在这篇博客中,用一个小栗子来介绍一下散点图在多变量数据中的一方面应用。
scikit库中提供了一些数据,这里使用iris数据集,是一种鸢尾属植物,所给数据中包括两种类型的花,目的是根据所给信息判断两种花分别属于哪一类。也就是说找到区分这两种花的方法。
加载库
1 from sklearn.datasets import load_iris
2 import numpy as np
3 import matplotlib.pyplot as plt
4 import itertools
导入数据
1 data = load_iris()
2 x = data['data']
3 y = data['target']
4 col_names = data['feature_names']
首先看一下这个数据集中都有什么,放一张过程中的截图。
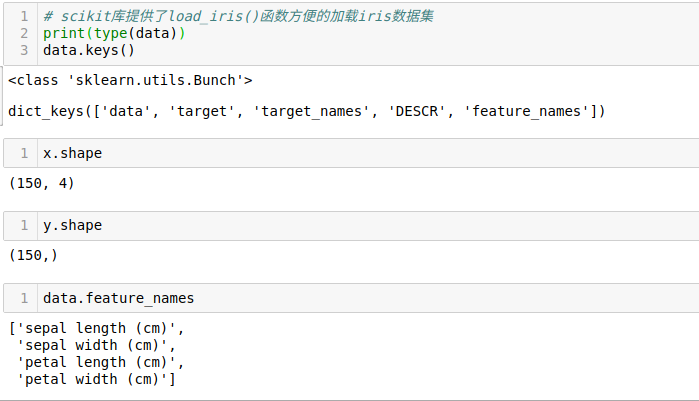
从上面以及具体内容(数据较多,可以自行查看)可以看到,x中是150x4的二维数组,对应着花萼的长度宽度和花瓣的长度宽度。y中是存储着已知的每组数据对应的花的种类,有0、1两种情况。feature_names中存了每个属性的名称。
先给出主要的程序,然后慢慢解释其中用到的知识点。
1 # 绘出6个图形,包括了以下几个列:花萼长度、花萼宽度、花瓣长度和花瓣宽度
2 plt.close('all') # 关掉其他的图像
3 plt.figure(1)
4
5 # 绘制一个3行2列的图
6 subplot_start = 321
7 col_numbers = range(0, 4)
8 # 为图形添加标签
9 col_pairs = itertools.combinations(col_numbers, 2)
10 plt.subplots_adjust(wspace = 0.5)
11
12 for col_pair in col_pairs:
13 plt.subplot(subplot_start)
14 plt.scatter(x[:,col_pair[0]], x[:,col_pair[1]], c=y)
15 plt.xlabel(col_names[col_pair[0]])
16 plt.ylabel(col_names[col_pair[1]])
17 subplot_start += 1
18 plt.show()
- #7:col_numbers = range(0, 4) 上面看到数据中包括四个属性来判断该花属于哪个类型,在程序当中也就是二维数组中列的0~3。
- #9:col_pairs = itertools.combinations(col_numbers, 2) itertools.combination可以将里面的内容组合在一起。这里由于二维更便于展示,两两组合起来绘图,观察哪些属性可以更清晰的区分出两种花来。返回一个迭代器。
- #12:循环从生成的所有两两组合中取出来,绘图。
- #14:plt.scatter(x[:,col_pair[0]], x[:,col_pair[1]], c=y) 绘制散点图,横纵轴为组合在一起的两个属性,[:,col_pair[0]]的意思就是组合中第一个属性的150个数据。
- #17: subplot_start += 1 使图像依次画在一个图形中。






