Elasticsearch集群搭建及Py
发布时间:2019-08-31 10:12:23编辑:auto阅读(2800)
- 机器: 3台物理机器,分别为130,132,134
- 操作系统:CentOS 6.6
- Elasticsearch: 2.3.3 版本
- cluster.name: 集群名称,集群名称用于跟其他相同名字的节点构成整个集群.
- node.name: 节点名称, 是该elasticsearch实例的唯一标识
- path.data: 数据路径,指定文档,索引存放的位置。
- path.logs:日志路径,指定运行日志的存放目录
- network.host: 主机名称
本文记录Elasticsearch物理集群的安装步骤,在3台机器上部署一个集群。行文顺序为整个安装过程从头到尾,期间发现不少问题。因此,本文不适合一步步跟着做,建议您看完整篇文章,然后再开始搭建集群。
1 . 环境
确保安装相应版本JDK,使用java -version确认安装。
2. 下载安装
从官网下载稳定版本:
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.3/elasticsearch-2.3.3.tar.gz拷贝到待安装的目录:
cp /home/soft/es/elasticsearch-2.3.3.tar.gz /opt/es解压:
cd /opt/es
tar -zxvf elasticsearch-2.3.3.tar.gz3.配置集群
elasticsearch的配置文件采用YAML标记语言,在config目录下:
vim elasticsearch-2.3.3/config/elasticsearch.yml需要的基本配置主要包括:
一个示例配置如下:
cluster.name: brandon-elasticsearch
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-130
#
# Add custom attributes to the node:
#
# node.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /home/data/es
#
# Path to log files:
#
path.logs: /var/log/es
network.host: 192.168.1.132
配置完成后,将整个文件copy到132和134.
scp -r elasticsearch-2.3.3 root@192.168.1.132:/opt/es
scp -r elasticsearch-2.3.3 root@192.168.1.134:/opt/es4. 启动及问题解决
完成集群配置之后,启动:
./elasticsearch-2.3.3/bin/elasticsearch出现如下异常:
java.lang.RuntimeException: don't run elasticsearch as root.
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:93)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:144)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:270)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:35)
Elasticsearch不允许使用root账号启动,因此需要建一个专用的账号。
adduser es
passwd es
chown -R es ./elasticsearch-2.3.3再次启动,还是异常:
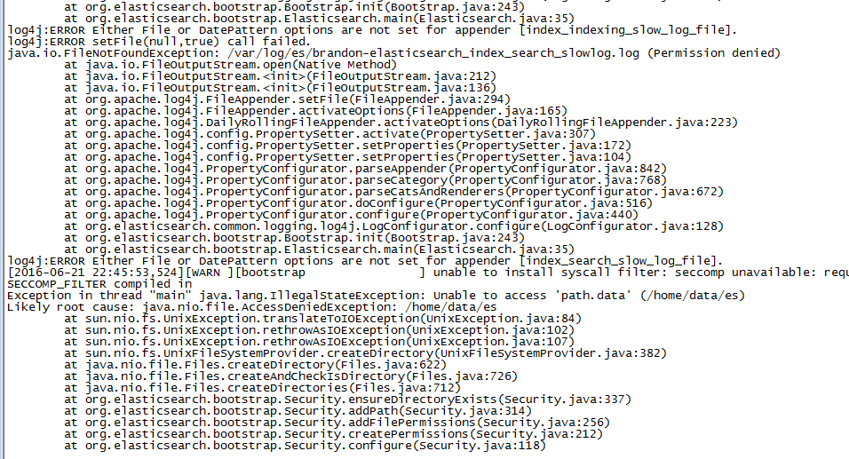
从日志可以看出是数据路径和日志路径的权限问题,修改对应文件的权限:
chown -R es /home/data/es/
chown -R es /var/log/es/其他2台机器也要一样的操作,很麻烦,尤其是在多台机器的时候,因此建议一开始就先创建账号,再安装ElasticSearch。
再启动,成功:
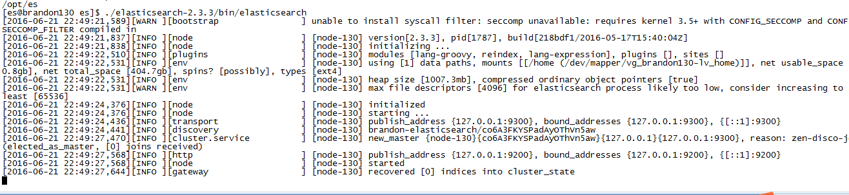
其他机器使用一样的方式启动。
查看集群信息,启动浏览器访问如下页面:http://192.168.1.132:9200/。发现集群只有一个节点,说明3台机器并没有构成一个集群,查找文档发现需要配置其他机器的ip,如下:
discovery.zen.ping.unicast.hosts: ["192.168.1.130", "192.168.1.134"] 其他节点配置类似。重新启动,从日志中可以看出32这个节点作为salve加入到master中:
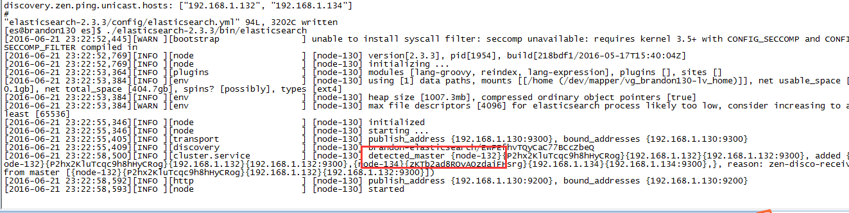

如果此时停掉master,elasticsearch将重新选举出新的master,日志可以证明这一点:

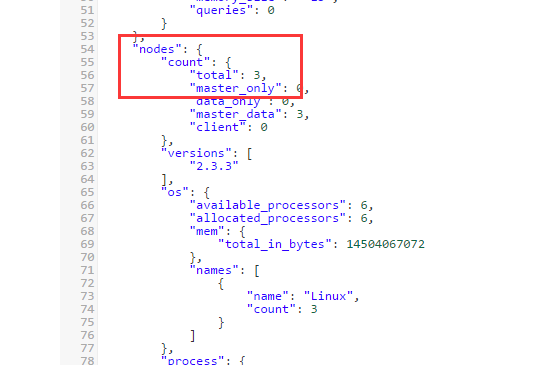
OK,现在3个节点构成集群了,查看API可以看到这一点:
http://192.168.1.132:9200/_cluster/stats?pretty
大功告成。但是用这种方式启动,一旦退出命令行,elasticsearch就会停止,有以下2中解决方案;
此时如果退出控制台,es会被关掉,解决方式:
1) 使用rpm安装,然后service elasticsearch start
2) nohup后台运行
5. 使用Python与Elasticsearch交互
Elasticsearch对外提供REST API,同时也可以使用二进制协议与其交互。各种语言的客户端都提供了相应的封装,这里以python为例说明。
我们使用elasticsearch-py,可以在这里查到相关信息。
使用pip安装:
pip install elasticsearch简单的搜索例子:
from elasticsearch import Elasticsearch
from elasticsearch import helpers
es = Elasticsearch()
res = es.get(index="megacorp", doc_type="employee", id=1)
print res
下面这个例子使用批量api,批量导入网上抓取的微博数据:
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import sys
# 设置编码,避免中文乱码
reload(sys)
sys.setdefaultencoding('utf8')
# 连接到集群,提供节点,不一定要全部节点
es = Elasticsearch(["192.168.1.130", "192.168.1.132","192.168.1.134"])
# 打开文件准备读取数据
file_name = 'E:\weibo_freshdata.2016-05-31'
wbfile = open(file_name, 'r')
actions = []
# 循环每一行
for line in wbfile:
fields = line.split('\t')
action = {
"_index": "wb",
"_type": "may",
"_id": fields[0],
"_source": {"id": fields[0], 'crawler_time': fields[1], 'crawler_time_stamp': fields[2],
'is_retweet': fields[3],
'user_id': fields[4],
'nick_name': fields[5], 'touxiang': fields[6], 'user_type': fields[7], 'weibo_id': fields[8],
'weibo_content': fields[9],
'zhuan': fields[10], 'ping': fields[11], 'zhan': fields[12], 'url': fields[13],
'device': fields[14],
'locate': fields[15],
'time': fields[16],
'time_stamp': fields[17],
'r_user_id': fields[18],
'r_nick_name': fields[19],
'r_user_type': fields[20],
'r_weibo_id': fields[21],
'r_weibo_content': fields[22],
'r_zhuan': fields[23],
'r_ping': fields[24],
'r_zhan': fields[25],
'r_url': fields[26],
'r_device': fields[27],
'r_location': fields[28],
'r_time': fields[29],
'r_time_stamp': fields[30],
'pic_content': 'http://ww3.sinaimg.cn/large/' + fields[31] + '.jpg'}
}
actions.append(action)
# 每1完条批量导入一次
if len(actions) == 10000:
# helper批量导入
helpers.bulk(es, actions)
actions = []
print "insert 10000"
if len(actions) > 0:
# 导入最后剩余的数据
helpers.bulk(es, actions)
print "finish"
(完)
上一篇: 如何在python中比较微秒时间差(mi
下一篇: 如何输出python中list的维度
- H3C基本命令大全
53518
- H3C IRF原理及 配置
40346
- Python exit()函数
34747
- python全系列官方中文文档
30503
- python 获取网卡实时流量
25378
- 1.常用turtle功能函数
25177
- python 获取Linux和Windows硬件信息
23589
- 天天基金网数据接口
18857
- Selenium使用代理IP&无头模式访问网站
15170
- Selenium&Pytesseract模拟登录+验证码识别
14676
- LangGraph Studio可视化
1144°
- LangSmith开发-应用入门
1067°
- LangGraph开发-多轮对话问答机器人
1136°
- LangGraph开发-条件分支/循环图实战
1152°
- LangGraph开发-生态介绍,入门demo实战
1188°
- LangChain-接入12306-HTTP MCP智能体
1344°
- LangChain接入自定义爬虫-MCP工具
1303°
- LangChain接入Filesystem-MCP工具
1277°
- LangChain搭建MCP服务端和客户端流程
1376°
- LangGraph与MCP技术概述
1319°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
