最近在写一个应用,需要收集微博上一些热门的视频,像这些小视频一般都来自秒拍,微拍,美拍和新浪视频,而且没有下载的选项,所以只能动脑想想办法了。
第一步
分析网页源码。 例如:http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97,右键查看源码,一般视频都是mp4后缀,搜索发现没有,但是有的直接就能看到了比如美拍的视频。
第二步
抓包,分析请求和返回。这个也可以通过强大的chrome实现,还是上面的例子,右键->审查元素->NetWork,然后F5刷新网页
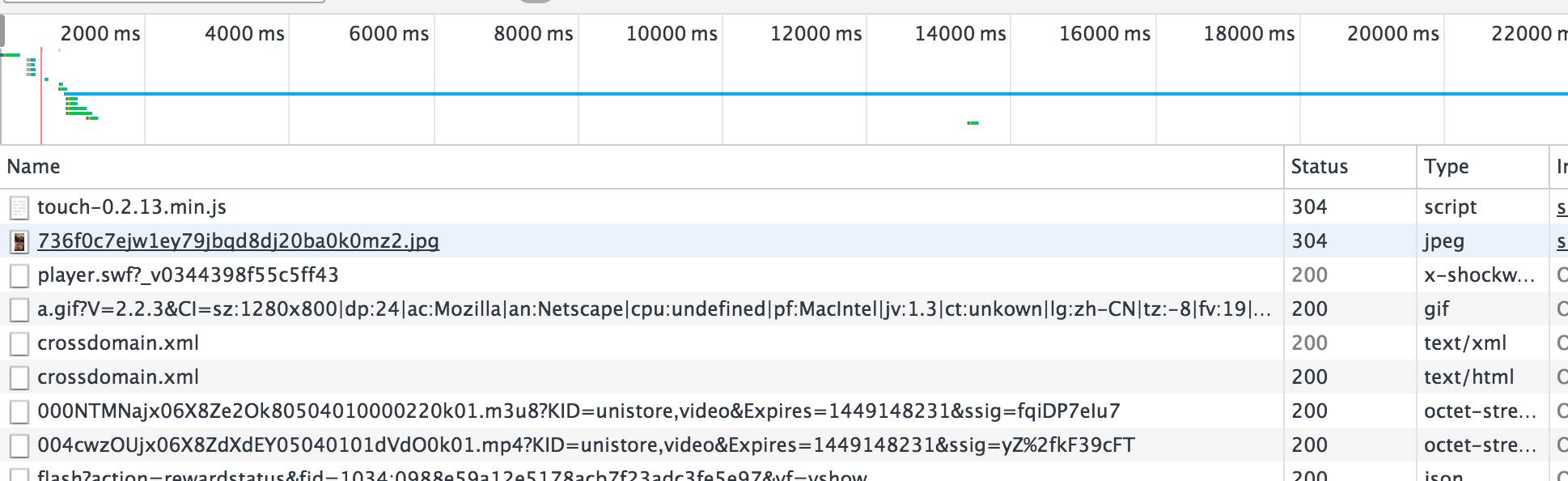
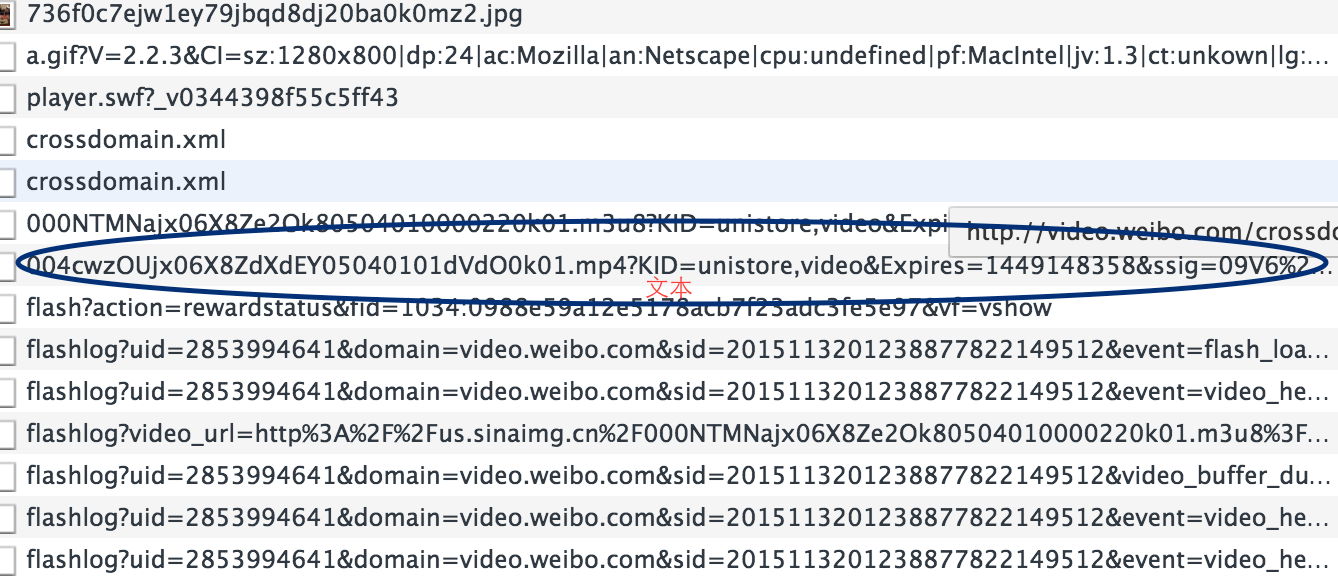
发现有很多请求,只能一条一条的分析了,其实视频格式就是那几种mp4,flv,avi了,一下就能看到了,复制到浏览器中打开,果然就是我们想要的下载链接了。
第三步
分析下载链接和视频链接的规律。即http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97与xxx.mp4的关系。这个又需要分析网页源码了,其实可以注意上面那个以.m3u8后缀的链接,m3u8记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放,打开看,里面确实记录着我们想要的下载链接。而且.m3u8后缀的链接就在网页源码中。

总结
经过前三步的分析,获取视频下载链接的思路就是先从网页源码中获取.m3u8后缀的链接,下载该文件,从里面得到视频下载链接,最后下载视频就好了
源码
#sinavideo.py #coding=utf-8 import os import re import urllib2 import urllib from common import Common class SinaVideo(): URL_PIRFIX = "http://us.sinaimg.cn/" def getM3u8(self,html): reg = re.compile(r'list=([\s\S]*?)&fid') result = reg.findall(html) return result[0] def getName(self,url): return url.split('=')[1] def getSinavideoUrl(self,filepath): f = open(filepath,'r') lines = f.readlines() f.close() for line in lines: if line[0] !='#': return line def download(self,url,filepath): #获取名称 name = self.getName(url) html = Common.getHtml(url) m3u8 = self.getM3u8(html) Common.download(urllib.unquote(m3u8),filepath,name + '.m3u8') url = self.URL_PIRFIX + self.getSinavideoUrl(filepath+name+'.m3u8') Common.download(url,filepath,name+'.mp4')
#common.py #coding=utf-8 import urllib2 import os import re class Common(): # 获取网页源码 @staticmethod def getHtml(url): html = urllib2.urlopen(url).read() print "[+]获取网页源码:"+url return html # 下载文件 @staticmethod def download(url,filepath,filename): headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Charset': 'UTF-8,*;q=0.5', 'Accept-Encoding': 'gzip,deflate,sdch', 'Accept-Language': 'en-US,en;q=0.8', 'User-Agent': 'Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.114 Mobile Safari/537.36' } request = urllib2.Request(url,headers = headers); response = urllib2.urlopen(request) path = filepath + filename with open(path,'wb') as output: while True: buffer = response.read(1024*256); if not buffer: break # received += len(buffer) output.write(buffer) print "[+]下载文件成功:"+path @staticmethod def isExist(filepath): return os.path.exists(filepath) @staticmethod def createDir(filepath): os.makedirs(filepath,0777)
调用方式:
url = "http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97" sinavideo = SinaVideo() sinavideo.download(url,""/Users/cheng/Documents/PyScript/res/"")

