式
>>> re.search(s1, tel) # 之前没有学group的时候我们一直得到的都是下面的这种对象
<_sre.SRE_Match object; span=(0, 12), match='099-898-2392'>
>>> re.search(s1, tel).group() # 得到匹配的值
'099-898-2392'
>>> re.search(s1, tel).group(0) # 和上面的是一样的,因为没有分组得到的列表中就只有一个元素
'099-898-2392'
>>> re.search(s1, tel).group(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
>>> re.search(s1, tel).groups() # 没有分组的情况下groups就是空的元组
()
>>>
(2)有分组的情况下
>>> s1 = '\d{3}-\d{3}-\d{4}' # 美国电话号码的格式匹配正则表达式
>>> s2 = '(\d{3})-(\d{3})-(\d{4})' # 将美国的电话号码进行分组
>>> tel = '099-898-2392'
>>>
>>> print(re.search(s2, tel).group())
099-898-2392
>>> print(re.search(s2, tel).group(0)) # 获得的是整个匹配的对象
099-898-2392
>>> print(re.search(s2, tel).group(1)) # 第一个子组099
099
>>> print(re.search(s2, tel).group(2)) # 获得的第二个子组898
898
>>> print(re.search(s2, tel).group(3)) # 获得的第三个子组2392
2392
>>> print(re.search(s2, tel).groups()) # 获得子组的一个列表
('099', '898', '2392')
>>>
方法三: match,search, findall
match: 在字符串的开头对写的正则表达式进行匹配。 匹配成功,返回匹配对象,匹配失败,返回None
search:在整个字符串中对写的正则表达式进行匹配。 匹配成功,返回第一个被匹配的对象,匹配失败,返回None
findall: 在整个字符串中对写的正则表达式进行匹配。只要是匹配成功的就添加到列表中,最后返回一个列表
match:
>>> re.match('foo', 'food on the table').group() # 从字符串开头开始匹配,匹配到了foo,所以group得到的是匹配到的foo 'foo' >>> re.match('ood', 'food on the table') # 从字符串开头开始匹配,发现并不是00d,所以没有匹配到结果,返回一个空 >>>
search:
>>> re.match('foo', 'seafood') # 字符串开头并不是foo,所以match没有匹配到 >>> re.search('foo', 'seafood').group() # search是在整个字符串中匹配的,所以 'foo' >>>
findall:
>>> re.match('foo', 'seafood, seafood') # 字符串开头并不是foo,所以没有匹配 >>> re.search('foo', 'seafood, seafood').group() # 在字符串匹配到第一个foo的时候就不再进行匹配了 'foo' >>> re.findall('foo', 'seafood, seafood') # 在字符串给中查找到所有匹配到的字符串放在列表中 ['foo', 'foo'] >>>
方法四: finditer, findall
finditer和findall作用其实是一样的,不同之处在于finditer返回的是一个迭代器(更加节省内存),而findall返回的是一个列表。
(1).在没有分组的情况下,每一个被匹配的元素都会作为列表的元素
(2).在分组的情况下,被匹配的元素会把子组放在一个元组中放在列表中(比较绕,直接上例子)
(1)在没有分组的情况下
s = 'This and that.' print(re.findall(r'Th\w+ and th\w+', s)) # 会把匹配到的信息一个一个的放在列表中,此处只是匹配了一个 print(re.finditer(r'Th\w+ and th\w+', s).__next__()) # iter返回一个迭代器,可以通过__next__去获得第一个对象,注意此处是类似于match获得的对象 print(re.match('s', 's')) # 为了和上面进行对比的 # 结果: # ['This and that'] # <_sre.SRE_Match object; span=(0, 13), match='This and that'> # <_sre.SRE_Match object; span=(0, 1), match='s'>
(2)有分组的情况
s = 'This and that.' print(re.findall(r'(Th\w+) and (th\w+)', s)) # 有分组就会发现列表中其实放的并不是匹配到的值了,而是子组元组 print(re.finditer(r'(Th\w+) and (th\w+)', s).__next__()) #但是iter得到的还是匹配的对象,如果想得到子组可以通过group去获得 print(re.match('s', 's')) # 为了和上面进行对比的 # 结果: # [('This', 'that')] # <_sre.SRE_Match object; span=(0, 13), match='This and that'> # <_sre.SRE_Match object; span=(0, 1), match='s'>
方法五: sub
sub将搜索匹配到的字符串替换成另外一种字符串。
# 参数一: 正则表达式 # 参数二: 要替换的字符串 # 参数三: 源字符串 # 将替换好的字符串进行返回 s = re.sub('X', 'Mr. Smith', 'attn: X\n\nDear X, \n') print(s) #结果: # attn: Mr. Smith # # Dear Mr. Smith,
# 参数一: 正则表达式 # 参数二: 要替换的字符串 # 参数三: 源字符串 # 将替换好的字符串进行返回 s = re.sub('[ae]', 'X', 'abcdef') print(s) # 结果: # XbcdXf
例子: 将美式的日期表示法转换成其他国家的日期表示法
# 2/20/[1991|91] 月/日/年 美国 # 20/2/1991 日/月/年 # 首先先把美国的时间格式用正则表达式匹配到 m = '(\d{1,2})/(\d{1,2})/(\d{4}|\d{2})' # 然后\N进行分组替换 s = re.sub(m, r'\2/\1/\3', '2/20/1991') print(s)
方法六: split
(1). 如果给定的模式不是特殊字符,那么此方法和字符串的split是一样的
(2). 可以通过设定一个max值来确定需要分割几次
python核心编程中提示我们: 能用字符串的split分割的尽量不要使用影响性能的正则表达式进行分割。
print(re.split(':', 'str1:str2:str3')) # 结果: # ['str1', 'str2', 'str3']
四. python3的re模块练习
练习一: 择一匹配多个字符串
>>> # 择一匹配 ... bt = 'bat|bet|bit' >>> print(re.match(bt, 'bt')) # 因为此时的bt是择一匹配,也就是只能匹配bat或者bet或者bit字符串 None >>> print(re.match(bt, 'he bit me')) # 虽然字符串中有bit但是不是在开头,所以匹配不到 None >>> print(re.search(bt, 'he bit me').group()) # 这个search在整个字符串中进行查找,是可以匹配到的 bit >>>
练习二: 使用【.】来匹配除了换行符以外的任意字符
>>> anyend = '.end' >>> print(re.match(anyend, 'bend').group()) # .匹配了b bend >>> print(re.match(anyend, 'end')) # 任意字符但不是没有,所以没有匹配到 None >>> print(re.match(anyend, '\nend')) # 任意的非换行符,所以没有匹配到 None >>> print(re.search(anyend, 'the end').group()) # 用search去匹配空格一个end end >>> print(re.match('3.14', '3014').group()) # . 没有加转义符代表的是匹配任意的非换行符,所以可以匹配到 3014 >>> print(re.match('3\.14', '3.14').group()) # 这个.被转义 了 3.14 >>>
练习三: 创建字符集的使用 【[ab][cd]】
>>> re.match('[c2][23][dp][o2]', 'c3po').group() # 在正则表达式的每个方框中随机挑一个进行组合 'c3po' >>> re.match('[c2][23][dp][o2]', 'c2do').group() 'c2do' >>> re.match('r2d2|c3po', 'c2do') # 择一匹配只能是r2d2或者是c3po和创建字符集还是有差别的 >>> re.match('r2d2|c3po', 'r2d2') <_sre.SRE_Match object; span=(0, 4), match='r2d2'> >>>
练习四: 重复匹配和分组
>>> # 邮件.com前面出现一个名称 ... mail1 = '\w+@\w+\.com' # 可以匹配类似于hello@xxx.com >>> # 扩展一下,使得.com前面可以出现一个或者两个名称 ... mail2 = '\w+@(\w+\.)?\w+\.com' # 可以匹配类似于hello@www.xxx.com >>> >>> # 再扩展一下,使得.com前面可以出现任意次数的名称 ... mail3 = '\w+@(\w+\.)*\w+\.com' >>> re.match(mail1, 'nobody@xxx.com').group() 'nobody@xxx.com' >>> re.match(mail2, 'nobody@www.xxx.com').group() 'nobody@www.xxx.com' >>> re.match(mail1, 'nobody@www.xxx.com') >>> re.match(mail3, 'nobody@aaa.www.xxx.com').group() 'nobody@aaa.www.xxx.com' >>>
练习五:分组的使用
>>> re.match('(\w+)-(\d+)', 'abcde-123') # 匹配字符串 <_sre.SRE_Match object; span=(0, 9), match='abcde-123'> >>> re.match('(\w+)-(\d+)', 'abcde-123').group() # 匹配完成之后用group()的到匹配的结果 'abcde-123' >>> re.match('(\w+)-(\d+)', 'abcde-123').group(1) # 用索引1得到分组一,也就是第一个括号匹配的数据 'abcde' >>> re.match('(\w+)-(\d+)', 'abcde-123').group(2)# 用索引2得到分组二,也就是第二个括号匹配的数据 '123' >>>
练习六: 位置匹配在python中的使用
>>> re.search('^The', 'The end.').group() # ^代表起始位置 'The' >>> re.search('^The', 'end. The') # 不作为起始地址 >>> re.search(r'\bThe', 'bite The Dog').group() #The左边是个边界,直白讲就是没有英文字符 'The' >>> re.search(r'\bThe', 'biteThe Dog') # The左边不是一个边界,所以没有匹配到 >>> re.search(r'\BThe', 'biteThe Dog').group() # B代表的就是不是边界的时候才会被匹配 'The' >>>
五. 第一章课后练习题
前期的准备:
生成一个用来作为re练习的随机字符串的代码:
import random from string import ascii_lowercase as lc import sys import time tlds = ('com', 'edu', 'net', 'org', 'gov') for i in range(random.randrange(5, 11)): dtint = random.randrange(sys.maxsize) dtstr = time.ctime(dtint) llen = random.randrange(4, 8) login = ''.join(random.choice(lc) for j in range(llen)) dlen = random.randrange(llen, 13) dom = ''.join(random.choice(lc) for j in range(llen)) msg = '%s::%s@%s.%s::%d-%d-%d\n' %( dtstr, login, dom, random.choice(tlds), dtint, llen, dlen ) with open('redata.txt', 'at', encoding='utf-8') as f: f.write(msg)
知识点储备一:找到时间戳中一周的第几天
>>> # 示例一: 找到时间戳中一周的第几天 ... data = 'Wed Sep 16 11:17:21 1992::pscss@tdaja.org::716613441-5-6' >>> # 通过择一匹配把每天的单词缩写放在一个括号内,然后^表示的是一个单词的起始 ... # 但是有的地方每天的单词缩写并不是这样的,所以这样子的正则表达式的适用性并不是很强 ... pattr1 = '^(Mon|Tue|Wed|Thu|Fri|Sat|Sun)' >>> print(re.search(pattr1, data).group()) Wed >>> print(re.search(pattr1, data).group(1)) Wed >>> >>> >>> # 因此下面的正则表达式的意思是任意的字母数字字符三个,但是注意写成这样'^(\w){3}'是有问题的 ... pattr2 = '^(\w{3})' >>> print(re.search(pattr2, data).group()) Wed >>> print(re.search(pattr2, data).group(1)) Wed >>> >>> >>> # 注意写成这样是有问题的 ... # 因为将{3}写在括号外部代表的是分组只有一个字符那就是\w,因此在匹配的过程中分组的值是在不停的更新迭代的,最后变成三个字符中的最后一个 ... # 启发: 我们分组想要什么样的值,就把()放在哪里。 ... pattr3 = '^(\w){3}' >>> print(re.search(pattr3, data).group()) Wed >>> print(re.search(pattr3, data).group(1)) d >>>
知识点储备二: 贪婪匹配
# 示例二:想得到由三个连字符分隔的整数 data = 'Wed Sep 16 11:17:21 1992::pscss@tdaja.org::716613441-5-6' # 通过这样的方式我们可以匹配到,但是只能称之为搜索,我们往往需要做的是匹配整个字符串,然后通过分组的形式获得我们需要的值 pattr1 = '\d+-\d+-\d+' print(re.search(pattr1, data).group()) # .+ 任意字符出现至少一次,因此匹配到了三个连字符整数的前面,之后通过后面的匹配整数,这样就实现了对整个字符串的匹配 # 然后通过分组获得我们需要的值 pattr2 = '.+(\d+-\d+-\d+)' # 当我们要获得分组的时候却发现此时的值并不是我们想要的,这是因为贪婪匹配的原因 # .+ 或匹配符合它要求的所有字符串,然后才会给后面的正则表达式进行匹配 print(re.search(pattr2, data).group(1)) # 我们可以通过?来结束贪婪匹配 pattr3 = '.+?(\d+-\d+-\d+)' print(re.search(pattr3, data).group(1)) # 结果: # 716613441-5-6 # 1-5-6 # 716613441-5-6
作业题:
import re # 1-1 识别后续的字符串:“bat”、“bit”、“but”、“hat”、“hit”或者“hut”。 print(re.search('[bh][aiu]t', 'hut').group()) # 1-2 匹配由单个空格分隔的任意单词对,也就是姓和名。 print(re.search(r'\b[a-zA-Z]+\s[a-zA-Z]+\b', 'Tom Jerry Hello Bye House Good God').group()) # 1-3 匹配由单个逗号和单个空白符分隔的任何单词和单个字母,如姓氏的首字母。 print(re.search(r'\w+,\s\w+', 'a, b').group()) # 1-4 匹配所有有效 Python 标识符的集合。 print(re.search(r'^[a-zA-Z_]\w*', 'hello_world1_').group()) # 此处写的是python的有效变量名的正则表达式 # 1-5 根据读者当地的格式,匹配街道地址(使你的正则表达式足够通用,来匹配任意数量的街道单词,包括类型名称)。 # 例如,美国街道地址使用如下格式: 1180 Bordeaux Drive。使你的正则表达式足够灵活, 以支持多单词的街道名称,如 3120 De la Cruz Boulevard。 print(re.search(r'^\d+(\s\w+)*', '3120 De la Cruz Boulevard').group()) # 1-6 匹配以“www”起始且以“.com”结尾的简单 Web 域名;例如, www://www. yahoo.com/。 # 选做题: 你的正则表达式也可以支持其他高级域名,如.edu、 .net 等(例如,http://www.foothill.edu)。 print(re.search('^w{3}.*\.(com|edu|net)', 'www.foothill.edu.com').group()) # 1-7 匹配所有能够表示 Python 整数的字符串集。python3中已经不再区分整形和长整形了 print(re.search(r'^0$|(^-?[1-9]\d*$)', '-2147483647').group()) # python中浮点数点是肯定要有的 # 1-9 匹配所有能够表示 Python 浮点数的字符串集。 .23和1.都是正确的?,三种情况,前面 print(re.match(r'(^\d+\.\d*$)|(^\d*\.\d+$)|(^\d+\.\d+$)', '09.23238').group()) # 1-10 匹配所有能够表示 Python 复数的字符串集。 # 1+2j -j +j 写出来的也只能满足一部分吧 print(re.search(r'(\d+\.?\d*[+-]?\d+\.?\d*j)|([+-]?\d+\.?\d*j)', '-2.2j').group()) # 1-11 匹配所有能够表示有效电子邮件地址的集合(从一个宽松的正则表达式开始,然后尝试使它尽可能严谨,不过要保持正确的功能 print(re.search('\w+@\w+\.\w+\.com', '18279159836@hwt.163.com').group()) print(re.search('\w+@(\w+\.)+\w+\.(com|edu|org)', '18279159836@hwt.163.com').group()) # 1-12 匹配所有能够表示有效的网站地址的集合(URL)(从一个宽松的正则表达式开始,然后尝试使它尽可能严谨,不过要保持正确的功能)。 print(re.search('^(https?//:)?(w{3}\.)?.*\.\w{3}', 'https://www.lsejg.lwegfoothill.edu.com').group()) """ 1-13 type()。 内置函数 type()返回一个类型对象,如下所示,该对象将表示为一个Pythonic类型的字符串。 >>> type(0) <type 'int'> >>> type(.34) <type 'float'> >>> type(dir) <type 'builtin_function_or_method'> 创建一个能够从字符串中提取实际类型名称的正则表达式。函数将对类似于<type'int' >的字符串返回 int(其他类型也是如此,如 'float' 、 'builtin_function_or_method' 等)。 注意: 你所实现的值将存入类和一些内置类型的__name__属性中。 """ print(re.search(r"^<type\s*'([a-zA-Z_]+)'\s*>$", "<type 'builtin_function_or_method'>").group(1)) # 1-14 处理日期。1.2 节提供了来匹配单个或者两个数字字符串的正则表达式模式,来表示 1~9 的月份(0?[1-9])。创建一个正则表达式来表示标准日历中剩余三个月的数字。 print(re.search('1[0-2]', '10').group()) ''' 1-15 处理信用卡号码。 1.2 节还提供了一个能够匹配信用卡(CC)号码([0-9]{15,16})的正则表达式模式。然而,该模式不允许使用连字符来分割数字块。 创建一个允许使用连字符的正则表达式,但是仅能用于正确的位置。例如, 15 位的信用卡号码使用 4-6-5 的模式,表明 4 个数字-连字符-6 个数字-连字符-5 个数字; 16 位的 信用卡号码使用 4-4-4-4 的模式。记住, 要对整个字符串进行合适的分组。 选做题:有一个判断信用卡号码是否有效的标准算法。编写一些代码,这些代码不但能够识别具有正确格式的号码, 而且能够识别有效的信用卡号码。 ''' print(re.search('([0-9]{4}-[0-9]{6}-[0-9]{5})|([0-9]{4}-[0-9]{4}-[0-9]{4}-[0-9]{4})', '0000-0923-0099-8899').groups())
# 1-17 判断在 redata.tex 中一周的每一天出现的次数(换句话说,读者也可以计算所选择的年份中每个月中出现的次数)。 # 分析,因为我们只需要一周的每一天,因此我们只需要得到前面的时间戳就ok了,后面直接.*匹配 import re file_path = 'redata.txt' pattr = '^(\w{3}).*' week = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'] week_dict = {key: 0 for key in week} print(week_dict) with open(file_path, 'rt', encoding='utf-8') as f: obj_list = [re.search(pattr, each_line.rstrip('\n')) for each_line in f] for obj in obj_list: if obj.group(1) in week_dict: week_dict[obj.group(1)] += 1 # print展示打印计算出来的结果 for key, value in week_dict.items(): print(key + '---->' + str(value))
# 1-18 通过确认整数字段中的第一个整数匹配在每个输出行起始部分的时间戳,确保在redata.txt 中没有数据损坏。 import re #Sun Mar 2 03:01:14 1997::akofd@sovto.gov::857242874-5-10 file_path = 'redata.txt' pattr = '^.*?(\d+\s\d{2}:\d{2}:\d{2}\s\d{4}).*' with open(file_path, 'rt', encoding='utf-8') as f: for each_line in f: print('时间戳为: ', re.search(pattr, each_line.rstrip('\n')).group(1))
import re data = 'Sun Mar 2 03:01:14 1997::akofd@sovto.gov::857242874-5-10' # 创建以下正则表达式。 # 1-19 提取每行中完整的时间戳。 pattr = '^.*?(\d+\s\d{2}:\d{2}:\d{2}\s\d{4}).*' # 1-20 提取每行中完整的电子邮件地址。 print(re.search(r'^.*?::(\w+@\w+\.(com|edu|net|org|gov)).*', data).group(1)) # 1-21 仅仅提取时间戳中的月份 print(re.search(r'^\w{3}\s(\w{3}).*', data).group(1)) # 1-22 仅仅提取时间戳中的年份。 print(re.search(r'.*?(\d{4}).*', data).group(1)) # 1-23 仅仅提取时间戳中的时间(HH:MM:SS)。 print(re.search(r'.*?(\d{2}:\d{2}:\d{2}).*', data).group(1)) # 1-24 仅仅从电子邮件地址中提取登录名和域名(包括主域名和高级域名一起提取)。 print(re.search(r'.*?@(\w+\.(com|edu|net|org|gov)).*', data).group(1)) # 1-25 仅仅从电子邮件地址中提取登录名和域名(包括主域名和高级域名)。 print(re.search(r'.*?@(\w+)\.(com|edu|net|org|gov).*', data).group(1)) print(re.search(r'.*?@(\w+)\.(com|edu|net|org|gov).*', data).group(2))
import re # 1-26 使用你的电子邮件地址替换每一行数据中的电子邮件地址。 with open('redata.txt', 'rt', encoding='utf-8') as f_read, \ open('redata.txt.bc', 'wt', encoding='utf-8') as f_write: for each_line in f_read: f_write.write(re.sub( r'(.*?::)(\w+@\w+\.(com|edu|net|org|gov))(.*)', r'\1(18279159836@163.com)\4', each_line.strip('\n') ) + '\n') import os os.remove('redata.txt') os.rename('redata.txt.bc', 'redata.txt')
import re # 1-27 从时间戳中提取月、日和年,然后以“月,日,年”的格式,每一行仅仅迭代一次。 with open('redata.txt', 'rt', encoding='utf-8') as f_read, \ open('redata.txt.bc', 'wt', encoding='utf-8') as f_write: for each_line in f_read: f_write.write(re.sub( r'^(\w{3})(\s)(\w{3})(.*)(\d{4})(.*)', r'\3\2\1\4\5\6', each_line.strip('\n') ) + '\n') import os os.remove('redata.txt') os.rename('redata.txt.bc', 'redata.txt')
import re # 处理电话号码。对于练习 1-28 和 1-29,回顾 1.2 节介绍的正则表达式\d{3}-\d{3}-\d{4},它匹配电话号码,但是允许可选的区号作为前缀。更新正则表达式,使它满足以下条件。 # 1-28 区号(三个整数集合中的第一部分和后面的连字符)是可选的,也就是说,正则表达式应当匹配 800-555-1212, 也能匹配 555-1212。 print(re.search('(\d{3}-)?\d{3}-\d{4}', '555-1212').group()) # 1-29 支持使用圆括号或者连字符连接的区号(更不用说是可选的内容);使正则表达式匹配 800-555-1212、 555-1212 以及(800) 555-1212。 print(re.search('((\d{3}-)?|\(\d{3}\))\s?\d{3}-\d{4}', '(800)555-1212').group())
# 正则表达式应用程序。下面练习在处理在线数据时生成了有用的应用程序脚本。 # 1-30 生成 HTML。提供一个链接列表(以及可选的简短描述),无论用户通过命令 # 行方式提供、 通过来自于其他脚本的输入,还是来自于数据库, 都生成一个 # Web 页面(.html),该页面包含作为超文本锚点的所有链接, 它可以在 Web 浏 # 览器中查看,允许用户单击这些链接,然后访问相应的站点。如果提供了简短 # 的描述,就使用该描述作为超文本而不是 URL。 # 1-31 tweet 精简。有时候你想要查看由 Twitter 用户发送到 Twitter 服务的 tweet 纯文本。 # 创建一个函数以获取 tweet 和一个可选的“元”标记,该标记默认为 False,然 # 后返回一个已精简过的 tweet 字符串,即移除所有无关信息,例如,表示转推的 # RT 符号、前导的“.”符号,以及所有#号标签。如果元标记为 True,就返回一 # 个包含元数据的字典。 这可以包含一个键“RT”, 其相应的值是转推该消息的用 # 户的字符串元组和/或一个键“#号标签”(包含一个#号标签元组)。如果值不存 # 在(空元组), 就不要为此创建一个键值条目。 # 1-32 亚马逊爬虫脚本。创建一个脚本,帮助你追踪你最喜欢的书,以及这些书在亚马 # 逊上的表现(或者能够追踪图书排名的任何其他的在线书店)。例如,亚马逊对于 # 任何一本图书提供以下链接: http://amazon.com/dp/ISBN(例如, http://amazon.com/ # dp/0132678209)。读 者可以改变域名,检查亚马逊在其他国家的站点上相同的图 # 书排名,例如德国(.de)、 法国(.fr)、 日本(.jp)、 中国(.cn) 和英国(.co.uk)。 # 使用正则表达式或者标记解析器,例如 BeautifulSoup、 lxml 或者 html5lib 来解析 # 排名,然后让用户传入命令行参数,指明输出是否应当在一个纯文本中,也许包 # 含在一个电子邮件正文中,还是用于 Web 的格式化 HTML 中。
六. re模块综合应用之计算器
参考博客:http://www.cnblogs.com/wupeiqi/articles/4949995.html
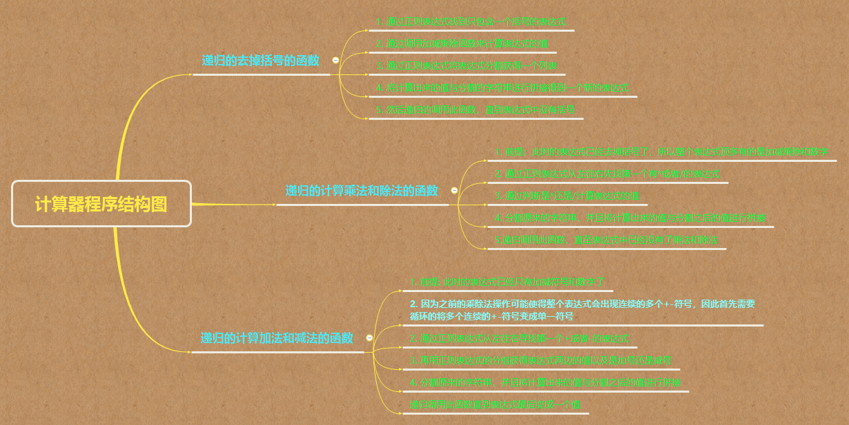
1. 计算器程序的逻辑图
2. 计算器的正则表达式
(1).递归去括号正则表达式的一步一步详细的解释
# 匹配数字的正则表达式,可以匹配到1, -1, -1.1, 1.1 r'-?\d+\.*\d*' # 首先应该匹配一对括号,括号不能包括括号 r'\(\)' # 然后我们不是匹配空括号的,括号内要需要表达式的,表达式就需要加减乘除,但是加减乘除中特殊字符,因此我们把它转义一下 r'\([\+\-\*\/]\)' # 匹配完操作符之后,就需要匹配数字了,将上面的匹配数字的正则表达式也放过来,但是这样的表达式只能匹配到带有加减乘除操作符的表达式 r'\([\+\-\*\/]-?\d+\.*\d*\)' # 因此我们再[]后面加上*之后,就可以匹配到单纯的数字了 r'\([\+\-\*\/]*-?\d+\.*\d*\)' # 大概的步骤都已经完成了,但是上面的操作是匹配不到'(1-2)'这样的字符串的,这是因为表达式只匹配了一次,而一个整数也是一个表达式 # 所以匹配不到,需要修改成下面这个样子 r'\(([\+\-\*\/]*-?\d+\.*\d*){2,}\)'
(2)递归乘除正则表达式详解
# r'\d+\.*\d*[*/]-?\d+\.*\d*' # 乘除的表达式比较简单,把正则表达式拆成三个部分 # 1. 乘除前面的是一个数字 r'\d+\.*\d*' # 2. 乘除后面的也是一个数字,只不过后面的数字必须要匹配一个-,为的是匹配5 * -4这样的表达式 r'-?\d+\.*\d*' # 3. 就是乘除符号了
递归加减的正则表达式和乘除的正则表达式思维是一样的,这里就不再赘述了
import re import time def computer_add_subtract(expression): """计算表达式中的加减法,然后将表达式中的值返回 expression: 只有加减法的表达式 """ # 因为在乘除运算的时候会多出来很多的+-号,因此应该先把加减号进行合并 while re.search('(\-\-)|(\+\+)|(\+\-)|(\-\+)', expression): expression = re.sub('\-\-', '+', expression) expression = re.sub('\+\+', '+', expression) expression = re.sub('\+\-', '-', expression) expression = re.sub('\-\+', '-', expression) content = computer_add_subtract_repr_obj.search(expression) if not content: return expression # 分割 before, after = computer_add_subtract_repr_obj.split(expression, 1) # before, after = re.split(pattr, expression, 1) # 计算获得的值, 首先匹配相应的表达式,然后根据分组获得相应的值 content = re.search('(\-?\d+\.*\d*)([+-])(\-?\d+\.*\d*)', content.group()).groups() if '+' == content[1]: result = float(content[0]) + float(content[2]) else: result = float(content[0]) - float(content[2]) # 拼接字符串 new_expression = '%s%s%s' % (before, result, after) return computer_add_subtract(new_expression) def computer_multiply_divide(expression): """计算表达式中乘除法,然后将重新拼接的字符串进行返回 expression: 表达式 """ content = computer_multiply_divide_repr_obj.search(expression) if not content: return expression # 分割字符串 before, after = computer_multiply_divide_repr_obj.split(expression, 1) # 获得表达式 content = content.group() # 判断是乘还是除法 if '*' in content: result = float(content.split('*')[0]) * float(content.split('*')[1]) else: result = float(content.split('/')[0]) / float(content.split('/')[1]) # 拼接字符串 new_expression = '%s%s%s' % (before, result, after) return computer_multiply_divide(new_expression) def compute(expression): """计算没有括号的表达式的值 expression: 表达式 """ # 先计算乘除法 temp_str = computer_multiply_divide(expression) # 乘除法计算完成之后返回的表达式就只有加减了,可以传递给加减的函数进行计算 result = computer_add_subtract(temp_str) # 最后返回结果 return result def deal_parentheses(expression): """递归处理掉整个表达式中的括号 expression: 传入的表达式 """ pattr = r'\(([+\-*/]*\d+\.*\d*){2,}\)' # 判断表达式中有没有括号 content = re.search(pattr, expression) if not content: return compute(expression) # 分割获得表达式的前面部分和后面部分,只是不太明白为什么这个地方为什么分割出来之后是3个值 before, nothing, after = re.split(pattr, expression, 1) # 获得表达式之后去括号并计算相应的值 content = content.group() content = content[1:-1] result = compute(content) # 拼接出新的表达式 new_expression = '%s%s%s' % (before, result, after) return deal_parentheses(new_expression) def calculator(expression): """计算器主程序 expression: 用户输入的表达式 """ print('请稍等,正在计算....') expression = re.sub('\s+', '', expression) start = time.time() res = deal_parentheses(expression) end = time.time() print('结果为>>', res, '时间为>>', end - start) if __name__ == '__main__': deal_parentheses_repr_obj = re.compile(r'\(([+\-*/]*\d+\.*\d*){2,}\)') computer_multiply_divide_repr_obj = re.compile(r'\d+\.*\d*[*/]-?\d+\.*\d*') computer_add_subtract_repr_obj = re.compile('\-?\-?\d+\.*\d*[\+\-]-?\d+\.*\d*') input_expression = '1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )' # input_expression = '1-2*-30/-12*(-20+200*-3/-200*-300-100)' calculator(input_expression)
