python3爬虫(4)各种网站视频下载
发布时间:2019-08-07 14:07:05编辑:auto阅读(6499)
- B站视频
理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够下载下来,然而实际操作的时候也是有一定难度和技术的,这篇文章主要讲述各个网站视频资源如何下载。
页面链接:
https://www.bilibili.com/bangumi/play/ep118490?from=search&seid=7943855106424547918
首先我们用万能下载器“you-get”测试一下,下载成功,60多兆的视频文件,打开可以观看。我们在浏览器输入该网址,F12打开网络监测,回车进入该网页,点击播放视频,观看一分钟左右,为什么要观看一分钟,主要是看视频是一个链接传输,还是不停的更换视频链接,还有就是1分钟会有挺大的视频缓冲数据,明显比其他网络资源大,方便咱们分析。暂停视频,停止抓包,看到抓包栏信息如下:
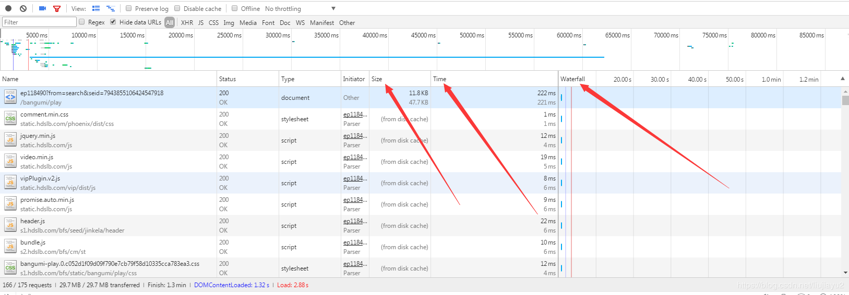
我们重点注意,Size,Time,Watefall栏,因为视频链接要返回数据,大小和花费时间明显比其他的资源大的多,滚动下看看所有信息,找到一个怀疑目标
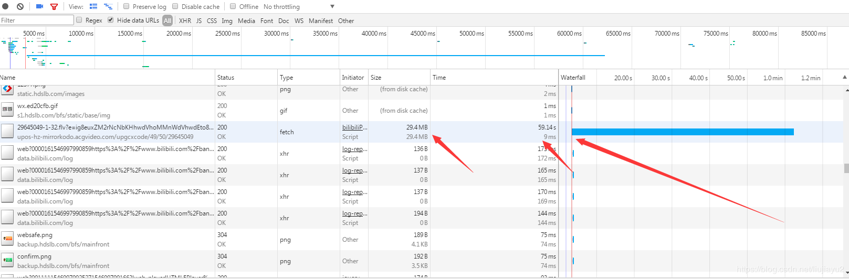
看到返回数据29.4兆,这应该就是视频资源,先别急着分析这个链接,我们再看看有无其他怀疑目标,滚动一边发现仅此一个。选中该链接,看看详细信息
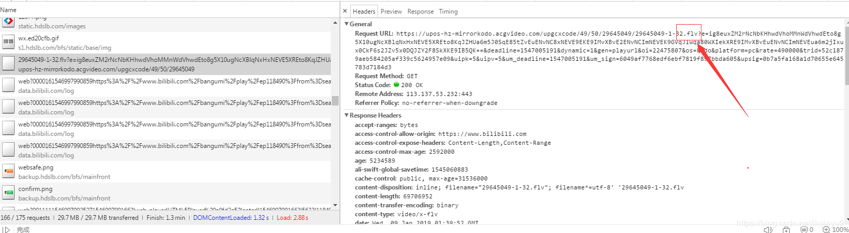
我们看到该链接是个get请求和一个关键字.flv,这个应该就是视频连接地址。
全连接如下:
这个链接结构式视频链接+参数的形式,’?’号后面都是参数,
视频链接如下:
https://upos-hz-mirrorkodo.acgvideo.com/upgcxcode/49/50/29645049/29645049-1-32.flv
把这两个地址分别输入浏览器地址栏试试,发现都没什么反应,再用浏览器自带下载工具试试(当然也可以用其他下载工具试,如迅雷),
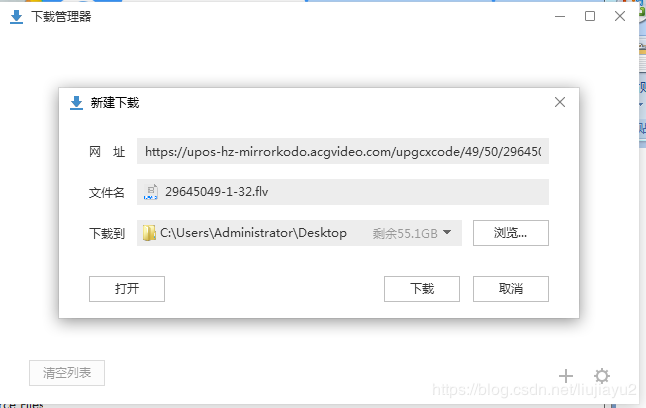
发现全连接那个下载失败,视频连接那个下载成功,下载到了60多兆的视频文件,可以播放,这样这个下载地址就算找到了,我们再试试上次用python写的简单7行代码试试,
代码链接:
发现瞬间结束,调试一下发现下载失败了,错误码:459。如下图:

这个不应该啊,估计是http请求头出了问题,我们抓下浏览器是什么头,发现浏览器自带抓包工具无法抓下载的包头,只能够抓浏览网页的头,用抓包工具Fiddler抓吧。
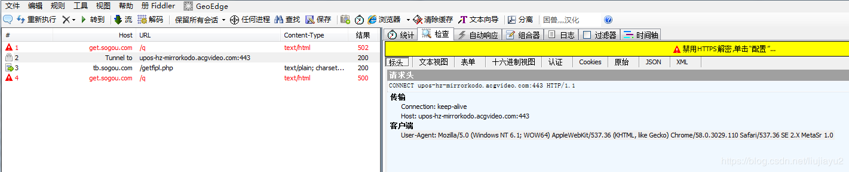
我们把这个包头写到请求里面,发现下载成功了。完整代码如下:
import requests
hd = {
'Connection':'keep-alive',
'Host':'upos-hz-mirrorkodo.acgvideo.com:443',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
}
print("开始下载")
url = 'https://upos-hz-mirrorkodo.acgvideo.com/upgcxcode/49/50/29645049/29645049-1-32.flv'
r = requests.get(url, headers=hd, stream=True)
with open('test.mp4', "wb") as mp4:
for chunk in r.iter_content(chunk_size=1024 * 1024):
if chunk:
mp4.write(chunk)
print("下载结束")
2.优酷
页面链接:
http://v.youku.com/v_show/id_XMTQ2NzQyMjY1Ng.html
还是老规矩,
首先我们用万能下载器“you-get”测试一下,下载成功,13多兆的视频文件,打开可以观看。我们在浏览器输入该网址,F12打开网络监测,回车进入该网页,点击播放视频,观看一分钟左右。暂停视频,停止抓包。观察抓包栏目,这次和上面的例子不一样,这次找了半天也没找到1个超过1兆的数据包,推测是分开传输的,经过进一步的寻找发现m3u8链接,如下图:
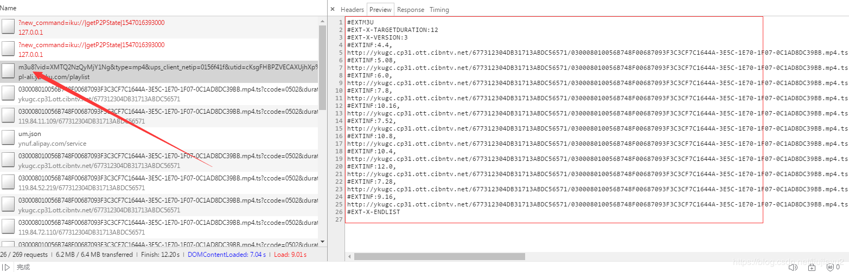
经过前面的学习我们知道这是m3u8+ts传输视频流的,具体技术请看:
我们看下这个具体细节,手工下载一下m3u8文件,可以下载,和网页端比较一下是一样的,手工下载ts列表里面的ts文件,也是可以下载的,播放一下看看,都没啥问题。这些步骤可以用下面的代码实现,前提是知道m3u8下载地址(包括地址里面的参数)
import os
import requests
"""
下载M3U8文件里的所有片段
"""
def download(url):
download_path = os.getcwd() + "\download"
if not os.path.exists(download_path):
os.mkdir(download_path)
all_content = requests.get(url).text # 获取M3U8的文件内容
file_line = all_content.split("\r\n") # 读取文件里的每一行
# 通过判断文件头来确定是否是M3U8文件
if file_line[0] != "#EXTM3U":
raise BaseException(u"非M3U8的链接")
else:
unknow = True # 用来判断是否找到了下载的地址
for index, line in enumerate(file_line):
if "EXTINF" in line:
unknow = False
# 拼出ts片段的URL
pd_url = file_line[index + 1]
res = requests.get(pd_url)
# c_fule_name = str(index)+ '.ts'
c_fule_name = "%(index)02d" % {'index': index} + '.ts'
with open(download_path + "\\" + c_fule_name, 'ab') as f:
f.write(res.content)
f.flush()
if unknow:
raise BaseException("未找到对应的下载链接")
else:
print("下载完成")
#合并的时候名字要有规律,从前往后排
def merge_file(path):
os.chdir(path)
os.system("copy /b * new.mp4")
if __name__ == '__main__':
download("http://pl-ali.youku.com/playlist/m3u8?vid=XMTQ2NzQyMjY1Ng&type=hd2&ups_client_netip=0156f41f&utid=cKsgFHBPZVECAXUjhXp%2Bu8Ip&ccode=0502&psid=244b3690aa7b9cd1c11c2f6c8ae6582b&duration=90&expire=18000&drm_type=1&drm_device=7&ups_ts=1547012701&onOff=0&encr=0&ups_key=9a7e324bb33543281964c43caa15dc80")
merge_file(os.getcwd() + "\download")
我们这个时候就考虑能否仅根据网页地址全自动下载呢,毕竟you-get可以做到全自动,我们来看看这个m3u8地址:
地址是固定的,参数才是关键,参数如下:
vid:XMTQ2NzQyMjY1Ng
type:mp4
ups_client_netip:0156f41f
utid:cKsgFHBPZVECAXUjhXp+u8Ip
ccode:0502
psid:db59c8bd03f9e26f6b21b17bccf8f1c9
duration:90
expire:18000
drm_type:1
drm_device:7
ups_ts:1547003676
onOff:0
encr:0
ups_key:49fa2661f64619e0e57d22611df8e5b7
这些参数我们猜测,应该是获取这个m3u8之前向服务器获取的,应该是以json方式返回来的,在抓包栏目里面我们找找,紧挨着这个m3u8向上找,找到了1个,
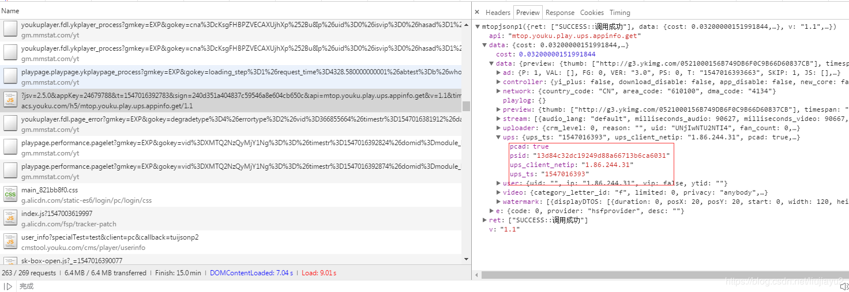
几个ups属性找到了,没有ups_key,这个估计可能是js算出来的码,不是从服务器获取到的。Vid属性可以从网址里面提取出来,type是清晰度,mp4:标清,hd:高清,hd2:超清,(我们切换清晰度,观察m3u8地址变化总结出来的),utid是个固定值,我们换个视频还是这个码,ccode, drm_type, drm_device, onOff, encr,也一样固定值;duration进过总结就是视频时长(秒),按道理来讲应该是服务器放回来的,简单找了一下没找到。先记录到这里吧。
================以下为2019/1/10 13:20 更新=======================
接着上次聊。
这个m3u8的参数:type:mp4,ups_key:49fa2661f64619e0e57d22611df8e5b7,都是不容易找到。
上次我们找到ups那个json里面当时也看了看其他节点,收获还真不小,如下图:
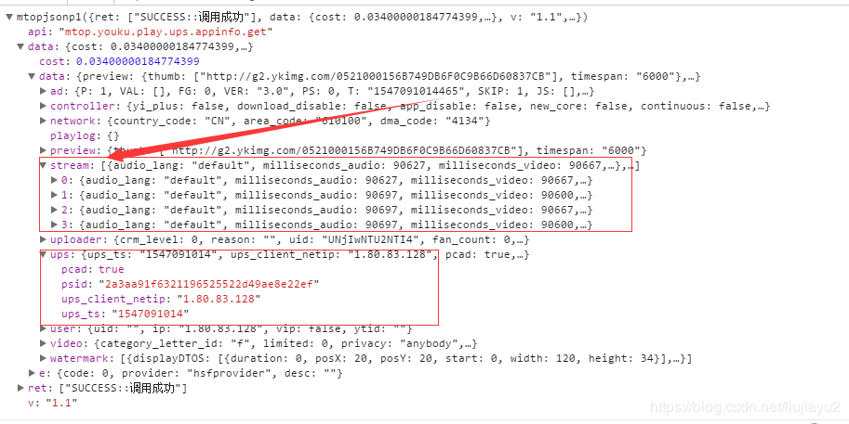
注意这个stream分支,打开他的分支0,
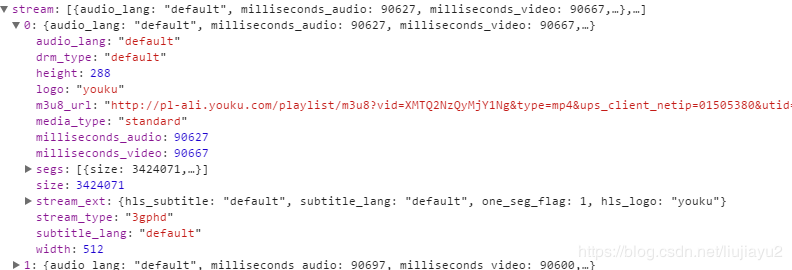
我们看到了m3u8地址,这就太好了,再往下看看,

有个cdn_url,从这个地址我们可以看出这就是一个视频链接。试着下载一下看看,就是我们在网页里面看到的视频。刚不是看到stream有4个子项吗,分别打开看看,每个子项里面都有m3u8_url和cdn_url,试了一下每个都可以下载视频,一种height属性:288,288,378,622。看下界面有,标清,高清,超清,这些应该是互相对应的。亦即只要获得了这个json其实就获取视频源头。我们看下这个请求的地址:
http://acs.youku.com/h5/mtop.youku.play.ups.appinfo.get/1.1/?jsv=2.5.0&appKey=24679788&t=1547091011531&sign=be34df75c65e2e871e720039252ee056&api=mtop.youku.play.ups.appinfo.get&v=1.1&timeout=20000&YKPid=20160317PLF000211&YKLoginRequest=true&AntiFlood=true&AntiCreep=true&type=jsonp&dataType=jsonp&callback=mtopjsonp1&data=%7B%22steal_params%22%3A%22%7B%5C%22ccode%5C%22%3A%5C%220502%5C%22%2C%5C%22client_ip%5C%22%3A%5C%22192.168.1.1%5C%22%2C%5C%22utid%5C%22%3A%5C%22cKsgFHBPZVECAXUjhXp%2Bu8Ip%5C%22%2C%5C%22client_ts%5C%22%3A1547091011%2C%5C%22version%5C%22%3A%5C%220.6.8%5C%22%2C%5C%22ckey%5C%22%3A%5C%22DIl58SLFxFNndSV1GFNnMQVYkx1PP5tKe1siZu%2F86PR1u%2FWh1Ptd%2BWOZsHHWxysSfAOhNJpdVWsdVJNsfJ8Sxd8WKVvNfAS8aS8fAOzYARzPyPc3JvtnPHjTdKfESTdnuTW6ZPvk2pNDh4uFzotgdMEFkzQ5wZVXl2Pf1%2FY6hLK0OnCNxBj3%2Bnb0v72gZ6b0td%2BWOZsHHWxysSo%2F0y9D2K42SaB8Y%2F%2BaD2K42SaB8Y%2F%2BahU%2BWOZsHcrxysooUeND%5C%22%7D%22%2C%22biz_params%22%3A%22%7B%5C%22vid%5C%22%3A%5C%22XMTQ2NzQyMjY1Ng%3D%3D%5C%22%7D%22%2C%22ad_params%22%3A%22%7B%5C%22vs%5C%22%3A%5C%221.0%5C%22%2C%5C%22pver%5C%22%3A%5C%220.6.8%5C%22%2C%5C%22sver%5C%22%3A%5C%221.0%5C%22%2C%5C%22site%5C%22%3A1%2C%5C%22aw%5C%22%3A%5C%22w%5C%22%2C%5C%22fu%5C%22%3A0%2C%5C%22d%5C%22%3A%5C%220%5C%22%2C%5C%22bt%5C%22%3A%5C%22pc%5C%22%2C%5C%22os%5C%22%3A%5C%22win%5C%22%2C%5C%22osv%5C%22%3A%5C%227%5C%22%2C%5C%22dq%5C%22%3A%5C%22auto%5C%22%2C%5C%22atm%5C%22%3A%5C%22%5C%22%2C%5C%22partnerid%5C%22%3A%5C%22null%5C%22%2C%5C%22wintype%5C%22%3A%5C%22interior%5C%22%2C%5C%22isvert%5C%22%3A0%2C%5C%22vip%5C%22%3A0%2C%5C%22emb%5C%22%3A%5C%22AjM2Njg1NTY2NAJ2LnlvdWt1LmNvbQIvdl9zaG93L2lkX1hNVFEyTnpReU1qWTFOZy5odG1s%5C%22%2C%5C%22p%5C%22%3A1%2C%5C%22rst%5C%22%3A%5C%22mp4%5C%22%2C%5C%22needbf%5C%22%3A2%7D%22%7D
看看他的参数列表:
jsv:2.5.0
appKey:24679788
t:1547091011531
sign:be34df75c65e2e871e720039252ee056
api:mtop.youku.play.ups.appinfo.get
v:1.1
timeout:20000
YKPid:20160317PLF000211
YKLoginRequest:true
AntiFlood:true
AntiCreep:true
type:jsonp
dataType:jsonp
callback:mtopjsonp1
data:{"steal_params":"{\"ccode\":\"0502\",\"client_ip\":\"192.168.1.1\",\"utid\":\"cKsgFHBPZVECAXUjhXp+u8Ip\",\"client_ts\":1547091011,\"version\":\"0.6.8\",\"ckey\":\"DIl58SLFxFNndSV1GFNnMQVYkx1PP5tKe1siZu/86PR1u/Wh1Ptd+WOZsHHWxysSfAOhNJpdVWsdVJNsfJ8Sxd8WKVvNfAS8aS8fAOzYARzPyPc3JvtnPHjTdKfESTdnuTW6ZPvk2pNDh4uFzotgdMEFkzQ5wZVXl2Pf1/Y6hLK0OnCNxBj3+nb0v72gZ6b0td+WOZsHHWxysSo/0y9D2K42SaB8Y/+aD2K42SaB8Y/+ahU+WOZsHcrxysooUeND\"}","biz_params":"{\"vid\":\"XMTQ2NzQyMjY1Ng==\"}","ad_params":"{\"vs\":\"1.0\",\"pver\":\"0.6.8\",\"sver\":\"1.0\",\"site\":1,\"aw\":\"w\",\"fu\":0,\"d\":\"0\",\"bt\":\"pc\",\"os\":\"win\",\"osv\":\"7\",\"dq\":\"auto\",\"atm\":\"\",\"partnerid\":\"null\",\"wintype\":\"interior\",\"isvert\":0,\"vip\":0,\"emb\":\"AjM2Njg1NTY2NAJ2LnlvdWt1LmNvbQIvdl9zaG93L2lkX1hNVFEyTnpReU1qWTFOZy5odG1s\",\"p\":1,\"rst\":\"mp4\",\"needbf\":2}"}
这条路走下去主要有3个难点:
难点一:
sign:cda7f7031b84db2b741d31ac4a8bec89
难点二:
ckey:115#133lN51O1TaT1YgQMCfR1Csou61hIeAacuvuZj .............
难点三:
emb:AjM2Njg1NTY2NAJ2LnlvdWt1LmNvbQIvdl9zaG93L2lkX1hNVFEyTnpReU1qWTFOZy5odG1s
这3个值不知道哪里去弄,当然按道理来讲肯定有点方去弄,只是难度有点大。
刚刚看到希望,瞬间蔫了,因为我们看了一下其他链接,返回json的不是很多,json里面有这些字段值是没有,这就有点棘手了。
回头想想,不是you-get能够获取到这个视频吗,我们看看他是怎么获得到的。打开抓包工具Fiddler,这个是名气最大的,简单看下,7个请求,其中有6个是python进程的请求,1个是浏览器sogouexplore.exe请求。
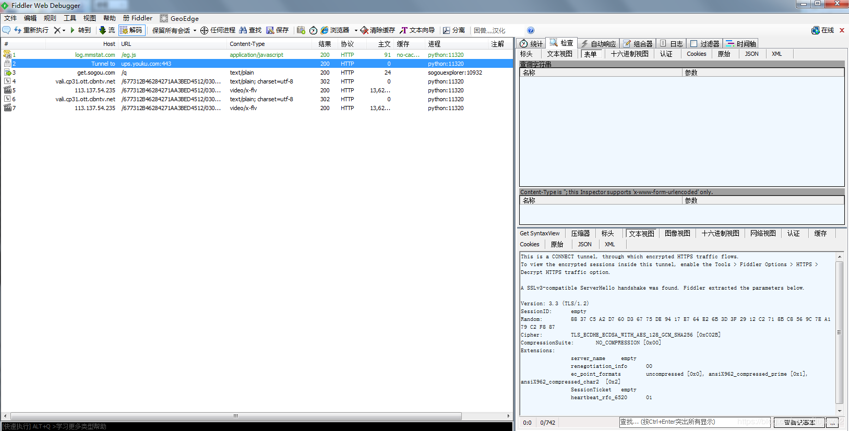
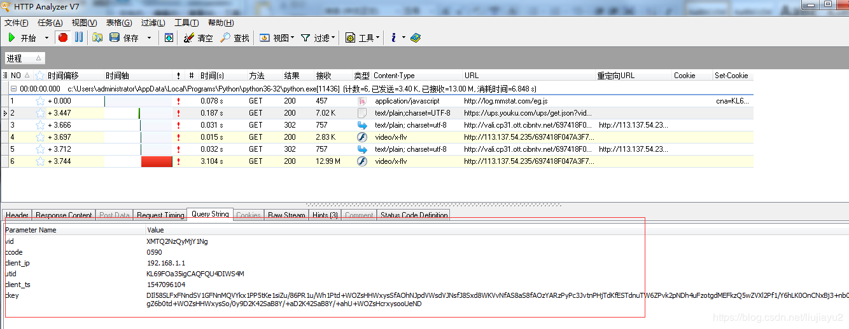
看看这个6个python请求。第一个是log.mmstat.com,第二个是https请求,后边4次好像是重复的动作,一模一样,其实是两次请求。点开https请求,发现没有什么有价值的信息,好像是Fiddler解析https需要配置什么,上次配置之后又导致浏览器不能正常访问网页。换个抓包工具吧,我下载了一个HttpAnalyzer。效果还不错,先看下抓包结果,
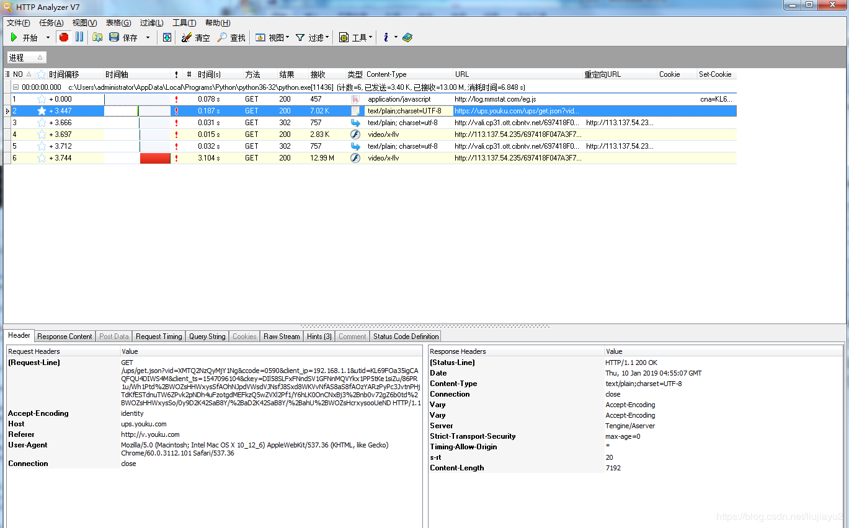
选中那个https请求,看下是能够完全解析的。返回数据支持json,data,hex,preview四种展示方式
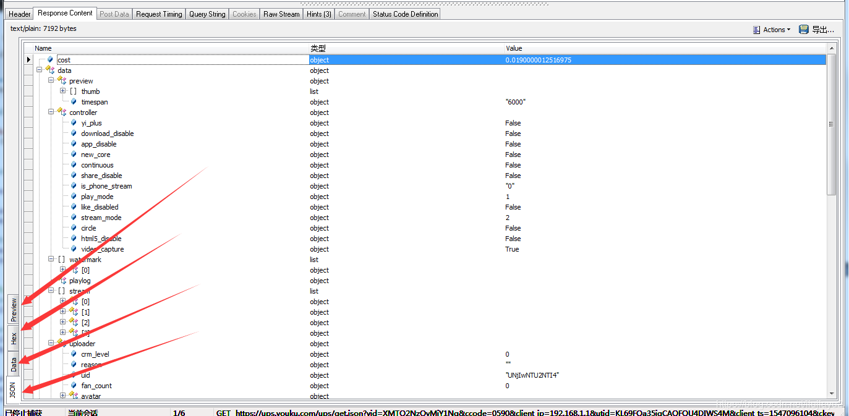
我们看下,这个返回结果其实和上面咱们那个比较长的请求结果是一样的。You-get获取到这个json之后解析了里面的cdn_url选择最清晰的下载了下来。看下他传输的时候有哪些参数,看了下这个参数少了很多,鉴于这个请求之前没有和优酷服务器通讯,我们猜测这些值都是定值,有仔细看了下client_ts字段值很想时间戳,确定了一下就是时间戳,
我们简短的写代码,模拟一下这个请求,果然成功了,返回了想要的json。这个请求这么好,浏览器里面是不是也有这个请求而我们没注意到呢?我们搜索一下ups.youku.com。看看浏览器有没发出类似的请求,
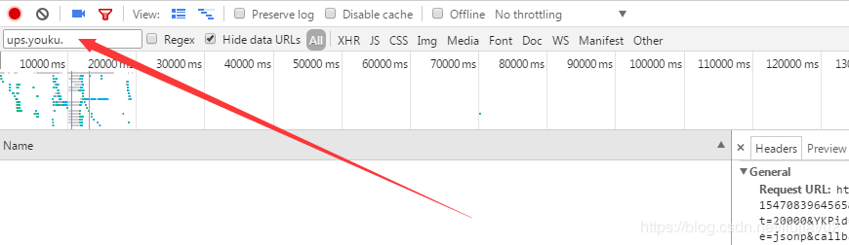
发现0个请求,也就是没有发出向这个网站的请求,那you-get又是怎么知道的呢,估计是以前版本,请求是向ups.youku.com发出的,现在更新了。既然更新了为什么老的还能用?因为整个优酷太大,前台页面有很多,更新前台页面工作量太大,所以现在服务器是新老本兼容的,只不过以后的页面都会以更新之后的出现。
第一个链接http://log.mmstat.com/eg.js是干什么的,一开始没注意,因为根据现有内容已经可以获得我们想要的内容,后来测试的路中出现问题:客户端无权播放,
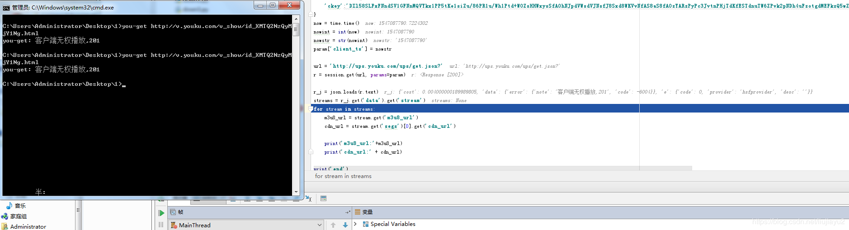
You-get也会出现类似问题,只不过概率很低,我们分一下原因,发现you-get发送请求中utid的值是变动,这个值是哪里来的?本地有个列表循环着来,不太合适吧,我们看下第一个链接http://log.mmstat.com/eg.js 正好发现了这个值。我们改下自己代码,每次请求之先获取一下这个utid,发现现在就很流畅了。
注意:
通过这次实战我们也了解到了,不会存在一种给个页面就能下载页面里面的视频的通杀方案,you-get之所以能下载大部分主流网站是因为他为每个网站都做了适配,亦即每个网站下载视频原理他都已经研究了。
源码(想要下载你的视频,将param里面的vid值改成你的地址栏的值就行了)
import requests
import time
import json
def downfile(filename, url):
r = requests.get( url, stream=True)
with open(filename, "wb") as mp4:
for chunk in r.iter_content(chunk_size=1024 * 1024):
if chunk:
mp4.write(chunk)
# 获取证书
r = requests.get('http://log.mmstat.com/eg.js')
start = len('window.goldlog=(window.goldlog||{});goldlog.Etag=\"')
end = len('window.goldlog=(window.goldlog||{});goldlog.Etag=\"66C9FJlZrDYCAQFQU4AhkzO0')
sert = r.text[start:end]
param = {
'vid':'XMTQ2NzQyMjY1Ng',
'ccode':'0590',
'client_ip':'192.168.1.1',
'utid':'2py9FNCXjUcCAQFQU4APrwPf',
'client_ts':'1547028409',
'ckey':'DIl58SLFxFNndSV1GFNnMQVYkx1PP5tKe1siZu/86PR1u/Wh1Ptd+WOZsHHWxysSfAOhNJpdVWsdVJNsfJ8Sxd8WKVvNfAS8aS8fAOzYARzPyPc3JvtnPHjTdKfESTdnuTW6ZPvk2pNDh4uFzotgdMEFkzQ5wZVXl2Pf1/Y6hLK0OnCNxBj3+nb0v72gZ6b0td+WOZsHHWxysSo/0y9D2K42SaB8Y/+aD2K42SaB8Y/+ahU+WOZsHcrxysooUeND'
}
headers = {
'Accept-Encoding': 'identity',
'Host': 'ups.youku.com',
'Referer': 'http://v.youku.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36',
'Connection': 'close'
}
now = time.time()
nowint = int(now)
nowstr = str(nowint)
param['client_ts'] = nowstr
param['utid'] = sert
url = 'http://v.youku.com/ups/get.json?'
r = requests.get(url, headers=headers, params=param)
r_j = json.loads(r.text)
streams = r_j.get('data').get('stream')
for stream in streams:
m3u8_url = stream.get('m3u8_url')
cdn_url = stream.get('segs')[0].get('cdn_url')
print('m3u8_url:' + m3u8_url)
print('cdn_url:' + cdn_url)
filename = cdn_url[len('http://ykugc.cp31.ott.cibntv.net/65720C705E33C7182E34B311F/'):len('http://ykugc.cp31.ott.cibntv.net/65720C705E33C7182E34B311F/030020010056B748030687093F3C3CF7C1644A-3E5C-1E70-1F07-0C1AD8DC39BB.mp4')]
downfile(filename,cdn_url)
print('end')
最后,现在CSDN写文章支持word拷贝带图片,赞一个,记得一年前写文章要单独上传图片,麻烦死,现在好了。。
上一篇: python3学习笔记
下一篇: apache cgi python
- H3C基本命令大全
53521
- H3C IRF原理及 配置
40349
- Python exit()函数
34750
- python全系列官方中文文档
30506
- python 获取网卡实时流量
25387
- 1.常用turtle功能函数
25181
- python 获取Linux和Windows硬件信息
23592
- 天天基金网数据接口
18866
- Selenium使用代理IP&无头模式访问网站
15172
- Selenium&Pytesseract模拟登录+验证码识别
14679
- LangGraph Studio可视化
1148°
- LangSmith开发-应用入门
1070°
- LangGraph开发-多轮对话问答机器人
1141°
- LangGraph开发-条件分支/循环图实战
1155°
- LangGraph开发-生态介绍,入门demo实战
1192°
- LangChain-接入12306-HTTP MCP智能体
1347°
- LangChain接入自定义爬虫-MCP工具
1307°
- LangChain接入Filesystem-MCP工具
1281°
- LangChain搭建MCP服务端和客户端流程
1379°
- LangGraph与MCP技术概述
1322°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
