Python第五周 学习笔记(2)
发布时间:2019-09-13 09:26:30编辑:auto阅读(2602)
- 简化设计,函数的形参定义不包含可变位置参数、可变关键词参数和keyword-only参数
- 可以不考虑缓存满了之后的换出问题
1)原始
- 程序员可以方便的注册函数到某一个命令,用户输入命令时,路由到注册的函数
- 如果此命令没有对应的注册函数,执行默认函数
- 用户输入用input(">>")
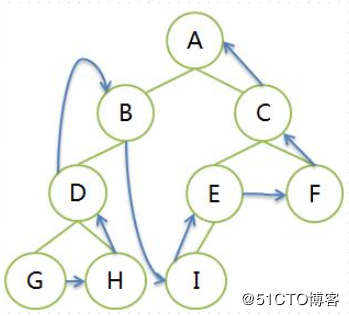
- 层序遍历,按照树的层次,从第一层开始,自左向右遍历元素
- 设树的根结点为D,左子树为L,右子树为R,且要求L一定在R之前,则有下面几种遍历方式:
- 前序遍历,也叫先序遍历、也叫先根遍历,DLR
- 中序遍历,也叫中根遍历,LDR
- 后序遍历,也叫后根遍历,LRD
- 遍历序列:将树中所有元素遍历一遍后,得到的元素的序列。将层次结构转换成了线性结构
- 从根结点开始,先左子树后右子树
- 每个子树内部依然是先根结点,再左子树后右子树。递归遍历
- 遍历序列
- A BDGH CEIF
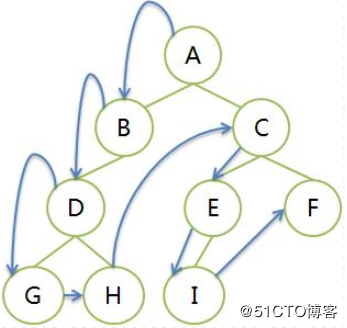
- A BDGH CEIF
- 从根结点的左子树开始遍历,然后是根结点,再右子树
- 每个子树内部,也是先左子树,后根结点,再右子树。递归遍历
- 遍历序列
- 左图
- GDHB A IECF
- 右图
- GDHB A EICF
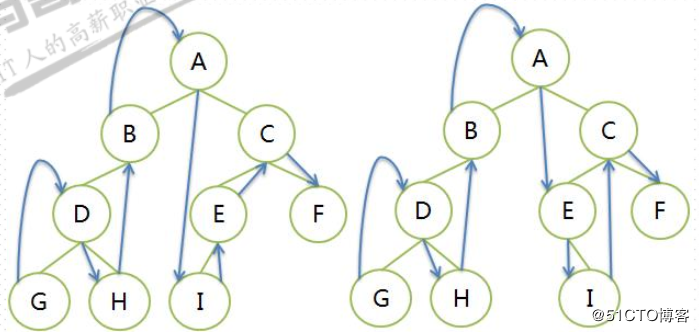
- 先左子树,后右子树,再根结点
- 每个子树内部依然是先左子树,后右子树,再根结点。递归遍历
- 遍历序列
- GHDB IEFC A
- GHDB IEFC A
- 堆是一个完全二叉树
- 每个非叶子结点都要大于或者等于其左右孩子结点的值称为大顶堆
- 每个非叶子结点都要小于或者等于其左右孩子结点的值称为小顶堆
- 根结点一定是大顶堆中的最大值,一定是小顶堆中的最小值
- 完全二叉树的每个非叶子结点都要大于或者等于其左右孩子结点的值称为大顶堆
- 根结点一定是大顶堆中的最大值
- 完全二叉树的每个非叶子结点都要小于或者等于其左右孩子结点的值称为小顶堆
- 根结点一定是小顶堆中的最小值
- 待排序数字为 30,20,80,40,50,10,60,70,90
- 构建一个完全二叉树存放数据,并根据性质5对元素编号,放入顺序的数据结构中
- 构造一个列表为[0,30,20,80,40,50,10,60,70,90]
- 度数为2的结点A,如果它的左右孩子结点的最大值比它大的,将这个最大值和该结点交换
- 度数为1的结点A,如果它的左孩子的值大于它,则交换
- 如果结点A被交换到新的位置,还需要和其孩子结点重复上面的过程
- 从完全二叉树的最后一个结点的双亲结点开始,即最后一层的最右边叶子结点的父结点开始结点数为n,则起始结点的编号为n//2(性质5)
- 从起始结点开始向左找其同层结点,到头后再从上一层的最右边结点开始继续向左逐个查找,直至根结点
- 确保每个结点的都比左右结点的值大
- 将大顶堆根结点这个最大值和最后一个叶子结点交换,那么最后一个叶子结点就是最大值,将这个叶子结点排除在待排序结点之外
- 从根结点开始(新的根结点),重新调整为大顶堆后,重复上一步
- 时间复杂度O(nlogn),平均时间复杂度O(nlogn)
- 空间复杂度O(1)
- 不稳定排序
装饰器应用练习
一、实现一个cache装饰器,实现可过期被清除的功能
def cache(fn):
import inspect
local_cache = {}
def wrapper(*args, **kwargs):
sig = inspect.signature(fn)
params = sig.parameters
param_names = list(params.keys())
temp_dict = {}
#处理位置参数
for k, v in enumerate(args):
temp_dict[param_names[k]] = v
#更新关键字参数值
temp_dict.update(kwargs)
#更新默认值
for k, v in params.items():
temp_dict[k] = v.default
#排序生成元组
temp_tuple = tuple(sorted(temp_dict.items()))
if temp_tuple not in local_cache.keys():
local_cache[temp_tuple] = fn(*args, **kwargs)
return local_cache[temp_tuple]
return wrapper
import time
@cache
def add(x, y, z):
time.sleep(2)
return x + y + z2)加入过期判断
import inspect
from datetime import datetime
def cache(duration):
def _cache(fn):
local_cache={}
def wrapper(*args, **kwargs):
def expire_cache(cache:dict):
expire_list = []
for k,(_,stamp) in cache.items():
delta = (datetime.now().timestamp() - stamp)
if delta > duration:
expire_list.append(k)
for k in expire_list:
cache.pop(k)
expire_cache(local_cache)
sig=inspect.signature(fn)
params=sig.parameters
param_names=list(params.keys())
param_dict={}
for k,v in enumerate(args):
param_dict[param_names[k]] = v
param_dict.update(kwargs)
for k, v in params.items():
if k not in param_dict.keys():
param_dict[k] = v.default
param_keys=tuple(sorted(param_dict.items()))
if param_keys not in local_cache.keys():
local_cache[param_keys]=(fn(*args,**kwargs), datetime.now().timestamp())
return local_cache[param_keys][0]
return wrapper
return _cache二、写一个命令分发器
def cmd_dispatcher(): #封装
cmd_dict = {}
def reg(cmd):
def _reg(fn):
cmd_dict[cmd] = fn
return fn
return _reg
@reg('default_func')
def default_func():
print('default')
return
def dispatcher():
while True:
cmd = input('>>')
if cmd == 'quit':
return
cmd_dict.get(cmd, default_func)()
return reg, dispatcher #封装
reg, dispatcher = cmd_dispatcher() #封装&解构
@reg('add')
def add(): #add=reg('add')(add)
print(1)
return
dispatcher()二叉树遍历
广度优先遍历
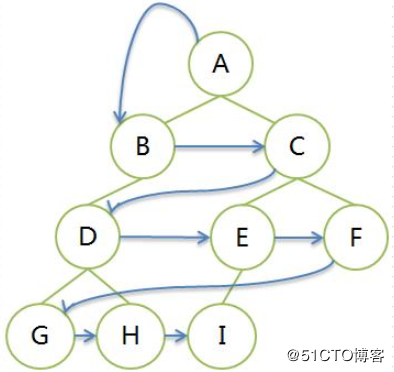
深度优先遍历
前序遍历DLR
中序遍历LDR
后序遍历LRD
堆排序
堆Heap
大顶堆
小顶堆
理论实现
1、构建完全二叉树
2、构建大顶堆——核心算法
2.1 构建大顶堆——起点结点的选择
2.2 构建大顶堆——下一个结点的选择
2.3 大顶堆的目标
3、排序
图片摘自Wiki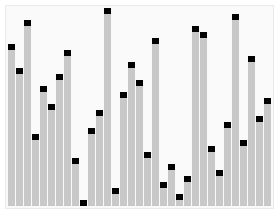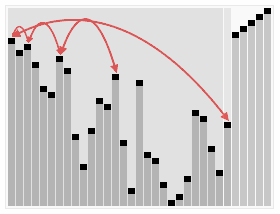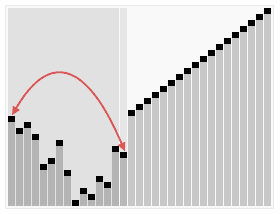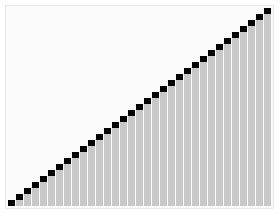
代码实现
1.打印树结构(非必要,方便查看每步操作对树结构的改变)
1)方法一 居中对齐
def show_tree(lst, unit_width=2):
from math import log2, ceil
length = len(lst)
depth = ceil(log2(length + 1))
width = 2 ** depth - 1
index= 0
for i in range(depth):
for j in range(2 ** i):
print('{:^{}}'.format(lst[index], width * unit_width), end = ' ' * unit_width)
index += 1
if index >= length:
break
width //= 2
print()2)方法二 投影栅格实现
from math import ceil, log2
#投影栅格实现
def print_tree(array):
'''
'''
index = 1
depth = ceil(log2(len(array)))
sep = ' '
for i in range(depth):
offset = 2 ** i
print(sep * (2 ** (depth - i -1) - 1), end = '')
line = array[index : index + offset]
for j, x in enumerate(line):
print("{:>{}}".format(x, len(sep)), end = '')
interval = 0 if i == 0 else 2 ** (depth - i) - 1
if j < len(line) - 1:
print(sep * interval, end = '')
index += offset
print()2.堆排序实现
def heap_sort(lst:list):
'''
堆排序
:type lst: list
:rtype: list
'''
length = len(lst)
lst.insert(0,0) # 前插0为了索引和结点号能够对应上,索引不必加一,便于理解,输出时切片即可
def heap_adjust(start, end):
'''
调整当前节点
调整结点的起点在n//2,保证所有调整结点都有孩子结点
:param end: 待比较个数
:param start: 当前节点下标
:rtype: None
'''
while 2 * start <= end: # 如果该结点下还有孩子则进入循环,否则跳出
lchild_index = 2 * start #该结点号*2 为左孩子结点
max_child_index = lchild_index #
if lchild_index < end and lst[lchild_index + 1] > lst[lchild_index]: # 如果有右孩子并且右孩子比左孩子的数大,则更新最大值索引
max_child_index = lchild_index + 1
if lst[max_child_index] > lst[start]: #孩子结点比较完后与父结点比较,最大值放到父结点,并且下一次迭代的父结点是本次最大孩子索引
lst[start], lst[max_child_index] = lst[max_child_index], lst[start]
start = max_child_index
else: # 如果父结点最大则直接跳出,因为排顶堆从编号最大的子树开始调整,即保证了本次最大孩子结点与其孩子结点已经形成了顶堆
break
for st in range(length//2, 0, -1): # 调整为大顶堆
heap_adjust(st, length)
for end in range(length, 1, -1): #sort排序 根结点与最后结点交换,每次迭代刨除最后结点,直至只剩根结点
lst[1], lst[end] = lst[end], lst[1]
heap_adjust(1, end - 1)
return lst[1:]
上一篇: Python将数据库数据导入到EXCEL
下一篇: python实现图形界面执行linux命
- H3C基本命令大全
53518
- H3C IRF原理及 配置
40346
- Python exit()函数
34747
- python全系列官方中文文档
30503
- python 获取网卡实时流量
25378
- 1.常用turtle功能函数
25177
- python 获取Linux和Windows硬件信息
23589
- 天天基金网数据接口
18858
- Selenium使用代理IP&无头模式访问网站
15170
- Selenium&Pytesseract模拟登录+验证码识别
14676
- LangGraph Studio可视化
1144°
- LangSmith开发-应用入门
1067°
- LangGraph开发-多轮对话问答机器人
1136°
- LangGraph开发-条件分支/循环图实战
1152°
- LangGraph开发-生态介绍,入门demo实战
1188°
- LangChain-接入12306-HTTP MCP智能体
1344°
- LangChain接入自定义爬虫-MCP工具
1303°
- LangChain接入Filesystem-MCP工具
1277°
- LangChain搭建MCP服务端和客户端流程
1376°
- LangGraph与MCP技术概述
1319°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
