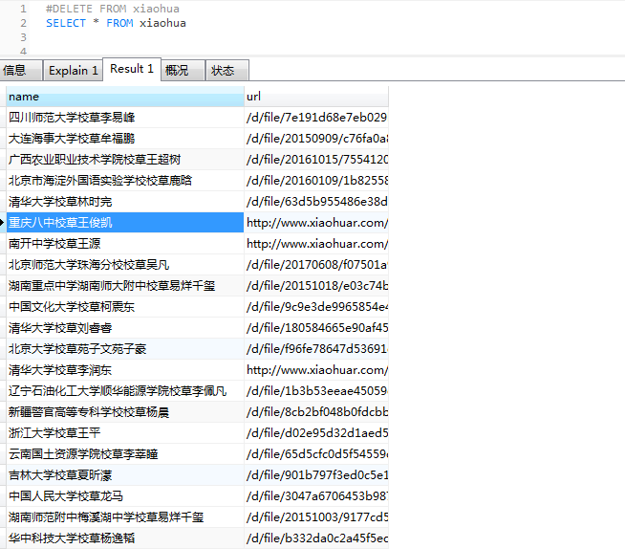
为了把数据保存到mysql费了很多周折,早上再来折腾,终于折腾好了
安装数据库
1、pip install pymysql(根据版本来装)
2、创建数据
打开终端 键入mysql -u root -p 回车输入密码
create database scrapy (我新建的数据库名称为scrapy)
3、创建表
use scrapy;
create table xiaohua (name varchar(200) ,url varchar(100));
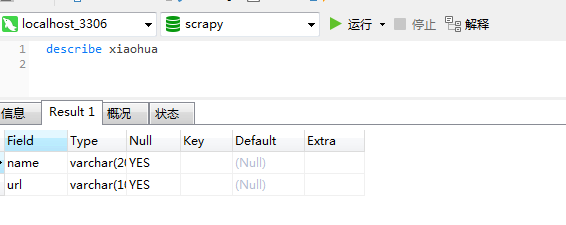
数据库部分就酱紫啦
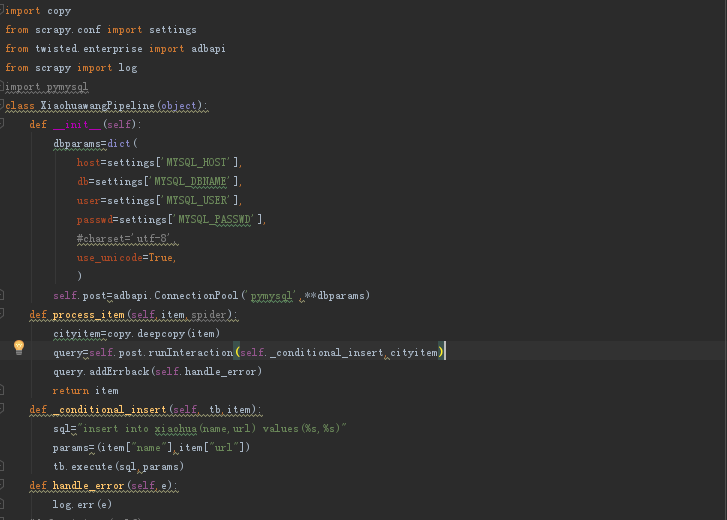
4、编写pipeline
5、编写setting

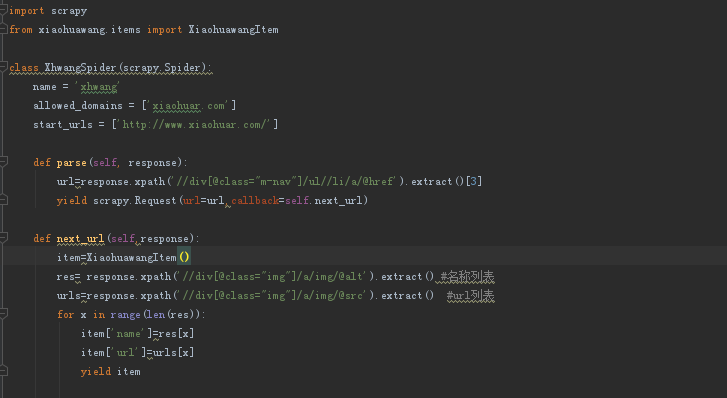
6、编写spider文件
7、爬取数据保存到mysql
scrapy crawl xhwang
之前报错为2018-10-18 09:05:50 [scrapy.log] ERROR: (1241, 'Operand should contain 1 column(s)')
因为我的spider代码中是这样
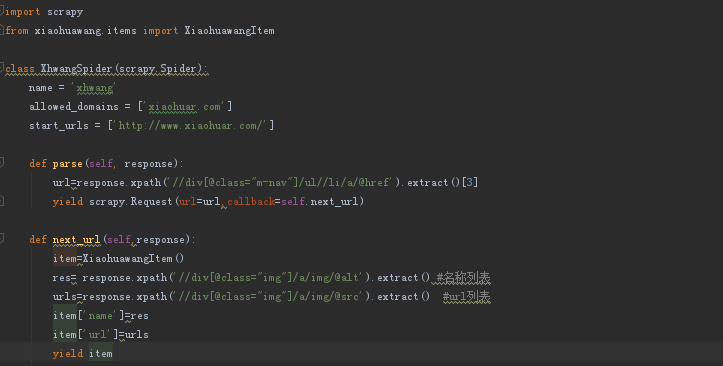
附一张网上找到的答案

错误原因:item中的结果为{'name':[xxx,xxxx,xxxx,xxx,xxxxxxx,xxxxx],'url':[yyy,yyy,yy,y,yy,y,y,y,y,]},这种类型的数据
更正为6下面代码后出现如下会有重复
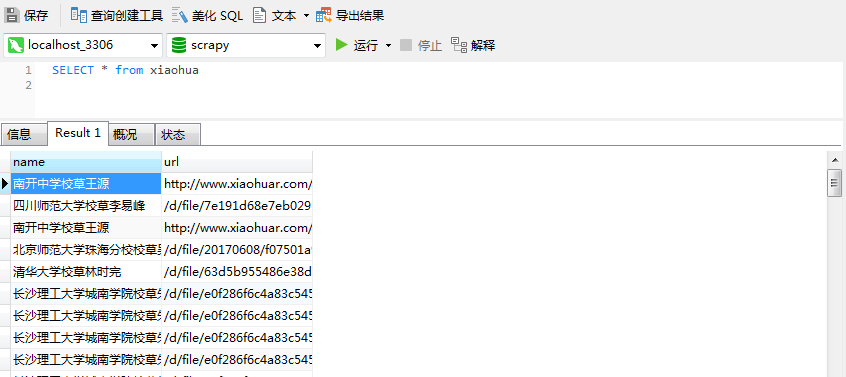
然后又查了下原因终于解决问题之所在
在图上可以看出,爬取的数据结果是没有错的,但是在保存数据的时候出错了,出现重复数据。那为什么会造成这种结果呢?
其原因是由于spider的速率比较快,scrapy操作数据库相对较慢,导致pipeline中的方法调用较慢,当一个变量正在处理的时候
一个新的变量过来,之前的变量值就会被覆盖了,解决方法是对变量进行保存,在保存的变量进行操作,通过互斥确保变量不被修改。
在pipeline中修改如下代码

完成以上设定再来爬取,OK 大功告成(截取部分)