Python自动化开发学习12-Mari
发布时间:2019-09-13 09:24:05编辑:auto阅读(2431)
- Oracle : 甲骨文公司的企业级的数据库
- SQL Server : 微软的
- MySQL : 免费的数据库,现在也属于Oracle的旗下产品
- MariaDB : 开源的数据库,MySQL的一个分支
- PostgreSQL : 也是开源的
- SQLite : 一款轻量级的数据库
- DB2 : IBM的
- 数据库: 数据库是一些关联表的集合。.
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据,例如邮政编码的数据。
- 行: 一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余: 存储两倍数据,冗余可以使系统速度更快。(表的规范化程度越高,表与表之间的关系就越多;查询时可能经常需要在多个表之间进行连接查询;而进行连接操作会降低查询速度。例如,学生的信息存储在student表中,院系信息存储在department表中。通过student表中的dept_id字段与department表建立关联关系。如果要查询一个学生所在系的名称,必须从student表中查找学生所在院系的编号(dept_id),然后根据这个编号去department查找系的名称。如果经常需要进行这个操作时,连接查询会浪费很多的时间。因此可以在student表中增加一个冗余字段dept_name,该字段用来存储学生所在院系的名称。这样就不用每次都进行连接操作了。)
- 主键: 主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键: 外键用于关联两个表。
- 复合键: 复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引: 使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
- USE 数据库名 : 选择要操作的Mysql数据库,使用该命令后所有Mysql命令都只针对该数据库。
- SHOW DATABASES : 列出 MySQL 数据库管理系统的数据库列表。
- SHOW TABLES : 显示指定数据库的所有表,使用该命令前需要使用 use命令来选择要操作的数据库。
- SHOW COLUMNS FROM 表名 : 显示数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息。
- DESC 表名 : 同上,貌似一般都用这个
- CREATE DATABASE 库名 CHARSET "utf8" : 创建一个支持中文的数据库
- SHOW CREATE DATABASE 库名 : 上面创建后,查看这个库的字符编码。默认是'latin1'。
- DROP DATABASE 库名 : 删除数据库
- SHOW INDEX FROM 表名 : 显示数据表的详细索引信息,包括PRIMARY KEY(主键)。
- 创建表 :
CREATE TABLE 表名 (表结构,主键); - 插入数据 :
INSERT INTO 表名 (字段名列表) VALUES (值的列表); - 查询数据 :
SELECT 字段名 FROM 表名; - 修改数据 :
UPDATE 表名 SET 字段名1=值[, 字段名2=值 ...] [WHERE语句]; - 删除数据 :
DELETE FROM 表名 [WHERE语句];,如果没有WHERE,所有记录都将被删除 - WHERE : 查询的条件
- OFFSET : 开始查询数据的偏移量,可以不用每次都从头开始查
- LIMIT : 设定返回的记录数
- DESC : 查询结果降序排列,默认是升序(ASC,ASC默认缺省,加不加都一样)
- GROUP BY : 将数据进行分组
- 删除字段 :
ALTER TABLE 表名 DROP 字段名; - 添加字段 :
ALTER TABLE 表名 ADD 字段名 字段类型;,新字段添加在表的末尾。- 加到开头:最后再加上FIRST
- 加到指定位置:最后加上AFTER 字段名,就是插入到指定字段名的后面。
- FIRST 和 AFTER 关键字只作用于 ADD 子句。所以无法调整字段位置,或先 DROP 删除然后再 ADD 添加并设置位置
- 修改字段类型 :
ALTER TABLE 表名 MODIFY 字段名 字段新类型;ALTER TABLE 表名 MODIFY 字段名 BIGINT NOT NULL DEFAULT 100;, 设定字段类型为BIGINT,并且不能为空默认值100。如果不设置默认值,则自动设置该字段默认为 NULL。
- 修改字段名及类型 :
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 字段新类型; - 修改字段默认值 :
ALTER TABLE 表名 ALTER 字段名 SET DEFAULT 默认值; - 删除字段默认值 :
ALTER TABLE 表名 ALTER 字段名 DROP DEFAULT; - 修改表名 :
ALTER TABLE 表名 RENAME TO 新表名; - IS NULL : 当列的值是NULL,此运算符返回true。
- IS NOT NULL : 当列的值不为NULL, 运算符返回true。
- <=> : 比较操作符(不同于=运算符),当比较的的两个值为NULL时返回true。
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。默认缺省 INNER 就是这个。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
- FULL JOIN : 没有这句命令,不直接支持,但是可以实现
- 只有使用了Innodb数据库引擎的数据库或表才支持事务,默认使用的数据库引擎就是Innodb。
- 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
- 事务用来管理 INSERT, UPDATE, DELETE 语句。没有 SELECT 因为并不会对表进行修改
- 原子性 : 一组事务,要么成功;要么撤回。
- 稳定性 : 有非法数据(外键约束之类),事务撤回。
- 隔离性 : 事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 可靠性 : 软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit 选项决定什么时候吧事务保存到日志里。
- 隐藏了数据访问细节,“封闭”的通用数据库交互是ORM的核心。他使得我们与通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
- 讲师视图
- 管理班级,可创建班级,根据学员qq号把学员加入班级
- 可创建指定班级的上课纪录,注意一节上课纪录对应多条学员的上课纪录,即每节课都有整班学员上,为了纪录每位学员的学习成绩,需在创建每节上课纪录时,同时为这个班的每位学员创建一条上课纪录
- 为学员批改成绩, 一条一条的手动修改成绩
- 学员视图
- 提交作业
- 查看作业成绩
- 一个学员可以同时属于多个班级,就像报了Linux的同时也可以报名Python一样,所以提交作业时需先选择班级,再选择具体上课的节数
- 附加:学员可以查看自己的班级成绩排名
关系型数据库
主流的关系型数据库大概有下面这些:
RDBMS 术语
RDBMS(Relational Database Management System)即关系数据库管理系统,在开始之前,先了解下RDBMS的一些术语:
MariaDB安装
直接使用yum来安装:
$ yum groupinstall mariadb mariadb-client开启服务,以及开启自启动:
$ systemctl start mariadb
$ systemctl enable mariadb安装后建议运行一下安全加固:
$ mysql_secure_installation几个交互式的问答,可以设置root密码。其他都可以选yes,主要是删除匿名用户登录,关闭root账号远程登录,删除test库。
如果需要被远程访问,还要开启防火墙:
$ firewall-cmd --permanent --add-service=mysql
$ firewall-cmd --reload配置文件
/etc/my.cnf 这个文件就是配置文件,一般情况下,你不需要修改该配置文件。
如果你的数据库是单机运行的,那么建议关闭联网,具体就是添加一行配置:
在 [myslqd] 中加一行, skip-networking=1
基本操作
太具体的例子和语句就不一个一个试了,就在下面列出常用的操作和命令简单的语法。太复杂的查询语句还是在需要的时候再上网查吧。
账号
登录数据库:
$ mysql [-u root] [-h localhost] -p[PASSWORD]注意-p后面可以不跟密码,这样可以在之后的交互界面输入密文的密码。也可以在-p后面直接跟上明文的密码,但是中间不要用空格
-u 缺省就是root登录, -h 缺省就是登录到localhost
用户账户记录在mysql库的user表里,权限在db表里。
创建一个用户,并且设置账号权限:
> GRANT SELECT, UPDATE, DELETE, INSERT ON 库名.表名 TO 用户名@主机 INDENTIFIED BY '密码' ;也可以赋予完全的权限,比如创建一个admin账号,赋予所有的权限:
> GRANT ALL PRIVILEGES ON *.* TO admin IDENTIFIED BY 'admin123';账号权限有很多,最常用的就是增删改查的操作,所有的权限可以看db表:
> USE mysql
> DESC db;查看账号权限:
> SHOW GRANTS [for 用户名@主机];查看有多少账号:
> SELECT user, host FROM user;
> SELECT * FROM user \G; # 或者查看全部,不过内容比较多,用\G参数按列打印删除账户:
DEOP USER 用户名@主机;最后注意,账号的设置不会马上生效。重启一下服务最保险,或者:
> FLUSH PRIVILEGES;命令
以下列出了使用Mysql数据库过程中常用的命令:
操作
创建表,然后进行增删改查的操作,简单列一下:
使用下面的语句,加到SELECT语句后面,设置查询条件或者输出额:
ALTER命令,修改数据表名或者修改数据表字段使用的命令。
ALTER 命令不只上面这些,还可以用来创建及删除数据表的索引,先这样吧。
外键关联
先准备好数据,顺便复习前面的内容:
> CREATE DATABASE week12 CHARSET utf8; # 创建数据库
> USE week12按照下面的表,创建表格
学生信息表(student):
| id | name | age |
|---|---|---|
| 1 | Adam | 36 |
| 2 | Bob | 32 |
| 3 | Clare | 27 |
| 4 | Dan | 26 |
> CREATE TABLE student (
-> id INT UNSIGNED AUTO_INCREMENT,
-> name VARCHAR(20) NOT NULL,
-> age TINYINT,
-> PRIMARY KEY (id)
-> );然后插入数据:
> INSERT INTO student (name, age) VALUES ('Adam', 36);再创建下面的这张考勤表。考勤表中的 student_id 要和学生信息表这的 id 建立外键关联。
考勤表(record):
| day | student_id | checkin | late | level_early |
|---|---|---|---|---|
| 2018-01-01 | 1 | 1 | 0 | 0 |
| 2018-01-01 | 2 | 1 | 0 | 0 |
| 2018-01-01 | 3 | 1 | 0 | 0 |
| 2018-01-02 | 1 | 1 | 0 | 0 |
| 2018-01-02 | 2 | 1 | 0 | 0 |
| 2018-01-02 | 3 | 1 | 0 | 0 |
> CREATE TABLE record(
-> day DATE,
-> student_id INT UNSIGNED,
-> checkin BOOL,
-> late BOOL,
-> level_early BOOL,
-> PRIMARY KEY (day, student_id),
-> KEY fk_student_key (studeng_id),
-> CONSTRAINT fk_student_key FOREIGN KEY (student_id) REFERENCES studnet (id)
-> );尝试添加记录:
> INSERT INTO record (day, student_id, checkin, late, level_early) VALUES ('2018-1-2', 3, 1 ,0, 0);record表的主键是 (day, student_id) ,这是一个复合主键。所以日期和id都可以重复出现,但是同一日期不下不能由相同的id。
无法在record表中插入在student表中不存在的student_id,这个叫外键约束
尝试删除记录:
> DELETE FROM record WHERE day='2018-01-01' AND student_id=1; # 这条没问题
> DELETE FROM student WHERE name LIKE 'Adam'; # 这条数据如果被关联了,就无法删除。查询表的外键关联,通过查看建表的语句就能看到外键的SQL语句> SHOW CREATE TABLE record;
然后被关联的表可以用下面的语句查询到关联关系> select * from INFORMATION_SCHEMA.KEY_COLUMN_USAGE where REFERENCED_TABLE_NAME='student';
NULL 值处理
我们已经知道数据库使用 SELECT 命令及 WHERE 子句来读取数据表中的数据,但是当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作。
关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。用下面的 IS NULL 和 IS NOT NULL。NULL值与任何其它值的比较(即使是NULL)永远返回false,即 NULL = NULL 也返回 false 。
为了处理这种情况,使用如下的三大运算符:
多表查询
上面例子中的2个表,要输出一张考勤表,但是考勤表中没有name字段。想要name字段需要根据student_id到student表中查找对应的id获取。这就需要多表联合查询
> SELECT * FROM record, student WHERE record.student_id = student.id; # 也可以使用JOIN方法或者也可以使用JOIN。另外只需要从student表中取到name字段,别的字段不需要。SELECT * 也可以修改一下:
> SELECT record.*, student.name FROM record, student WHERE record.student_id = student.id;
> SELECT record.*, student.name FROM record JOIN student ON record.student_id = student.id;上面的2句一样。
另外JOIN其实分4种类:
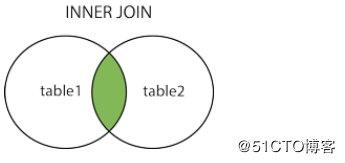
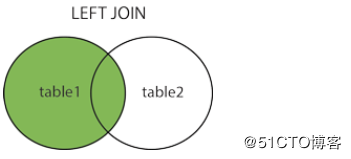
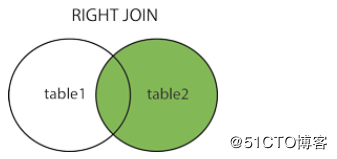
多表联查的2张表不需要有外键关联。由于上面建立的2张表建立了外键关联,record表中的student_id一定是在student表中的,所以上面 JOIN 语句使用 LEFT 是不会有更多记录的。但是使用 RIGHT,会把record表中没有记录的student的name也生成一条记录。
SELECT record.*,student.name FROM record RIGHT JOIN student ON record.student_id = student.id;间接实现FULL JOIN的方法就是做 LEFT JOIN 和 RIGHT JOIN 各做一次,然后把结果拼起来就是了:
> SELECT record.*,student.name FROM record LEFT JOIN student ON record.student_id = student.id
-> UNION
-> SELECT record.*,student.name FROM record RIGHT JOIN student ON record.student_id = student.id;FULL JOIN 知道就行了,因为貌似也没啥用。
事务
事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务。再比如上面的例子,你如果要删除一个学生,还需要先删除这个学生的考勤记录,这就是2个步骤。我们希望这2个步骤可以都完成。如果完成了考勤记录的删除,但是之后删除学生的时候出现了问题,那么可以会退到整个删除过程之前的状态,既恢复之前删除的考勤记录。直白一点,就是一列的操作,所有的步骤要么都成功,要么一个都不执行。
一般来说,事务需要满足4个条件(ACID):
操作起来很简单:
> BEGIN; # 声明开始一个事务
> INSERT INTO student (name, age) VALUES ('Frank', 18); # 执行一些操作,这里就插入一条记录
> ROLLBACK; # 回滚,如果数据是不会写入的,回到初始得状态
> COMMIT; # 提交,如果数据没有问题就执行提交而不是回滚另外如果步骤比较多还可以设置多个临时保存点,可以进行回滚:
保存点(Savepoint) : 事务集中的一个临时占位符,可进行回滚。
> SAVEPOINT delete1; # 设置保存点
> ROLLBACK TO delete1; # 回滚到保存点索引
索引的建立对于数据库的高效运行是很重要的,索引可以大大提高数据的检索速度。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索包含多个列。
上面是使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
查看索引:
> SHOW INDEX FROM student [\G]; # 看不清楚,就加上\G即时还没有创建过索引,但是依然能查看到索引信息。因为默认已经对主键做了索引了。
创建索引:
> CREATE INDEX index_name ON student(name(5)); # 创建单列索引,长度可以缺省
> CREATE INDEX index_name_age ON student (name,age); # 创建联合索引,这里缺省了长度索引也是一张表,所以要取一个索引名(‘index_name’)。然后要指定一下长度(例子中是5,也可以缺省)。如果是CHAR,VARCHAR类型,长度可以小于字段实际长度(或者不写);如果是BLOB和TEXT类型,必须指定长度。
删除索引:
> DROP INDEX index_name ON student; # 删除索引用ALTER添加、删除索引:
> ALTER TABLE student ADD INDEX index_name(name); # 这里就缺省了长度,也可以加上
> ALTER TABLE student DROP INDEX index_name; # 删除索引另外,在创建表的时候也可以指定索引。
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。要创建唯一索引,只需要加上UNIQUE这个关键字就好了:
> CREATE UNIQUE INDEX index_name ON student(name(10)); # 加上UNIQUE
> ALTER TABLE student ADD UNIQUE [INDEX] index_name(name(10)); # 这里可以缺省INDESPyMySql 模块
这是一个第三方库,需要安装。使用的时候基本都是用源生SQL语句来操作数据库。
连接查询数据库:
import pymysql
conn = pymysql.connect(host='192.168.246.134', port=3306,
user='operator', passwd='operator123',
db='week12') # 创建连接
cursor = conn.cursor() # 创建游标
effect_row = cursor.execute('SELECT * FROM student') # 执行SQL语句
print(effect_row) # 返回值是受影响的行数
print(cursor.fetchone()) # 获取1条
print(cursor.fetchmany(2)) # 获取多条
print(cursor.fetchall()) # 获取所有
cursor.close() # 关闭游标
conn.close() # 关闭连接这里执行SQL命令的方法excute,有2个参数。第一个是SQL语句的字符串。第二个参数上面是缺省的。
插入数据:
import pymysql
conn = pymysql.connect(host='192.168.246.134', port=3306,
user='operator', passwd='operator123',
db='week12') # 创建连接
cursor = conn.cursor() # 创建游标
effect_row = cursor.execute("INSERT INTO student (name, age) "
"VALUES ('Gina', 20)") # 执行SQL语句
effect_row = cursor.execute("INSERT INTO student (name, age) VALUES (%s, %s)",
('Helena', 21)) # 变量可以作为第二个参数写成一个元组
print(effect_row) # 一次插入1行,所以返回值是1
conn.commit() # 必须提交,默认都是事务操作
cursor.close() # 关闭游标
conn.close() # 关闭连接这里注意,默认所有的修改操作都是事务,所以执行后得提交,否则不会生效。
还可以一次插入多条数据,用 executemany 执行多条:
import pymysql
conn = pymysql.connect(host='192.168.246.134', port=3306,
user='operator', passwd='operator123',
db='week12') # 创建连接
cursor = conn.cursor() # 创建游标
student_list = [('Ivy', 21), ('Jimmy', 22), ('Kane', 23)] # 数据的列表
effect_row = cursor.executemany("INSERT INTO student (name, age) VALUES (%s, %s)",
student_list) # 把列表直接作为第二个参数
print(effect_row) # 一次插入3行,所以返回值是3
conn.commit() # 必须提交,默认都是事务操作
cursor.close() # 关闭游标
conn.close() # 关闭连接SQLAlchemy 模块
现在已经可以使用SQL语句通过python来操作数据库了。但是我并不是专业的DBA,使用SQL语句并不熟练(复杂点的语句可能写出来,根本不能执行)。我还需要更高级的封装。
ORM介绍
全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
ORM的优点:
ORM的缺点:
SQLAlchemy 操作数据库
首先,这也是一个第三方库,使用前需要安装。
在Python中,最有名的ORM框架是SQLAlchemy。该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
SQLAlchemy本身无法操作数据库,其必须通过pymsql等第三方插件,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
mysql 通过 PyMySQLbr/>`mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]`
SQL Server 通过 pymssqlbr/>`mssql+pymssql://<username>:<password>@<freetds_name>/?charset=utf8`
Oracle 通过 cx_Oraclebr/>`oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]`
去官网查看更多支持的数据库,以及操作这些数据的模块:http://docs.sqlalchemy.org/en/latest/dialects/index.html
如此,我们只要通过ORM,就可以操作任何他支持的数据库了。并且可以把数据库当做我们的数据对象来处理,而不需要了解数据库本身的语句。
创建表
创建一张表:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
engine = create_engine("mysql+pymysql://admin:admin123@192.168.246.12/week12",
encoding='utf-8', echo=True) # 这里设置了echo参数,显示中间过程和SQL语句
Base = declarative_base() # 生成orm基类
class User(Base):
__tablename__ = 'user' # 表名
id = Column(Integer, primary_key=True)
name = Column(String(32))
password = Column(String(64))
Base.metadata.create_all(engine) # 创建表结构,这里是通过父类来调用子类注意一下账号权限,root账号默认是只能本地登录了,最好也不要开放给远程。确保你使用的账号有远程登录的权限(如果你不是本地登录操作的话)。另外确保你的账号有创建表的权限(一般操作用的账号只分配增删改查的权限就好了)。
设置了echo参数,会打印很多额外的信息,使用的时候可以关闭去掉这个参数。
创建成功后重复运行不会再创建或者覆盖,也不会报错。
插入数据
要插入数据,前面创建表的整段代码都要抄下来。先是连接数据库,然后是声明表结构一句都不能少。除了最后一句create_all可以不写(写上也没事,这句是创建表,但是表已经存在的情况下,不会创建也不会报错)
暂时不要用中文,使用中文的方法在最后
插入数据:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
engine = create_engine("mysql+pymysql://admin:admin123@192.168.246.12/week12",
encoding='utf-8', echo=True) # 这里设置了echo参数,显示中间过程和SQL语句
Base = declarative_base() # 生成orm基类
class User(Base):
__tablename__ = 'user' # 表名
id = Column(Integer, primary_key=True)
name = Column(String(32))
password = Column(String(64))
Base.metadata.create_all(engine) # 可写可不写。写上,如果该表不存在就创建
# 上面是连接数据库和声明表结构
# 下面是插入数据
Session_class = sessionmaker(bind=engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
session = Session_class() # 生成session实例
user_obj = User(name="Jerry", password="jerrypass") # 生成你要创建的数据对象
session.add(user_obj) # 把要创建的数据对象添加到这个session里, 一会统一创建
session.commit() # 现此才统一提交,创建数据上面的例子中,先生成一个Session实例,然后通过操作这个实例来插入数据。增删改查的操作,都是同个这个Session来完成的。
这里用的是 add(obj) ,还可以使用 add_all(list) ,来加入一组数据。参数是列表,列表中的每一个元素是需要插入的一条数据。
查询数据
查询数据:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
engine = create_engine("mysql+pymysql://operator:operator123@192.168.246.12/week12",
encoding='utf-8', echo=False) # 这里设置了echo参数,显示中间过程和SQL语句
Base = declarative_base() # 生成orm基类
# 这里我把表换成了之前创建的student表,里面有之前创建的数据
# id字段的主键必须要声明,否则会报错。
class Student(Base):
__tablename__ = 'student' # 表名
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
Base.metadata.create_all(engine) # 可写可不写。写上,如果该表不存在就创建
Session_class = sessionmaker(bind=engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
session = Session_class() # 生成session实例
# 上面都一样
data = session.query(Student).filter_by(id=3).all() # 如果去掉filter_by括号中的内容,就是查询所有
print(data) # 目前打印结果只是一个对象上面例子中使用了 .all() 输出所有,也可以使用 .first() 只输出一条。
查询条件有 'filter_by()' 和 'filter()' 。如果参数为空,就是查询所有,2种语法没有差别。
详细讲一下 filter() ,使用SQL表达式。
单个条件, filter(Student.name == 'Bob'),
多个条件,用逗号隔开或者写多个filter串起来,都是AND的意思 : filter(Student.id < 6, Student.age > 30) 或者 filter(Student.id < 6).filter(Student.age > 30) 。
多个条件使用OR:
from sqlalchemy import or_ # 需要导入这个
filter(or_(Student.id == 1, Student.age < 20))使用in匹配 : filter(Student.name.in_(['Bob', 'Eve'])) ,filter(~Student.name.in_(['Bob', 'Eve'])) 前面加个~是not in。
使用like匹配 : filter(Student.name.like('%y'))
最终极的办法就是用原生SQL的语法了:
from sqlalchemy import text # 需要导入这个
data = session.query(User).filter(text("id > 1 and name Like '%m%'")).all() # 然后就按原生的语法那么写filter_by() : 使用关键参数表达式。filter_by(name='Bob'),filter_by(name='Bob', id=3)。貌似查不了多条,只能用等于,没细讲。
差不多了,更多的情况,用到了再查吧。
打印查询结果
上面打印出来得只是对象,并不是表的内容。既然有对象了,只需要用操作对象的方法就好了。
查询到的记录数量,可以通过 len(data) 获取到。要打印结果需要重构类的 __repr__ 方法。
class Student(Base):
__tablename__ = 'student' # 表名
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
def __repr__(self):
return "<Student(id='%s', name='%s', age='%s')>" % (
self.id, self.name, self.age)
data = session.query(Student).filter(Student.name.like('%y')).all() # 如果去掉filter_by括号中的内容,就是查询所有
print(len(data)) # 返回的记录数量
print(data) # 打印所有的数据还可以用取对象属性的方法打印出表的内容,
data = session.query(Student).filter(Student.name.like('Bob')).all() # 用all返回所有,data就是所有对象的列表
print(type(data), len(data)) # 返回的记录数量,这里的data类型是列表,data[0]才是对象
print(data[0].id, data[0].name, data[0].age) # 如果是多条,我们可以写for循环
data = session.query(Student).filter(Student.name.like('Bob')).first() # 用first只返回第一条。data就是对象
print(type(data)) # 这里data是对象,没有len
print(data.id, data.name, data.age) # 直接打印data的属性
print(data.__dict__) # 既然是对象,我们可以打印它所有的属性值修改数据
修改数据:
直接操作对象,给对象赋值就完成了数据的修改,最后调用commit()写入。
data = session.query(Student).filter(Student.name.like('Dan')).first() # 用first只返回第一条。data就是对象
print(data.id, data.name, data.age) # 打印看看
data.name = 'Dennis' # 这里就当做普通对象一样操作
data.age += 1 # 我们来加1岁
session.commit() # 最后要提交才生效上面的方法只能改1条,你用个all(),然后也能修改多条。
另外还可以用update修改,用法如下:
data = session.query(Student).filter(Student.name == 'Dennis').update(
{Student.name: 'David', Student.age: Student.age+1}) # update用字典的形式赋值
session.commit()
print(data) # 返回值是修改的记录数删除数据
直接像上面的update方法那样,调用一个delete方法。因为是删除,所以delete()就好了,不需要参数
data = session.query(Student).filter(Student.name == 'David').delete() # 直接改成delete即可
session.commit()
print(data) # 返回值是修改的记录数回滚
模块所有的修改操作都是通过事务来执行的,之前每次操作完成后,都需要加上commit()执行一下提交。在提交之前,也可以使用rollback()执行回滚。通过自增id的变化,印证了是通过事务来实现的。
data = session.query(Student).filter().all() # 其实用降序排列,取第一条就可以了。现在降序还不会
print(data[len(data)-1].id) # 这个是最后一条记录的id
obj = Student(name='Dan', age=29)
session.add(obj) # 插入数据
data = session.query(Student).filter(Student.name == 'Dan').first()
print(data.id, data.name) # 注意这个id,所以这个id已经生成并且并用掉了
session.rollback() # 不提交而是回滚
data = session.query(Student).filter(Student.name == 'Dan').first()
print(data) # 此时为None,添加的数据没了
obj = Student(name='Dennis', age=30)
session.add(obj) # 再插入数据
session.commit() # 这次提交
data = Session.query(Student).filter().all()
print(data[len(data)-1].id, data[len(data)-1].name) # 再看看新记录的idSQLAlchemy 进阶操作
试完了增删改查的基本操作后,看看一些别的操作。
分组和统计
统计用 count :
data = session.query(Student).filter(Student.name.like('%y')).all() # 用all返回所有,data就是所有对象的列表
print(data, len(data))
count = session.query(Student).filter(Student.name.like('%y')).count() # 使用count方法实现统计
print(count) # 这个还是满足条件的记录的 数量,意义貌似不大分组用 group_by :
from sqlalchemy import func # 这里的统计需要导入这个
data = session.query(func.count(Student.age), Student.age, func.sum(Student.age)).group_by(Student.age).all()
print(data) # query里的参数,就是输出的元祖的每一个元素,其中func.count是记录的数量。上面还试了一个sum对query参数的理解
到这里对query有了新的认识。query里的参数,就是输出的内容。之前的参数都是类名,结果就是一个对象。这里直接把属性和方法放到query中,就直接获取到属性和方法的值了。
class Student(Base):
__tablename__ = 'student' # 表名
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
# 上面我没有重构__repr__方法
data = session.query(Student.id, Student.name, Student.age).filter().first() # 用all的区别就是所有的元素再组成一个列表
print(data) # 现在data的内容就是query中定义的,是一个元祖对表的class类的理解
这里主要是class里的每个字段的类型,
任何时候主键的声明都不能缺省
创建表的时候需要详细的写明类型包括大小,
查询的时候只需要声明主键,类型可以缺省,全部用 Column()。
插入表的时候,也要写明类型,否则ORM不知道这个字段是数字还是字符串。但是不写大小是可以的
总结,所以创建表的时候对类的要求是最严的。实际使用的时候,在创建表的时候把类定义好(即使表已经存在也定义一下),其他操作的时候直接import这个类就好了。如果不是使用本系统的表,而是使用其他系统的表,那就只是查询,只需要知道字段名就好了,用 Column()。
多表查询
下面是SQL中的JOIN语句,这里SELECT * 就好了,我们可以用代码实现输出内容的筛选。> SELECT * FROM record JOIN student ON record.student_id = student.id;
对应的python代码:
class Student(Base):
__tablename__ = 'student' # 表名
id = Column(primary_key=True) # 只要声明你需要的字段名,主键必须声明
name = Column() # 字段类型可以不要,我们不是创建表
# age = Column() # 不需要的字段也可以不要
class Record(Base):
__tablename__ = 'record'
day = Column(primary_key=True)
student_id = Column(primary_key=True)
checkin = Column
late = Column
level_early = Column
def __repr__(self):
return "<Record(day='%r', checkin='%r', late='%r', level_early='%r')>" % (
self.day, bool(self.checkin), bool(self.late), bool(self.level_early))
data = session.query(Record, Student).filter(Record.student_id == Student.id).all() # 这句就是SQL的JOIN
print(data[0][1].name, data[0][0])上面是不需要任何关联关系的时候可以使用的方法。另外还有个join方法,需要有外键关联。先往下看。
外键关联
关联关系主要分三种情况:一对一、一对多/多对一、多对多
一对一
创建外键关联需要导入 from sqlalchemy import ForeignKey
下面是创建被关联的表的时候用的SQL语句:
> CREATE TABLE student (
-> id INT UNSIGNED AUTO_INCREMENT,
-> name VARCHAR(20) NOT NULL,
-> age TINYINT,
-> PRIMARY KEY (id)
-> );再创建一张表考试分数的表,关联id:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy import ForeignKey # 外键关联需要这个
from sqlalchemy.dialects.mysql import INTEGER # 要使用无符号的整数
engine = create_engine("mysql+pymysql://admin:admin123@192.168.246.12/week12",
encoding='utf-8', echo=True)
Base = declarative_base() # 生成orm基类
class Student(Base):
__tablename__ = 'student' # 表名,这张表不创建,可以写的简单点
id = Column(primary_key=True) # 只要声明你需要的字段名,主键必须声明
name = Column() # 字段类型可以不要,我们不是创建表
age = Column()
class Exam(Base):
__tablename__ = 'exam'
name = Column(String(32), primary_key=True)
student_id = Column(INTEGER(unsigned=True), ForeignKey("student.id"), primary_key=True) # 声明外键关联
score = Column(Integer, nullable=False) # 规定不能为空
Base.metadata.create_all(engine) # 创建表上面踩了个坑。要建立关联,需要保证被关联的字段类型和长度是一样的。student表创建时用了无符号的数字这个数据类型,所以创建的新表的类型也得一致,要使用这个类型就得导入 from sqlalchemy.dialects.mysql import INTEGER 。这个类型就是无符号的数字类型。数据类型一致后成功创建了包含外键关联的新表。
只是创建还不够,我们还要使用。上面的Exam类中少写了一行代码。通过relationship,声明关联的表之间的关系,并且可以通过这个关系互相调用被关联的表的属性值。这个relationship也需要再导入模块。
首先,先确保我们新创建的Exam表中有数据:
| name | student_id | score |
|---|---|---|
| test1 | 1 | 94 |
| test2 | 1 | 92 |
现在可以通过建立的关联,查询考试的成绩,把student_Id通过关联从student表中获取到name。
另外还可以通过student表中的name,查询这个学生所有考试的成绩:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy import ForeignKey # 外键关联需要这个
from sqlalchemy.dialects.mysql import INTEGER # 要使用无符号的整数
from sqlalchemy.orm import relationship, sessionmaker
engine = create_engine("mysql+pymysql://admin:admin123@192.168.246.12/week12",
encoding='utf-8', echo=False) # 这里把echo关掉
Base = declarative_base() # 生成orm基类
class Student(Base):
__tablename__ = 'student' # 表名,这张表不创建,可以写的简单点
id = Column(INTEGER(unsigned=True), primary_key=True) # 主键必须声明
name = Column(String())
age = Column(Integer)
class Exam(Base):
__tablename__ = 'exam'
name = Column(String(32), primary_key=True)
student_id = Column(INTEGER(unsigned=True), ForeignKey("student.id"), primary_key=True) # 声明外键关联
score = Column(Integer, nullable=False) # 规定不能为空
student = relationship('Student', backref='exam') # 使用这个,必须要先声明ForeighKey。注意参数,前面是类名,后面是表名
# Base.metadata.create_all(engine) # 创建表
session = sessionmaker(bind=engine)()
data = Session.query(Exam).first()
print(data.student.name, data.name, data.score) # 打印考试成绩,把id替换成name
data = Session.query(Student).first() # 打印一个考生所有考试的成绩
for i in data.exam:
print(data.name, i.name, i.score)建立了关联关系后,相当于另一张表的对象就是这张表中的一个属性。属性名是对方的表名。
join的多表查询。建立了关联关系后,现在可以用了:
# 上面的部分就省了,使用join可以没有relationship,但是要声明ForeignKey
session = sessionmaker(bind=engine)()
data = session.query(Exam).join(Student).all()
print(data)
data = session.query(Student).join(Exam).all()
print(data)
data = session.query(Student).join(Exam, isouter=True).all() # 外连接
print(data)默认是内连接,加上参数可以是外连接。因为不需声明了ForeignKey才能使用join,貌似不存在左连接和右连接的问题。有外键约束,其中一张表一定是所有的属性值都被另外一张表包含的。
上面是查询,还可以通过关联对象来创建。比如对student表里的某个同学创建他在exam表里的考试成绩:
# 上面的部分就省了,使用join可以没有relationship,但是要声明ForeignKey
session = sessionmaker(bind=engine)()
data = session.query(Student).filter(Student.name == 'Bob').first() # 通过student表来操作exam表
print(data, data.exam) # 此时data.exam就是Bob在exam表里的记录
data.exam = [Exam(name='test1', score=88),
Exam(name='test2', score=85)] # 通过对象属性赋值的方式写入数据
session.commit() # 最后记得提交最后是查询记录,打印所有订单的信息:
# 插入数据,接在创建表的代码后面。实际使用的时候,分开到不同的文件,用import导入表的class
session = sessionmaker(bind=engine)()
data = session.query(Order).all()
for i in data:
# 要获取关联的数据,仍然是使用通过relationship创建的名字
print(i.id, i.name, i.ship_addr_fk.addr, i.bill_addr_fk.addr)多对一-多外键关联
在这种关系中,A表中的一行只能匹配B表中的一行,但是B表中的一行可能被A表中的多行匹配到,即A表的多行可能匹配的是B表中的同一行。举例说明:
A表是一张货物订单表,4个字段:id(订单号)、收货人、收货地址、收发票的地址。后面2个都是地址,实际情况中可能有需要把货物发往一处,但是发票需要投递到另外一处的情况。比如你帮别人买东西、
B表是地址表,2个字段(简单点):id、地址。A表中的收货地址和收发票地址记录的内容就是B表中的对应地址的id。具体地址需要关联到B表才能查到。
订单表(order):
这里不小心用了order这个mysql的关键字作为了表名。应该避免这种情况,要么换个词,要么用order_。不过用了也不出错。但是你用SQL语句的时候可能操作不了这个表。在SQL语句中如果要使用这个表名,请用 `order` ,是Esc下面数字1左边的那个符号。
| id | name | ship_addr | bill_addr |
|---|---|---|---|
| 1 | Adam | 1 | 2 |
| 2 | Bob | 1 | 3 |
| 3 | Cara | 4 | 4 |
地址表(address):
| id | addr |
|---|---|
| 1 | Beijing |
| 2 | Shanghai |
| 3 | Guangzhou |
| 4 | Shenzhen |
首先创建这两张表:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.dialects.mysql import INTEGER # 要使用无符号的整数
from sqlalchemy import ForeignKey # 外键关联需要这个
from sqlalchemy.orm import relationship, sessionmaker
engine = create_engine("mysql+pymysql://admin:admin123@192.168.3.103/week12",
encoding='utf-8', echo=True)
Base = declarative_base()
class Order(Base):
__tablename__ = 'order'
id = Column(INTEGER(unsigned=True), primary_key=True)
name = Column(String(32))
ship_addr = Column(INTEGER(unsigned=True), ForeignKey('address.id')) # 现在是多对一关联
bill_addr = Column(INTEGER(unsigned=True), ForeignKey('address.id')) # 2个的ForeignKey写的一样,程序分不清楚
# ship_addr_fk = relationship('Address') # 无法写backref,因为Address表不知道是哪个addr关联的它,无法反查的
# bill_addr_fk = relationship('Address') # 当然也不能不写,否则两个是一样的,程序没有逻辑可以区分
ship_addr_fk = relationship('Address', foreign_keys=[ship_addr]) # 这样就能分清楚是哪个外键对应哪个字段了
bill_addr_fk = relationship('Address', foreign_keys=[bill_addr])
class Address(Base):
__tablename__ = 'address'
id = Column(INTEGER(unsigned=True), primary_key=True)
addr = Column(String(32))
Base.metadata.create_all(engine) # 创建表然后来插入数据:
# 插入数据,接在创建表的代码后面。实际使用的时候,分开到不同的文件,用import导入表的class
session = sessionmaker(bind=engine)()
addr1 = Address(addr='Beijing')
addr2 = Address(addr='Shanghai')
addr3 = Address(addr='Guangzhou')
addr4 = Address(addr='Shenzhen')
session.add_all([addr1, addr2, adr3, addr4]) # 可以同时插入多条数据。用列表。
# addr可以使用属性ship_addr=1来指定。也可以像下面这样用relationship创建的属性来调用
order1 = Order(name='Adam', ship_addr_fk=addr1, bill_addr_fk=addr2) # 使用关联创建地址
session.add(order1)
session.commit()上面是同时创建地址和订单记录。也可能是地址已经存在了,那么就是要用查询的方法获取到地址的对象,然后再创建订单记录:
# 插入数据,接在创建表的代码后面。实际使用的时候,分开到不同的文件,用import导入表的class
session = sessionmaker(bind=engine)()
addr_list = session.query(Address).all()
addr_list.insert(0, '') # 在开头随便插一个,让列表第一个元素下标就是1
order2 = Order(name='Bob', ship_addr_fk=addr_list[1], bill_addr_fk=addr_list[3]) # 使用关联创建地址
order3 = Order(name='Cara', ship_addr_fk=addr_list[4], bill_addr_fk=addr_list[4])
session.add_all([order2, order3])
session.commit()多对多-多对多关联
这次先说例子:设计一个能描述“图书”与“作者”的关系的表结构。要求是:一本书可以有好几个作者,一个作者可以写好几本书。
数据库的字段只能放数据,不能放列表,所以不能是这样的形式:
| 书名 | 作者id |
|---|---|
| Hamlet | 1,2 |
那么多个作者字段呢?
| 书名 | 作者1 | 作者2 | 作者3 | 作者4 | 作者5 |
|---|---|---|---|---|---|
| Hamle | 1 | 2 |
万一我有6个作者呢?好吧,以防万一我留50个作者字段名。逻辑通,但是字段设多了浪费,少了不够用。这里的情况主要是字段数量不固定,而且我们甚至不知道字段的上限。书作者的情景下还不明显,如果线路经过路由的跳数,最短1跳,长的可以30跳,甚至不能保证不会出现上百跳的情况。怎么办呢?
在多对多关系中,A表中的一行可以匹配B表中的多行,反之亦然。要创建这种关系,需要定义第三个表,称为结合表,它的主键由A表和B表的外部键组成。
书名表(book):
| id | 书名 |
|---|---|
| 1 | Hamlet |
| 2 | Othello |
| 3 | King Lear |
| 4 | Macbeth |
作者表(author):
| id | name |
|---|---|
| 1 | Adam |
| 2 | Bob |
| 3 | Cara |
| 4 | Dan |
结合表(book2author):
| book_id | author_id |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 2 | 3 |
| 3 | 2 |
| 3 | 3 |
| 3 | 4 |
| 4 | 4 |
| 4 | 2 |
数据结构清楚了,首先来创建表:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Table # 新导入一个Table
from sqlalchemy.dialects.mysql import INTEGER # 要使用无符号的整数
from sqlalchemy import ForeignKey # 外键关联需要这个
from sqlalchemy.orm import relationship, sessionmaker
engine = create_engine("mysql+pymysql://admin:admin123@192.168.3.103/week12",
encoding='utf-8', echo=True)
Base = declarative_base()
# 第三张表用另外一种方法来创建
# 没有用类,也不需要用到类。使用的时候根不需要手动来操作这张表
# 使用的时候根本不用知道这张表的存在,我们只需要维护好另外2张表就好了
book2author = Table('book2author', Base.metadata,
Column('book_id', INTEGER(unsigned=True), ForeignKey('book.id')),
Column('author_id', INTEGER(unsigned=True), ForeignKey('author.id'))
) # 外键实际是关联在这里的
# 上的这张表你以后再也不用管它了,甚至不用知道它的存在
class Book(Base):
__tablename__ = 'book'
id = Column(INTEGER(unsigned=True), primary_key=True)
name = Column(String(32))
author = relationship('Author', secondary=book2author, backref='book') # 关联author表,但是实际是通过secondary来查
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = 'author'
id = Column(INTEGER(unsigned=True), primary_key=True)
name = Column(String(32))
# book = relationship('Book', secondary=book2author, backref='author') # 上面的类里加了这里就不用了,选一个类里写
def __repr__(self):
return self.name
Base.metadata.create_all(engine) # 创建表插入上面的记录:
# 插入数据,接在创建表的代码后面。实际使用的时候,分开到不同的文件,用import导入表的class
session = sessionmaker(bind=engine)()
book1 = Book(name='Hamlet')
book2 = Book(name='Othello')
book3 = Book(name='King Lear')
book4 = Book(name='Macbeth')
author1 = Author(name='Adam')
author2 = Author(name='Bob')
author3 = Author(name='Cara')
author4 = Author(name='Dan')
# 下面是创建第三张表,通过book来创建的。完全不用操作第三张表
# 我们现在不知道有第三张表,只知道author是关联到book的
book1.author = [author1]
book2.author = [author2, author3]
book3.author = [author2, author3, author4]
book4.author = [author4, author2]
session.add_all([book1, book2, book3, book4, author1, author2, author3, author4])
session.commit()查询记录:
# 插入数据,接在创建表的代码后面。实际使用的时候,分开到不同的文件,用import导入表的class
session = sessionmaker(bind=engine)()
author_obj = session.query(Author).filter(Author.name == 'Bob').first() # 通过作者查书名
print(author_obj, author_obj.book)
book_obj = session.query(Book).filter(Book.name == 'Othello').first() # 通过书名查作者
print(book_obj, book_obj.author)接下来来删除数据:
通过查找先获取到对象,然后移除对象。第三张表永远不用管,自动都会通过关联处理好。
# 插入数据,接在创建表的代码后面。实际使用的时候,分开到不同的文件,用import导入表的class
session = sessionmaker(bind=engine)()
author_obj = session.query(Author).filter(Author.name == 'Bob').first() # 通过作者查书名
print(author_obj, author_obj.book)
book_obj = session.query(Book).filter(Book.name == 'Othello').first() # 通过书名查作者
print(book_obj, book_obj.author) # 这里的参数都是对象,类中写了__repr__方法
book_obj.author.remove(author_obj) # 从这本书中移除Bob这个作者的对象,其实就是删除了第三张表中的一条记录
session.commit() # 提交一下,在看看Bob写了哪些书,Othello的作者现在有谁了
author_obj = session.query(Author).filter(Author.name == 'Bob').first() # 通过作者查书名
print(author_obj, author_obj.book)
book_obj = session.query(Book).filter(Book.name == 'Othello').first() # 通过书名查作者
print(book_obj, book_obj.author)删除作者,把Bob彻底干掉:
# 插入数据,接在创建表的代码后面。实际使用的时候,分开到不同的文件,用import导入表的class
session = sessionmaker(bind=engine)()
author_obj = session.query(Author).filter(Author.name == 'Bob').first() # 先用查找来获取到对象
session.delete(author_obj) # 删除这个对象
session.commit()使用中文
要使用中文需要再engine里加一个参数,修改一下第一个参数的url,最后加一段:
engine = create_engine("mysql+pymysql://admin:admin123@192.168.3.103/week12?charset=utf8",
encoding='utf-8', echo=True) # 支持中文这样你的sqlalchemy就可以使用中文了。
确认你建库的时候使用了utf8,默认是'latin1'。这样你的数据库也支持中文了。
系统可能不支持,这样你还是打印不出来。系统可能没有安装中文字符集,可能还要设置环境。还是算了不要搞系统了。
不过你还可以用ssh登录,这样只要你本地的ssh能打印中文就可以了,我们不需要在系统上输出。
作业
学员管理系统:
用户角色,讲师\学员, 用户登陆后根据角色不同,能做的事情不同,分别如下
上一篇: Python魔法方法指南
下一篇: python re库-----学习(正则
- H3C基本命令大全
53518
- H3C IRF原理及 配置
40346
- Python exit()函数
34747
- python全系列官方中文文档
30503
- python 获取网卡实时流量
25378
- 1.常用turtle功能函数
25177
- python 获取Linux和Windows硬件信息
23589
- 天天基金网数据接口
18858
- Selenium使用代理IP&无头模式访问网站
15170
- Selenium&Pytesseract模拟登录+验证码识别
14676
- LangGraph Studio可视化
1144°
- LangSmith开发-应用入门
1067°
- LangGraph开发-多轮对话问答机器人
1136°
- LangGraph开发-条件分支/循环图实战
1152°
- LangGraph开发-生态介绍,入门demo实战
1188°
- LangChain-接入12306-HTTP MCP智能体
1344°
- LangChain接入自定义爬虫-MCP工具
1303°
- LangChain接入Filesystem-MCP工具
1277°
- LangChain搭建MCP服务端和客户端流程
1376°
- LangGraph与MCP技术概述
1319°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
