一、环境搭建
工欲善其事,必先利其器。在这里,我们采用selenium+webDriver+headless Chrome(当然,这里使用FireFox、Safari浏览器都可以)来实现爬虫。
(一)工具
1.selenium,一个用于Web应用程序测试的工具。其特点是直接运行在浏览器中,就像真正的用户在操作一样。新版本selenium2集成了 Selenium 1.0 以及 WebDriver。
2.webDriver作用如下:执行代码通过给Webdriver发送指令,让Webdriver知道想要做的操作,Webdriver再根据这些操作在浏览器界面上进行控制,例如查找页面元素、发送文本、实现事件点击等等。
3.Headless Chrome 是 Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有 Chrome 支持的特性运行程序。从而更加方便测试 web 应用,获得网站的截图,做爬虫抓取信息等。
(二)安装
1.安装selenium
首先,在安装好python.exe或者anaconda集成环境的前提下,打开命令对话框cmd,
(1)输入pip install selenuim进行安装。
如果总是报以下错误:Could not find a version that satisfies the requirement selenuim (from versions: ),No matching distribution found for selenuim选择方法2
(2)自己下载selenium工具,下载地址:https://pypi.python.org/pypi/selenium。下载完成后,把安装包拷贝到 pip3 同目录下,使用管理员权限执行 cmd,
切换到 pip3 目录(%python%\Scripts),执行命令行:pip3 install selenium-3.4.3-py2.py3-none-any.whl
如果使用pip3提示需要升级,则在对话框中进入到python.exe所在位置,输入 python -m pip install --upgrade pip
安装成功显示如下:
2.安装webDriver
注意保持两个版本对应:1.浏览器类型与webDriver对应,ChromeBrowser-ChromeDriver;2.浏览器版本与webDriver版本对应。
在url输入框键入:chrome://version可查看浏览器版本(chrome68要求driver2.42),相应版本的webDriver下载地址如下:https://chromedriver.storage.googleapis.com/index.html
下载完webDriver之后解压放到chrome.exe的安装目录下,并添加系统变量,即可使用。

3.Headless Chrome
设置浏览器的无界面状态可提高爬虫速度,在代码文件中进行设置即可。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
二、编写代码
from selenium import webdriver
import csv
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
url = 'http://music.163.com/#/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=0'
#准备好存储歌单的csv文件
csv_file = open("playlist.csv",'w',newline='')
writer = csv.writer(csv_file)
writer.writerow(['标题','播放数','链接'])
#解析每一页,直到‘下一页’为空
while url != 'javascript:void(0)':
#用webDriver加载页面
driver.get(url)
#切换到内容的iframe
driver.switch_to.frame("contentFrame")
#定位歌单标签
data = driver.find_element_by_id("m-pl-container").\
find_elements_by_tag_name("li")
#解析一页中的所有歌单
for i in range(len(data)):
#获取播放数
nb = data[i].find_element_by_class_name("nb").text
if '万' in nb and int(nb.split("万")[0]) > 500 :
msk = data[i].find_element_by_css_selector("a.msk")
writer.writerow([msk.get_attribute('title'),nb,msk.get_attribute('href')])
url = driver.find_element_by_css_selector("a.zbtn.znxt").\
get_attribute("href")
csv_file.close()
三、运行结果
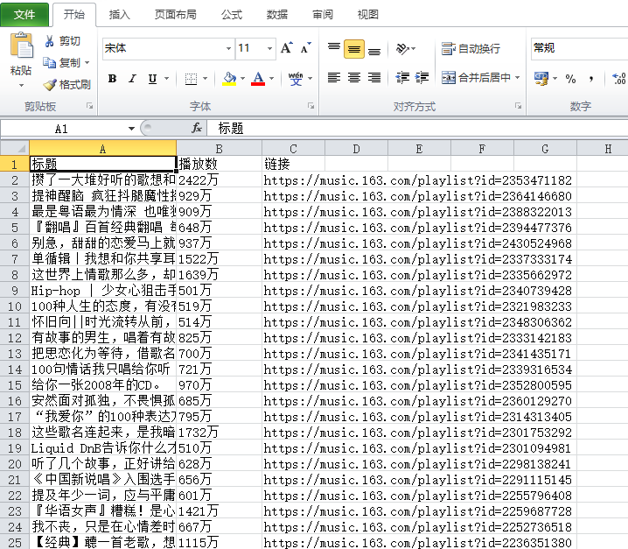
四、补充
在安装工具或者运行项目时经常遇到python版本不匹配的问题,这时我们可以进行版本切换,参考
关于在anaconda中切换不同的python版本
https://blog.csdn.net/my_kingdom/article/details/68957736
本文章参考了【爬虫】手把手教你写网络爬虫(1)
