python spark windows
发布时间:2019-08-31 09:43:33编辑:auto阅读(2352)
- 并将 %SPARK_HOME%/bin 添加至环境变量PATH。
- 然后进入命令行,输入pyspark命令。若成功执行。则成功设置环境变量
1、下载如下
放在D盘
添加 SPARK_HOME = D:\spark-2.3.0-bin-hadoop2.7。
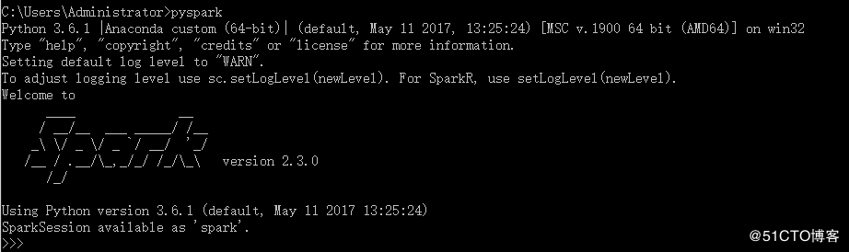
找到pycharm sitepackage目录 
右键点击即可进入目录,将上面D:\spark-2.3.0-bin-hadoop2.7里面有个/python/pyspark目录拷贝到上面的 sitepackage目录 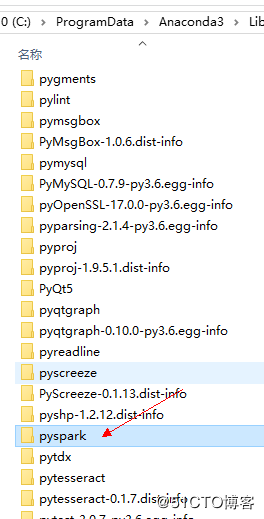
安装 py4j
试验如下代码:
from __future__ import print_function
import sys
from operator import add
import os
# Path for spark source folder
os.environ['SPARK_HOME'] = "D:\spark-2.3.0-bin-hadoop2.7"
# Append pyspark to Python Path
sys.path.append("D:\spark-2.3.0-bin-hadoop2.7\python")
sys.path.append("D:\spark-2.3.0-bin-hadoop2.7\python\lib\py4j-0.9-src.zip")
from pyspark import SparkContext
from pyspark import SparkConf
if __name__ == '__main__':
inputFile = "D:\Harry.txt"
outputFile = "D:\Harry1.txt"
sc = SparkContext()
text_file = sc.textFile(inputFile)
counts = text_file.flatMap(lambda line: line.split(' ')).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile(outputFile)计算成功即可
上一篇: k3cloud新建简单帐表教程
下一篇: python关于conda创建新环境
- H3C基本命令大全
53518
- H3C IRF原理及 配置
40346
- Python exit()函数
34747
- python全系列官方中文文档
30503
- python 获取网卡实时流量
25378
- 1.常用turtle功能函数
25177
- python 获取Linux和Windows硬件信息
23589
- 天天基金网数据接口
18857
- Selenium使用代理IP&无头模式访问网站
15170
- Selenium&Pytesseract模拟登录+验证码识别
14676
- LangGraph Studio可视化
1144°
- LangSmith开发-应用入门
1067°
- LangGraph开发-多轮对话问答机器人
1136°
- LangGraph开发-条件分支/循环图实战
1152°
- LangGraph开发-生态介绍,入门demo实战
1188°
- LangChain-接入12306-HTTP MCP智能体
1344°
- LangChain接入自定义爬虫-MCP工具
1303°
- LangChain接入Filesystem-MCP工具
1277°
- LangChain搭建MCP服务端和客户端流程
1376°
- LangGraph与MCP技术概述
1319°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
