本次项目主要围绕Kaggle上的比赛题目: "给出泰坦尼克号上的乘客的信息, 预测乘客是否幸存" 进行数据分析
环境
win8, python3.7, jupyter notebook
目录
1. 项目背景
2. 数据概览
3. 特征分析
4. 特征工程
5. 构建模型
正文
1. 项目背景
泰坦尼克号: 是当时世界上体积最庞大、内部设施最豪华的客运轮船, 于1909年3月31日动工建造, 1912年4月2日完工试航. 于1912年4月10日, 在南安普敦港的海洋码头, 启程驶往纽约, 开始了它的第一次, 也是最后一次的航行. 泰坦尼克号将乘客分为三个等级: 三等舱位于船身较下层也最便宜; 二等舱具备与当时其他一般船只的头等舱同样的等级, 许多二等舱的乘客原先在其他船只上预定的头等舱, 却因为泰坦尼克号的航行, 将煤炭能源转移给泰坦尼克号; 一等舱是整艘船最为昂贵奢华的部分.
船上时间为1912年4月14日23时40分左右, 泰坦尼克号与一座冰山相撞, 造成水密舱进水, 次日凌晨2时20分左右沉没. 2224名船员和乘客中1502人遇难, 造成如此巨大的伤亡原因之一是船上没有足够的救生艇供乘客和船员使用. 在这次灾难中能否幸存下来难免会有些运气成分, 但是有些人比其他人更可能生存下来, 比如妇女, 儿童和上层阶级.
2. 数据概览
本项目提供了两份数据: train.csv文件作为训练集构建与生存相关的模型; 另一份test.csv文件则用作测试集, 用我们构建出来的模型预测生存情况.
2.1 读取数据:
import pandas as pd df_train, df_test= pd.read_csv('train.csv'), pd.read_csv('test.csv')
从训练集开始介绍:
2.2 查看前五行数据
#查看前5行数据 df_train.head()

#查看后5行数据 df_titanic.tail()

通过以上数据以及题目资料, 可以了解到训练集总共有891行, 以下字段:
.PassengerId -- Id, 具有唯一标识的作用, 即一个人员对应一个Id.
Survived -- 是否幸存, 1表示是 0则表示否
Pclass -- 船舱等级, 1: 一等舱, 2: 二等舱, 3: 三等舱
Name -- 姓名, 通常西方人的姓名结构为教名+自取名+姓, 但在很多场合中间的"自取名"会省略不写, 而且很多人更喜欢用教名的昵称取代正式教名. 有时也会将姓氏写在逗号前. 比如Dooley, Mr. Patrick, 即Dooley表示姓氏, Patrick表示名, 那Mr.呢? Mr.表示头衔, 有身份地位的象征.
Sex -- 性别, female女性, male男性
Age -- 年龄
SibSp -- 同船配偶以及兄弟姐妹的人数
Parch -- 同船父母或者子女的人数
Ticket -- 船票
Fare -- 票价
Cabin -- 舱位
Embarked -- 登船港口
2.3 查看数据表整体信息
#查看数据信息, 其中包含数据维度, 数据类型, 所占空间等信息 df_train.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB
数据维度: 891行X12列
缺失字段: Age, Cabin, Embarked
数据类型: 2个64位浮点型, 5个64位整型, 5个python对象.
2.4 描述性统计
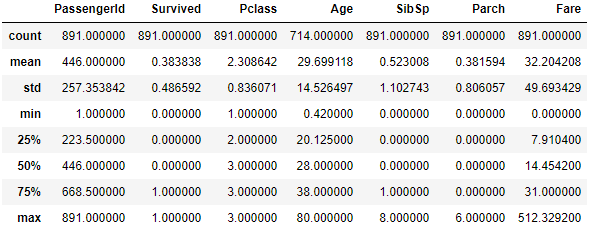
df_train.describe()
除了python对象以外的数据类型, 均参与了计算:
38.4%的人幸存, 死亡率很高;
年龄现有数据714, 缺失占比714/891=20%;
同船兄弟姐妹与配偶人数最大为8, 同船父母或者子女的人数最大则为6, 且两者最小值均为0, 看来有大家庭, 小家庭(独自一人)之分;
票价最小为0, 最大为512.3, 均值为32.20, 中位数为14.45, 正偏, 贫富差距不小.
那么与python对象对应的该怎么查看呢?
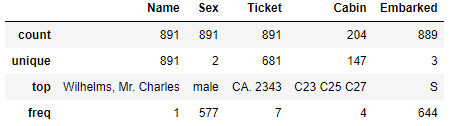
#同样是使用describe()方法 df_train[['Name','Sex','Ticket','Cabin','Embarked']].describe()
显示结果与上述有点区别, 依次来看:
姓名共有891种, 总数也891个, 姓名是唯一的;
性别中男性最多, 达到577人次;
船票中681种, 总数891, 部分人共用一张票;
舱位总数204, 缺失占比(891-204)/891= 77%;
登船港口总数889, 缺失2个, 共有3种类型, 其中S最多, 达到644人次,
现在已经对每个特征的大致信息有所了解, 那么下一步则是在特征分析中探索着找出与幸存相关的特征.
3. 特征分析
在11个特征中, 哪些是和幸存相关的呢?
1. PassengerId
Id仅仅是用来标识乘客的唯一性, 必然是与幸存无关.
2. Pclass
船舱等级, 一等舱是整个船最昂贵奢华的地方, 有钱人才能享受, 想必一等舱的有钱人比三等舱的穷人更容易幸存, 到底是不是呢? 用数据说话:
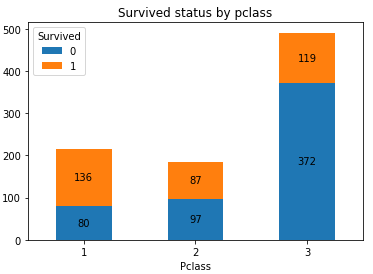
import numpy as np import matplotlib.pyplot as plt #生成Pclass_Survived的列联表 Pclass_Survived = pd.crosstab(df_train['Pclass'], df_train['Survived']) #绘制堆积柱形图 Pclass_Survived.plot(kind = 'bar', stacked = True) Survived_len = len(Pclass_Survived.count()) Pclass_index = np.arange(len(Pclass_Survived.index)) Sum1 = 0 for i in range(Survived_len): SurvivedName = Pclass_Survived.columns[i] PclassCount = Pclass_Survived[SurvivedName] Sum1, Sum2= Sum1 + PclassCount, Sum1 Zsum = Sum2 + (Sum1 - Sum2)/2 for x, y, z in zip(Pclass_index, PclassCount, Zsum): #添加数据标签 plt.text(x,z, '%.0f'%y, ha = 'center',va='center' ) #修改x轴标签 plt.xticks(Pclass_Survived.index-1, Pclass_Survived.index, rotation=360) plt.title('Survived status by pclass')
可以看到一等舱人员的幸存机会远大于三等舱, 果然和船舱等级相关.
其中的列联表就等同于以下操作:
#生成Survived为0时, 每个Pclass的总计数 Pclass_Survived_0 = df_train.Pclass[df_train['Survived'] == 0].value_counts() #生成Survived为1时, 每个Pclass的总计数 Pclass_Survived_1 = df_train.Pclass[df_train['Survived'] == 1].value_counts() #将两个状况合并为一个DateFrame Pclass_Survived = pd.DataFrame({ 0: Pclass_Survived_0, 1: Pclass_Survived_1})
3. Name
姓名, 总数891个且有891种不同的结果, 直接拿来讨论, 没多大意义. 但是值得注意的是姓名中有头衔存在, 头衔又是身份地位的象征, 想必身份地位越高, 应当更容易幸存. 先提取出Name中的头衔特征:
#提取出头衔 df_train['Appellation'] = df_train.Name.apply(lambda x: re.search('\w+\.', x).group()).str.replace('.', '') #查看有多种不同的结果 df_train.Appellation.unique()
array(['Mr', 'Mrs', 'Miss', 'Master', 'Don', 'Rev', 'Dr', 'Mme', 'Ms',
'Major', 'Lady', 'Sir', 'Mlle', 'Col', 'Capt', 'Countess',
'Jonkheer'], dtype=object)
头衔名称的解读: Mr 既可用于已婚男性, 也可用于未婚男性, Mrs 已婚女性, Miss 通常用来称呼未婚女性, 但有时也用于称呼自己不了解的年龄较大的妇女, Master 男童或男婴, Don 大学教师, Rev 牧师, Dr 医生或者博士, Mme 女士, Ms 既可用于已婚女性也可用于未婚女性, Major 陆军少校, Lady 公候伯爵的女儿, Sir 常用来称呼上级长官, Mlle 小姐, Col 上校(常用于陆空军), Capt 船长, Countess 指伯爵夫人, Jonkheer 乡绅.
头衔太多了, 决定将其归类, 那么如何归类呢? 先查看下其与性别对应的人数:
Appellation_Sex = pd.crosstab(df_train.Appellation, df_train.Sex) Appellation_Sex.T

决定将将少数部分归为'Rare', 将'Mlle', 'Ms'用'Miss'代替, 将'Mme'用'Mrs'代替.
df_train['Appellation'] = df_train['Appellation'].replace(['Capt','Col','Countess','Don','Dr','Jonkheer','Lady','Major','Rev','Sir'], 'Rare')
df_train['Appellation'] = df_train['Appellation'].replace(['Mlle','Ms'], 'Miss')
df_train['Appellation'] = df_train['Appellation'].replace('Mme', 'Mrs')
df_train.Appellation.unique()
array(['Mr', 'Mrs', 'Miss', 'Master', 'Rare'], dtype=object)
头衔和幸存相关吗?
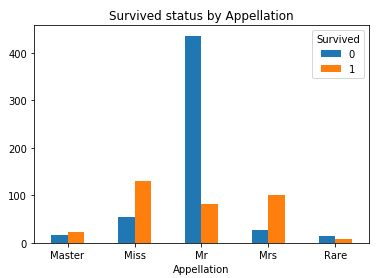
#绘制柱形图 Appellation_Survived = pd.crosstab(df_train['Appellation'], df_train['Survived']) Appellation_Survived.plot(kind = 'bar')
plt.xticks(np.arange(len(Appellation_Survived.index)), Appellation_Survived.index, rotation = 360) plt.title('Survived status by Appellation')
头衔中Master, Miss, Mrs的幸存机会均大于Mr 和 Rare.
4. Sex
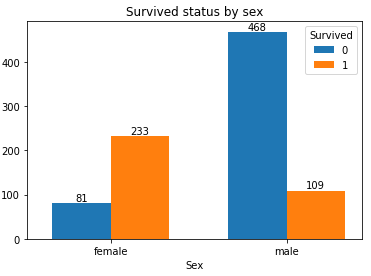
性别, 女士优先, 但在这种紧急关头, 会让女士优先上救生艇吗?上数据:
#生成列联表 Sex_Survived = pd.crosstab(df_train['Sex'], df_train['Survived']) Survived_len = len(Sex_Survived.count()) Sex_index = np.arange(len(Sex_Survived.index)) single_width = 0.35 for i in range(Survived_len): SurvivedName = Sex_Survived.columns[i] SexCount = Sex_Survived[SurvivedName] SexLocation = Sex_index * 1.05 + (i - 1/2)*single_width #绘制柱形图 plt.bar(SexLocation, SexCount, width = single_width) for x, y in zip(SexLocation, SexCount): #添加数据标签 plt.text(x, y, '%.0f'%y, ha='center', va='bottom') index = Sex_index * 1.05 plt.xticks(index, Sex_Survived.index, rotation=360) plt.title('Survived status by sex')
结果可以看出, 女性中的幸存率远高于男性(也就是说女性优先上救生艇)
5. Age
由于Age特征存在缺失值, 处理完缺失值, 再对其进行分析.
6. SibSp
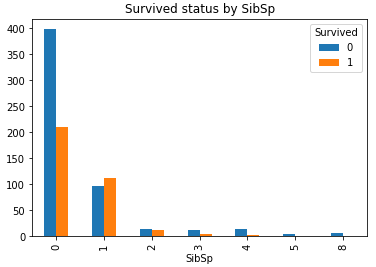
从之前的描述性统计了解到, 兄弟姐妹与配偶的人数最多为8, 最少为0, 哪个更容易生存呢?
#生成列联表 SibSp_Survived = pd.crosstab(df_train['SibSp'], df_train['Survived']) SibSp_Survived.plot(kind = 'bar') plt.title('Survived status by SibSp')
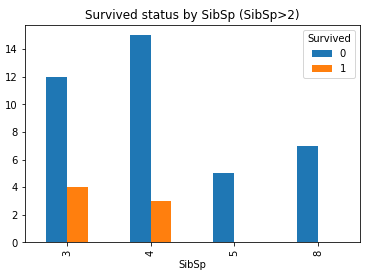
可以看到, 大部分的SibSp为0, 且幸存率不大, 当SibSp数量为1,2时幸存率又有所增加, 再往上又降低.
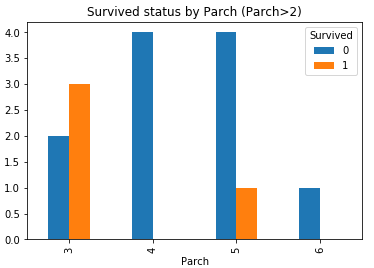
7. Parch
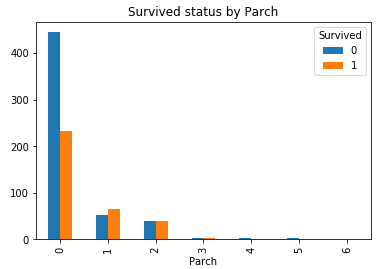
通过上面的描述性统计了解到, 同样也可以分为大家庭(最多为6), 小家庭(最小为0), 他们的幸存率如何呢?
Parch_Survived = pd.crosstab(df_train['Parch'], df_train['Survived']) Parch_Survived.plot(kind = 'bar') plt.title('Survived status by Parch')
同样可以看到, 大部分Parch为0, 幸存率不大, 当为1,2,3时, 有所增加, 再往上又有所减小.
8. Ticket
总人数891, 船票有681种, 说明部分人共用一张票, 什么人能共用一张票呢? 想必应该认识, 就需要对他们进行归类, 共用票的分为一类, 独自使用的分为一类:
#计算每张船票使用的人数 Ticket_Count = df_train.groupby('Ticket', as_index = False)['PassengerId'].count() #获取使用人数为1的船票 Ticket_Count_0 = Ticket_Count[Ticket_Count.PassengerId == 1]['Ticket'] #当船票在已经筛选出使用人数为1的船票中时, 将0赋值给GroupTicket, 否则将1赋值给GroupTicket df_train['GroupTicket'] = np.where(df_train.Ticket.isin(Ticket_Count_0), 0, 1) #绘制柱形图 GroupTicket_Survived = pd.crosstab(df_train['GroupTicket'], df_train['Survived']) GroupTicket_Survived.plot(kind = 'bar') plt.title('Survived status by GroupTicket')
很明显, 船上有同伴比孤身一人幸存的机会大.

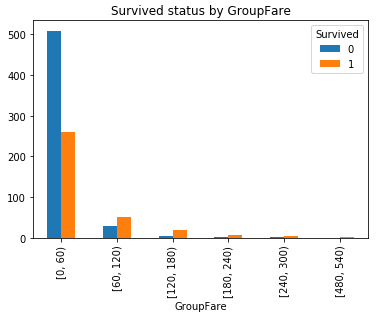
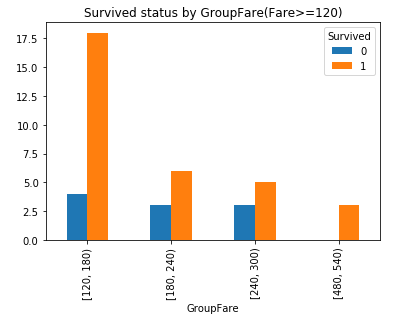
9. Fare
票价, 最小为0, 最大为512.3292, 生存率到底和票价有没有关系呢?对Fare进行分组对比:
#对Fare进行分组: 2**10>891分成10组, 组距为(最大值512.3292-最小值0)/10取值60 bins = [0, 60, 120, 180, 240, 300, 360, 420, 480, 540, 600] df_train['GroupFare'] = pd.cut(df_train.Fare, bins, right = False) GroupFare_Survived = pd.crosstab(df_train['GroupFare'], df_train['Survived']) #GroupFare_Survived.plot(kind = 'bar') #plt.title('Survived status by GroupFare') GroupFare_Survived.iloc[2:].plot(kind = 'bar') plt.title('Survived status by GroupFare(Fare>=120)')
可以看到随着票价的增长, 幸存机会也会变大.
10. Cabin
由于含有大量缺失值, 处理完缺失值再对其进行分析.
11.Embarked
同样也含有缺失值, 处理完缺失值在对其进行分析.
以上便是对特征中无缺失部分进行分析, 下一步则会在特征工程中对缺失部分进行处理
4. 特征工程
4.1 缺失值处理
缺失值主要是由人为原因和机械原因造成的数据缺失, 在pandas中用NaN或者NaT表示, 它的处理方式有多种:
1. 用某些集中趋势度量(平均数, 众数)进行对缺失值进行填充.
2. 用统计模型来预测缺失值, 比如回归模型, 决策树, 随机森林
3. 删除缺失值
4. 保留缺失值
究竟采用处理方式呢, 应当结合具体的场景进行选择.
在缺失值处理之前, 应当将数据拷贝一份, 以保证原始数据的完整性
train = df_train.copy()
4.1.1 Embarked缺失值处理
通过以上, 我们已经知道Embarked字段中缺失2个, 且数据中S最多, 达到644个, 占比644/891=72%, 那么我们就采用众数进行填充.
train['Embarked'] = train['Embarked'].fillna(train['Embarked'].mode()[0])
4.1.2 Cabin缺失值处理
Cabin缺失687个, 占比687/891=77%, 缺失数据太多, 是否删除呢? 舱位缺失可能代表这些人没有舱位, 不妨用'NO'来填充.
train['Cabin'] = train['Cabin'].fillna('NO')
4.1.3 Age缺失值处理
Age缺失177个, 占比177/891=20%, 缺失数据也不少, 而且Age在本次分析中也尤其重要(孩子和老人属于弱势群体, 应当更容易获救), 不能删除也不能保留, 那么到底采用哪种方式呢? 由于是第一次项目, 就采用简单点的, 采用与头衔相对应的年龄中位数进行填补.
#求出每个头衔对应的年龄中位数 Age_Appellation_median = train.groupby('Appellation')['Age'].median() #在当前表设置Appellation为索引 train.set_index('Appellation', inplace = True) #在当前表填充缺失值 train.Age.fillna(Age_Appellation_median, inplace = True) #重置索引 train.reset_index(inplace = True)
此时, 就完成了对Age字段中缺失值的填充.
检查一下, 检查是否存在缺失值, 有多种方法, 这里采用第三种: 顺带看下均值, 中位数
#第一种: 返回0即表示没有缺失值 train.Age.isnull().sum() #第二种: 返回False即表示没有缺失值 train.Age.isnull().any() #第三种: 描述性统计 train.Age.describe()
count 891.000000 mean 29.392447 std 13.268389 min 0.420000 25% 21.000000 50% 30.000000 75% 35.000000 max 80.000000 Name: Age, dtype: float64
完成了缺失值的处理, 接下来对缺失特征进行分析
4.2 缺失特征分析
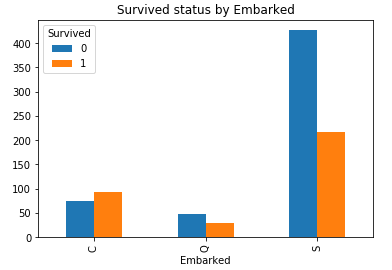
4.2.1 Embarked
#绘制柱形图 Embarked_Survived = pd.crosstab(train['Embarked'], train['Survived']) Embarked_Survived.plot(kind = 'bar') plt.title('Survived status by Embarked')
C港生存机会明显高于Q港, S港, C港的有钱人多吗?这里不再深究, 现能确定的是它与生存相关.
4.2.2 Cabin
#将没有舱位的归为0, 有舱位归为1. train['GroupCabin'] = np.where(train.Cabin == 'NO', 0, 1) #绘制柱形图 GroupCabin_Survived = pd.crosstab(train['GroupCabin'], train['Survived']) GroupCabin_Survived.plot(kind = 'bar') plt.title('Survived status by GroupCabin')
有舱位的比没有舱位的幸存机会大.

4.2.3 Age
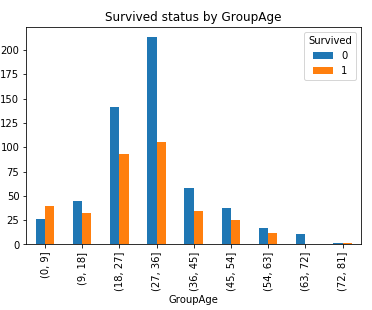
#对Age进行分组: 2**10>891分成10组, 组距为(最大值80-最小值0)/10 =8取9 bins = [0, 9, 18, 27, 36, 45, 54, 63, 72, 81, 90] train['GroupAge'] = pd.cut(train.Age, bins) GroupAge_Survived = pd.crosstab(train['GroupAge'], train['Survived']) GroupAge_Survived.plot(kind = 'bar') plt.title('Survived status by GroupAge')
正如料想的那样: 小孩幸存机会更大.
到现在我们已经完成所有特征的分析, 接下来看一下能否在这些特征的基础上提取一些新的特征.
4.3 新特征的提取
通过以上的分析, 我们已经了解到生存率相关的特征:
Pclass, Appellation(Name中提取), Sex, GroupAge(对Age分组), SibSp, Parch, GroupTicket(对Ticket分组), GroupFare(对Fare分组), GroupCabin(对Cabin分组), Embarked.
1. Pclass中没有更多信息可供提取, 且为定量变量, 这里不作处理.
2. Appellation是定性变量, 将其转化为定量变量:
train['Appellation'] = train.Appellation.map({'Mr': 0, 'Mrs': 1, 'Miss': 2, 'Master': 3, 'Rare': 4}) train.Appellation.unique()
3. Sex是定性变量, 将其转化为定量变量, 即用0表示female, 1表示male
train['Sex'] = train['Sex'].map({'female': 0, 'male': 1})
4. 按照GroupAge特征的范围将Age分为10组.
train.loc[train['Age'] < 9, 'Age'] = 0 train.loc[(train['Age'] >= 9) & (train['Age'] < 18), 'Age'] = 1 train.loc[(train['Age'] >= 18) & (train['Age'] < 27), 'Age'] = 2 train.loc[(train['Age'] >= 27) & (train['Age'] < 36), 'Age'] = 3 train.loc[(train['Age'] >= 36) & (train['Age'] < 45), 'Age'] = 4 train.loc[(train['Age'] >= 45) & (train['Age'] < 54), 'Age'] = 5 train.loc[(train['Age'] >= 54) & (train['Age'] < 63), 'Age'] = 6 train.loc[(train['Age'] >= 63) & (train['Age'] < 72), 'Age'] = 7 train.loc[(train['Age'] >= 72) & (train['Age'] < 81), 'Age'] = 8 train.loc[(train['Age'] >= 81) & (train['Age'] < 90), 'Age'] = 9 train.Age.unique()
array([2., 4., 3., 6., 0., 1., 7., 5., 8.])
5. 将SibSp和Parch这两个特征组合成FamilySize特征
#当SibSp和Parch都为0时, 则孤身一人. train['FamilySize'] = train['SibSp'] + train['Parch'] + 1 train.FamilySize.unique()
array([ 2, 1, 5, 3, 7, 6, 4, 8, 11], dtype=int64)
6. GroupTicket是定量变量, 不作处理
7. 按照GroupFare特征的范围将Fare分成10组:
train.loc[train['Fare'] < 60, 'Fare'] = 0 train.loc[(train['Fare'] >= 60) & (train['Fare'] < 120), 'Fare'] = 1 train.loc[(train['Fare'] >= 120) & (train['Fare'] < 180), 'Fare'] = 2 train.loc[(train['Fare'] >= 180) & (train['Fare'] < 240), 'Fare'] = 3 train.loc[(train['Fare'] >= 240) & (train['Fare'] < 300), 'Fare'] = 4 train.loc[(train['Fare'] >= 300) & (train['Fare'] < 360), 'Fare'] = 5 train.loc[(train['Fare'] >= 360) & (train['Fare'] < 420), 'Fare'] = 6 train.loc[(train['Fare'] >= 420) & (train['Fare'] < 480), 'Fare'] = 7 train.loc[(train['Fare'] >= 480) & (train['Fare'] < 540), 'Fare'] = 8 train.loc[(train['Fare'] >= 540) & (train['Fare'] < 600), 'Fare'] = 9
train.Fare.unique()
array([0., 1., 4., 2., 8., 3.])
8. GroupCabin是定量变量, 不作处理
9. Embarked是定类变量, 转化为定量变量.
train['Embarked'] = train.Embarked.map({'S': 0, 'C': 1, 'Q': 2})
现有特征:
PassengerId, Survived, Pclass, Name, Appellation, Sex, Age, GroupAge, SibSp, Parch, FamilySize, Ticket, GroupTicket, Fare, GroupFare, Cabin, GroupCabin, Embarked.
删除重复多余的以及与Survived不相关的:
train.drop(['PassengerId', 'Name', 'GroupAge', 'SibSp', 'Parch', 'Ticket', 'GroupFare', 'Cabin'], axis = 1, inplace =True)
删除后, 现有特征:
Survived, Pclass, Appellation, Sex, Age, FamilySize, GroupTicket, Fare, GroupCabin, Embarked.
到这里, 数据就处理完了, 下一步就是建立模型
5. 构建模型
用sklearn库实现机器学习算法 考虑用到的算法有: 逻辑回归, 决策树
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split X=train[['Pclass', 'Appellation', 'Sex', 'Age', 'FamilySize', 'GroupTicket', 'Fare', 'GroupCabin', 'Embarked']] y=train['Survived'] #随机划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) #逻辑回归模型初始化 lg = LogisticRegression() #训练逻辑回归模型 lg.fit(X_train, y_train) #用测试数据检验模型好坏 lg.score(X_test, y_test)
0.8044692737430168
作为第一次项目实战, 0.8的结果还算不错, 再试试决策树
from sklearn.tree import DecisionTreeClassifier
#树的最大深度为15, 内部节点再划分所需最小样本数为2, 叶节点最小样本数1, 最大叶子节点数10, 每次分类的最大特征数6 dt = DecisionTreeClassifier(max_depth=15, min_samples_split=2, min_samples_leaf=1, max_leaf_nodes=10, max_features=6) dt.fit(X_train, y_train) dt.score(X_test, y_test)
0.8268156424581006
决策树的参数是我自己随意取的, 但对比逻辑回归模型有明显提升.
