python之列表、元组、字典
发布时间:2019-07-22 09:57:32编辑:auto阅读(2629)
一 :列表
1描述
打了激素的数组
数组是只能存储同一数据类型的结构
列表:可以存储多数数据类型的数组
2 定义列表:

元组和列表的不同:元组是不可变对象而列表是可变对象
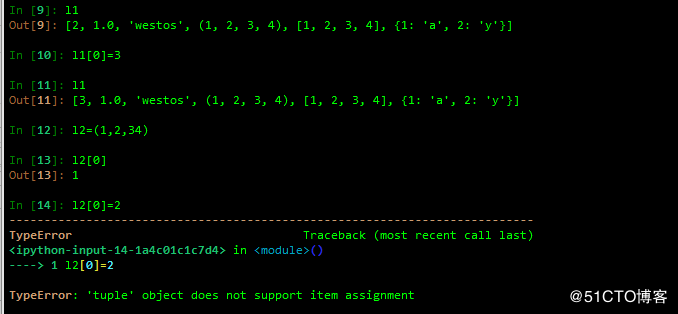
3 列表的特性:
1 索引
分为前向索引、反向索引和多重索引
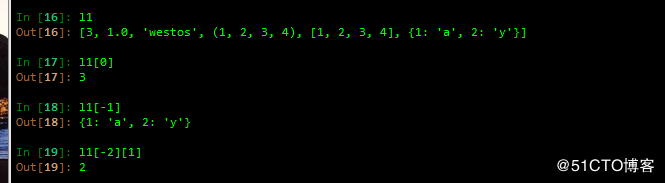
2 切片
包含一般切片和逆序显示
一般切片
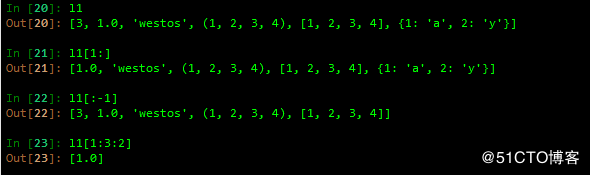
3 逆序显示

4 重复、连续
重复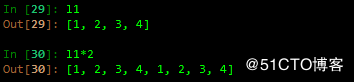
连续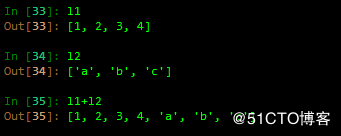
5 成员操作符
in 和 not in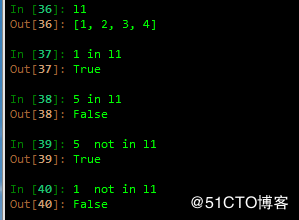
6 列表的增删改查
增
A append 在列表的结尾追加元素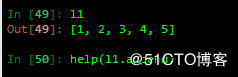
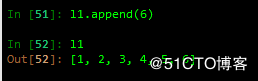
B insert 追加元素到指定位置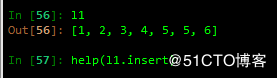

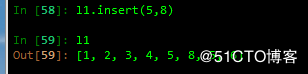
C extend 追加可迭代对象到列表结尾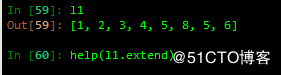

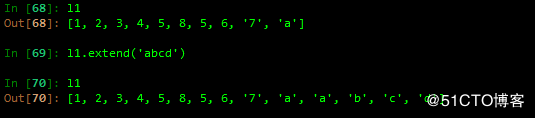
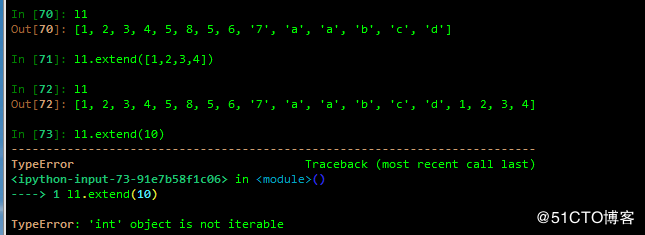
改
通过索引,对列表某个索引值进行修改
查
查看列表中某元素出现的次数 count 
查看某元素第一次出现的位置
删
删除列表中的指定元素,只删除第一次出现的元素
删除列表中指定索引的值
删除列表对象,可以在del 后面加上切片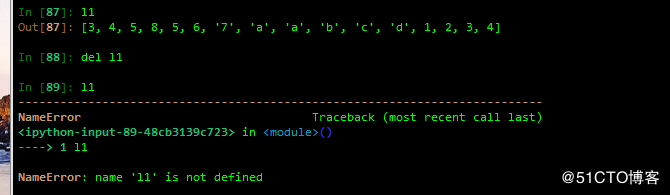
7 排序和反转
1.sort()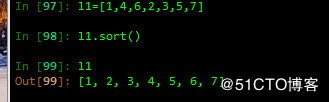
反转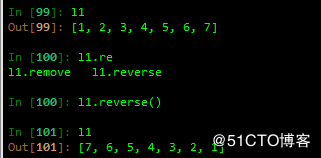
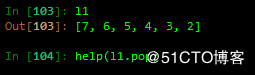
8列表元素弹出返回:
pop()默认弹出最后一个元素,可以指定要弹出元素的索引

9 列表支持python内置的方法
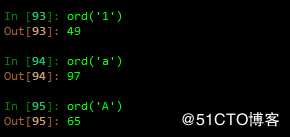
1 cmp (x,y) 比较x,y大小x,y可以是列表,比较方式是ASCII 码,获取ASCII码的方式
2 max
比较列表中元素的大小,并输出大的,也是根据ASCII码而定
3 min
比较列表中元素的大小,并输入小的,同上
4 list
将其他类型的数据结构转换为列表类型的数据结构
4 列表应用:
1 用于测试用户是否注册
#!/usr/bin/env python
#coding:utf-8
a=0
l1=['root','admin','student'] # 指定用户集合
l2=['root','admin','student'] #指定用户对应密码集合
while a\<3:
name=raw_input("请输入用户名:")
if not name in l1:
print "该用户未注册"
break
password=raw_input("请输入密码:")
index=l1.index(name)
if password==l2[index]:
print "登录成功"
break
print "ok"
else:
print "登录失败,该密码输入有误"
a+=1
else:
print "登录超过三次"2 列表构建栈和队列数据结构
1 栈是先进后出(LIFO)
2 列表是先进先出(FIFO)
栈相关的练习题
#[root@localhost ~]# cat aaa.py
#!/usr/bin/env python
#coding:utf-8
l1=[]
while True:
print '''
1>选择 1 在栈中插入数据
2>选择 2查看栈中的数据
3>选择 3 删除栈中的数据
4>选择'q'或'quit'为退出循环
'''
a=raw_input("请选择进行的操作:")
if a=='1':
b=raw_input("插入的数据:")
l1.append(b)
print "插入数据成功"
elif a=='2':
print l1
elif a=='3':
l1.pop()
elif a=='q' or a=='quit':
exit()
队列相关练习
#!/usr/bin/env python
#coding:utf-8
l1=[]
while True:
print '''
1> 在队列中插入数据
2> 查看队列中的数据
3> 删除队列中的数据
4> 选择'q'或'quit'为退出循环
'''
a=raw_input("请选择进行的操作:")
if a=='1':
b=raw_input("插入的数据:")
l1.append(b)
print "插入数据成功"
continue
elif a=='2':
print l1
elif a=='3':
del l1[0]
print "弹出数据成功"
if len(l1)==0:
print "已无数据可以弹出"
elif a=='q' or a=='quit':
exit() 3 杨辉三角
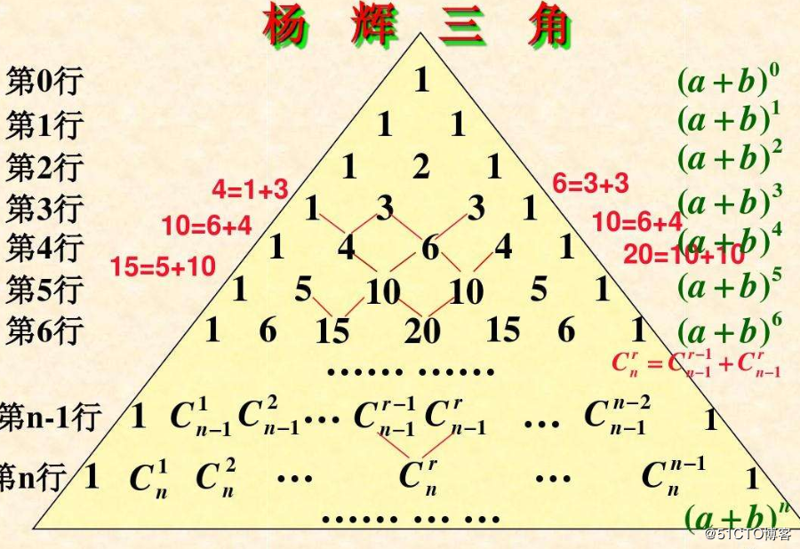
由上述图片可知,其除第0行和第1行外,后面每一行都是上方两个数字之和,因此,需要取出上一行的数据,进行相关的运算,可使用l1[-1]取出上一行的最后一个元素进行匹配操作,而后通过对其进行相关的求和操作并生成到一个列表中,然后对这个列表进行添加前后的1进行插入至总列表而完成操作。
n=int(input("请输入数字:"))
l1=[1,[1,1]]
for i in range(n):
l2=[1]
l3=l1[-1]
for i in range(len(l3)-1):
l2.append(l3[i]+l3[i+1])
l2.append(1)
l1.append(l2)
print (l1)升级版
n=int(input("请输入数:"))
l1=[]
for i in range(n):
l2=[1]
l1.append(l2) # 注入1
if i==0: #如果是1,则本次循环结束
continue
for j in range(i-1):
l2.append(l1[i-1][j]+l1[i-1][j+1]) #i-1 是获取前一个数据的值,j 和 j+1 是获取其中的对称部分的值
l2.append(1)
print (l1)结果如下 :
5 列表补充
1 效率相关:
尽量少循环。
Len 直接保存在内存中的某个位置中,其是O(1)的方式完成的
反复要使用的问题,应该经常去看,经常去处理。
reversed() 尽量少使用,过多了执行n/2次sort() 对×××的排序效率较高,但对混合类型的排序效率则变低很多
In [13]: lst.sort(key=str) #如此设置便可以排序了 ,此处的含义是将每个元素都字符串后进行比较
其可以通过自己的函数进行定义排序规则
2 == 和 is
In [1]: l1=[1,2,3,4]
In [2]: l2=[1,2,3,4]
In [3]: l1==l2
Out[3]: True
In [4]: l1 is l2
Out[4]: False
In [5]: id(l1)
Out[5]: 140287258723080
In [6]: id(l2)
Out[6]: 140287258268296
#== : 只进行数值层面的比较,不进行其他层面的比较,如内存地址层面
# is: 其进行的是内存地址层面的比较,若不符合,则直接报错
3 深拷贝和浅拷贝
1 浅拷贝: 当列表中存在有个列表时,其修改这个列表中列表的某一个元素时,其他被拷贝的列表中的对应元素也将被拷贝,其在拷贝这个列表中的列表时,拷贝的是这个内嵌列表的内存位置。
2 深拷贝: 数据完全不共享(复制其数据完完全全放独立的一个内存,完全拷贝,数据不共享)
深拷贝就是完完全全复制了一份,且数据不会互相影响,因为内存不共享。
二 字典(关联数组、散列表)
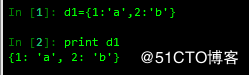
1 字典创建
1 赋值创建字典
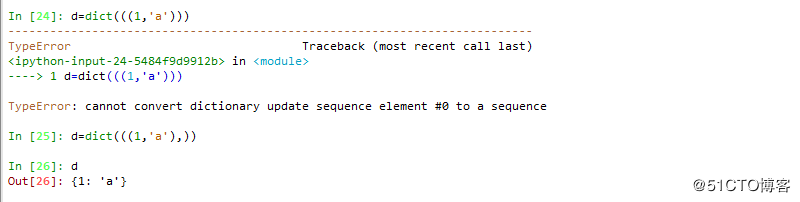
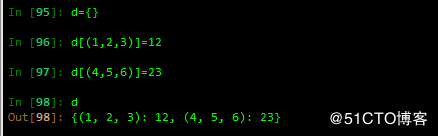
2 通过工厂函数创建字典
注: 可迭代对象的元素必须是二元数组
原因是如果没有逗号,则不是可迭代对象,如果有逗号,则其是可迭代


枚举类型: 其本身并没有数据类型,需要通过外部封装来实现其数据类型


3 通过字典的fromkeys 方法创建字典,所有元素有一个默认值


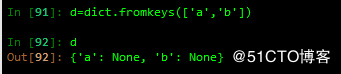
注意:相当于将同一个类型的进行重复了多次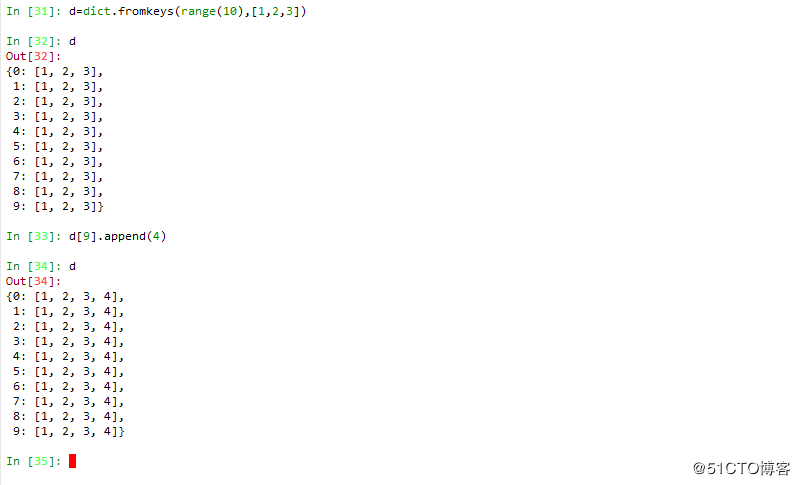
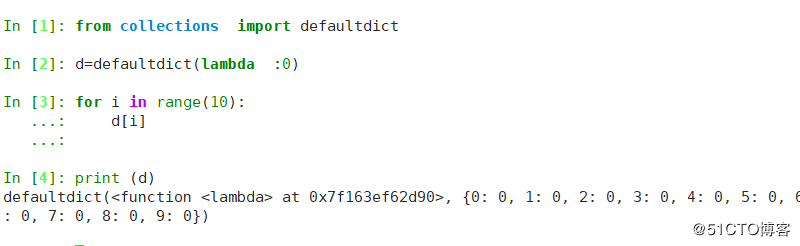
3 通过模块创建默认字典
2 分析字典的特性
字典不能索引和切片,因为字典是无序的数据类型
字典不支持重复和链接
字典支持成员操作符: 判断字典的key值是否存在于字典中
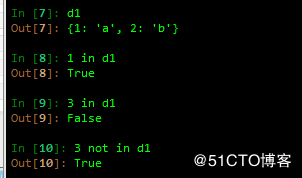
3 字典的增删改查:
1 增:
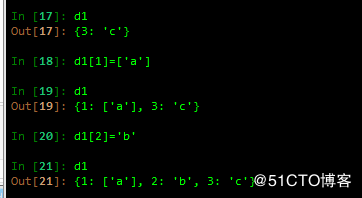
update的方式实现添加,若不存在,则添加,若存在key,则覆盖
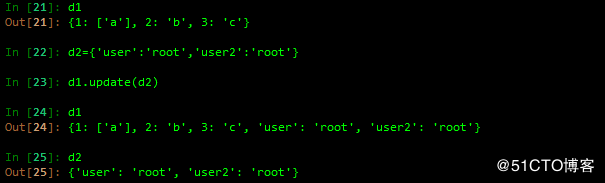

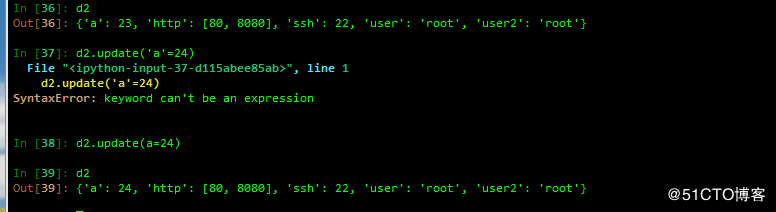
setdefault 实现添加,若key存在,则不覆盖,否则,添加

2 改

3 查
查看其key键值
查看其vlaues值
输出生成器
查看key值并取名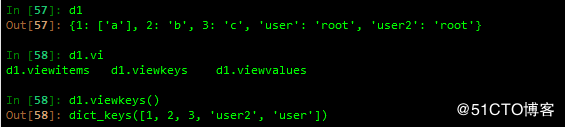
查看values值并取其名
查看字典并以元组的形式呈现,可用于对字典的遍历
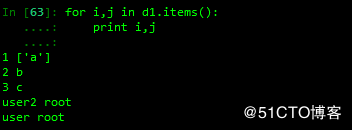
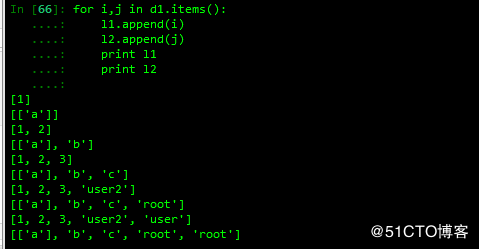
4 删
字典的弹出 pop 指定key值进行对values弹出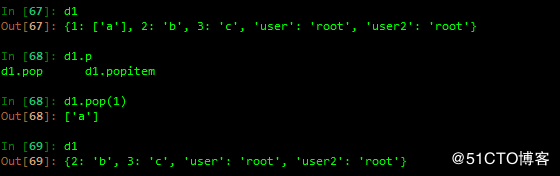
随意弹出键值对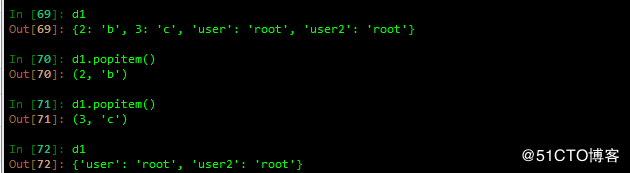
清空d1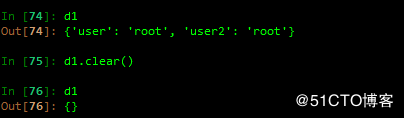
根据键删除指定的值 del,
关联删除:

删除的是对象的引用,而不是对象本身,删除的是引用计数
5 defaultdict
collections.defaultdict([default_factory[,...]])
第一个参数是default_factory,缺省值是None,其提供一个初始化函数,当key不存在时,会调用这个工厂函数来生成key对应的value。
以后可以随意变形替换其函数名即可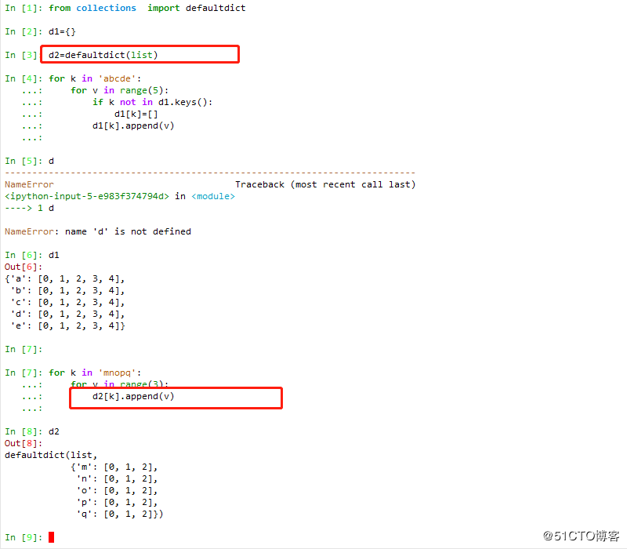
2[k]判断K是否存在,若不存在,则调用上述方法进行初始化操作
6 OrderdDict
key 的有序是指其在插入key值时的有序,不是其key值hash后的有序.
key 并不是按照加入的顺序排列的,可使用OrderedDict 记录顺序
Python3.6 实现了key记录的功能。

7 练习题
1 输入一个字符串,判断其字符出现的次数。
number=input("请输入:")
d={}
for i in number:
if not d.get(i): # 此处相当于初始化,给所有的值都赋值为0
d[i]=0
d[i]+=1 #在for 循环内层进行相关的处理
print (d)结果如下:
输入一个数字字符串,判断其出现的次数
number=input("请输入:")
l1=[0]*10
if number.isdigit():
for i in number:
if l1[int(i)]==0:
l1[int(i)]=number.count(i)
print (i,l1[int(i)])
else:
print ("请输入数字")
查看结果 
2 随机生成100个整数,范围是[-1000,1000],升序输出所有不同的数字及其重复的次数
import random
l1=[]
for i in range(100):
l1.append(random.randint(-1000,1000))
l1.sort()
d={}
for j in l1:
if not d.get(i):
d[j]=0
d[j]+=1
print (d)结果如下: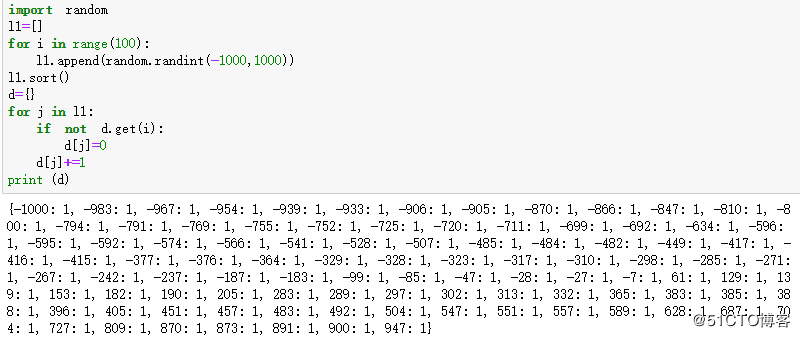
3 随机产生两个小写字母100个,降序输出这100个字符串及重复的次数
import random
import string
l1=[]
d={}
for i in range(100):
l1.append(random.choice(string.ascii_lowercase)+random.choice(string.ascii_lowercase))
l1.sort(reverse=True)
for i in l1:
if not d.get(i):
d[i]=0
d[i]+=1
print (d)结果如下

3 python 常用模块
1 random
import random
random.randint(1,100) # 输出1-100之间的随机数,包括1和100,每次输出一个 random.choice(range(1,10)) #输出1-9 之间的随机数,每次输出一个其中括号中是可迭代对象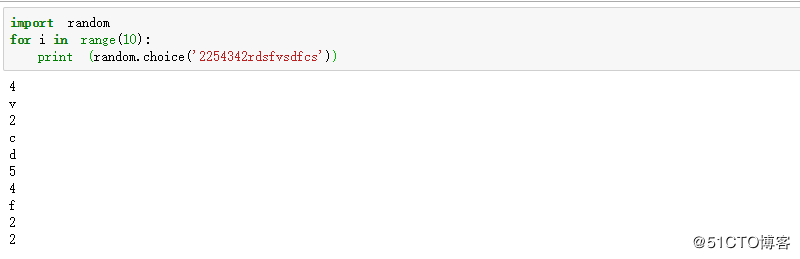
random.randrange(1,10,2) #随机选择,并从起始为1,步长为2开始选择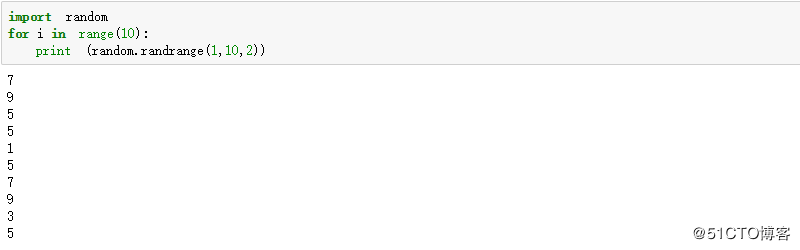
random.shuffle(l1) #打乱列表l1
2 math
1 math.ceil() # 用于取出大于等于该数的最小整数,若是整数,则其值是其本身。
print (math.ceil(10.1234))
print (math.ceil(-10.2345))
print (math.ceil(20))查看结果
2 math.exp(x) # 获取e的x 次方
print (math.exp(2))
print (math.exp(3))
3 math.fabs(x) # x 的绝对值
print (math.fabs(-10.111))
print (math.fabs(10.111))
4 math.factorial(x) #求x的阶乘
print (math.factorial(10))
print (math.fabs(5))
5 math.pow(x,y) # 求 x 的y次方
print (math.pow(2,3))
print (math.pow(4,5))
6 math.sqrt(x) # 求x 的平方跟
print (math.sqrt(2))
print (math.sqrt(9))

3 datetime 模块
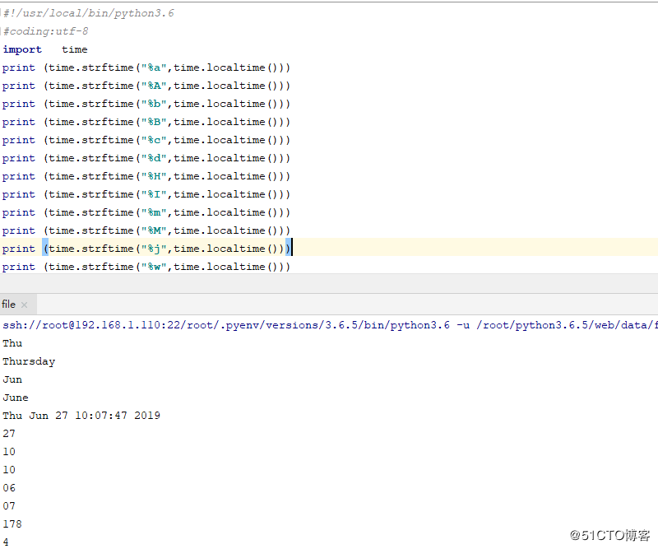
python 格式化日期常用标记
| 符号 | 说明 | 实例 | |
|---|---|---|---|
| %a | 英文星期的缩写 | Mon | |
| %A英文完整编写 | Monday | ||
| %b | 英文月份的简写 | Jun | |
| %B | 英文月份的完全编写 | June | |
| %c | 显示本地的日之前和时间 | 06/30/14 01:03:05 | |
| %I | 小时数,取值在01-12之间 | 01 | |
| %j | 显示从本年第一天开始到当前的天数 | 200 | |
| %w | 显示今天星期几,0标识星期天 | 1 | |
| %W | 显示当天属于本年的第几周,星期一作为一周的第一天 | 14 | |
| %x | 本地的当天日期 | 06/30/14 | |
| %X | 本地的当天时间 | 09:53:06 | |
| %y | 年份,取值位00-99之间 | 19 | |
| %Y | 年份的完整拼写 | 2019 | |
| %m | 月份,取值在01-12之间 | 06 | |
| %d | 日期数,取值在1-31之间 | 30 | |
| %H | 小时数,取值在00-23之间 | 01 | |
| %M | 分钟数 | 取值在01-59之间 | 26 |
| %S | 秒 | 取值在01-59之间 | 26 |
| %z | 时区 | 显示当前时区 | +0800 |
概述:
对日期、时间、时间戳进行处理
datetime类
类方法
Today()返回本地时区当前时间的datatime对象
Now(tz=None)返回当前时间的datetime对象,时间到微秒,如果tz为None,返回和today()一样 其和时区有关,一般不设置时区
Ntcnow() 没有时区的当前时间,使用的是格林威治时区
Fromtimestamp(timestamp,tz=None) 从一个时间戳返回一个datetime对象
In [1]: import datetime # 导入当前模块
In [2]: datetime.datetime.now() # 获取当前时间 ,第一个datetime 是模块名,第二个datetime是类,now是方法
Out[2]: datetime.datetime(2019, 5, 5, 16, 30, 9, 958400)
In [3]: datetime.datetime.today() # 获取当前时间
Out[3]: datetime.datetime(2019, 5, 5, 16, 32, 36, 492420)
In [5]: x=datetime.datetime.now() # 类的实例化
In [6]: x.timestamp() # 实例化后的方法
Out[6]: 1557045226.930484
In [9]: x.timestamp()
Out[9]: 1557045226.930484
In [10]: y=x.timestamp()
In [11]: datetime.datetime.fromtimestamp(y) # 通过时间戳返回时间
Out[11]: datetime.datetime(2019, 5, 5, 16, 33, 46, 930484)Datetime 对象
timestamp() 返回一个到微秒的时间戳(时间戳和时区无关)
构造方法 datetime.datetime(2018,12,6,21,10,20,123133)
year,mount,day,hour,minute,second,microsecond,取datetime对象的年月日时分秒和微秒
weekday() 返回星期的天,周一0,周日6
isoweekday() 返回星期的天,周一1,周日7
date() 返回日期date对象
time() 返回日期time对象时间戳: 格林威治时间1970年1月1日0点到现在的秒数(Unix时间)
In [5]: x=datetime.datetime.now() # 类的实例化
In [6]: x.timestamp() # 实例化后的方法
Out[6]: 1557045226.930484
In [9]: x.timestamp()
Out[9]: 1557045226.930484
In [10]: y=x.timestamp()
In [11]: datetime.datetime.fromtimestamp(y) # 通过时间戳返回时间
Out[11]: datetime.datetime(2019, 5, 5, 16, 33, 46, 930484)
In [12]: z=datetime.datetime.fromtimestamp(y) # 实例化
In [14]: z.date()
Out[14]: datetime.date(2019, 5, 5)
In [15]: z.year
Out[15]: 2019
In [16]: z.month
Out[16]: 5
In [17]: z.day
Out[17]: 5
In [21]: y
Out[21]: 1557045226.930484
In [22]: k=datetime.datetime.fromtimestamp(int(y)) # 出去小数点后面的数,则除去了毫秒和微秒
In [23]: k.date()
Out[23]: datetime.date(2019, 5, 5)
In [24]: k
Out[24]: datetime.datetime(2019, 5, 5, 16, 33, 46)
标准库datatime
日期格式化
类方法 strptime(date_string,format),返回datetime对象
对象方法 strftime(format),返回字符串
In [31]: dt=datetime.datetime.strptime('5/5/19 16:50',"%d/%m/%y %H:%M")
In [32]: dt
Out[32]: datetime.datetime(2019, 5, 5, 16, 50)
In [33]: dt.strftime("%Y-%m-%d %H:%M")
Out[33]: '2019-05-05 16:50'
In [34]: print ("{0:%Y}/{0:%m}/{0:%d} {0:%H}::{0:%M}::{0:%S}".format(dt))
2019/05/05 16::50::00timedelta 对象
datetime2=datetime1+timedelta
datetime2=datetime1-timedelta
timedelta=datetime1-datetime2
构造方法datetime.timedelta(days=0,seconds=0,microseconds=0,milliseconds=0,minutes=0,hours=0,weeks=0)
total_seconds() 返回时间差的总数
In [35]: h=datetime.timedelta(hours=24)
In [36]: datetime.datetime.now()
Out[36]: datetime.datetime(2019, 5, 5, 16, 55, 44, 238113)
In [37]: datetime.datetime.now()-h
Out[37]: datetime.datetime(2019, 5, 4, 16, 55, 47, 869107)
In [39]: n=datetime.datetime.now()
In [40]: (datetime.datetime.now()-n).total_seconds()
Out[40]: 24.047713
标准库time
time
time.sleep(secs) # 将线程挂起指定的秒数
In [41]: import time
In [42]: time.sleep(5)
4 封装和解构
1 定义
封装: 将会多个值使用逗号分隔,组合在一起
本质上,返回一个元组,只是省略了小括号
解构: 把线性结构的元素解开,并顺序的附给其他变量,左边接纳的变量数量要和右边解开的元素保持一致。
2 封装
In [1]: a=1,2
In [2]: a
Out[2]: (1, 2)3 解构
In [3]: a,b=1,2
In [4]: a
Out[4]: 1
In [5]: b
Out[5]: 2其经过了两步:
1 进行对1,2的组合,将其组合成元组。
2 使用a和b 将元组中的值进行匹配出来
In [6]: l1=[1,2,3]
In [7]: a,b,c=l1
In [8]: a
Out[8]: 1
In [9]: b
Out[9]: 2
In [10]: c
Out[10]: 3
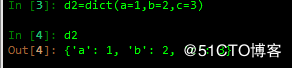
In [12]: d1=dict(a=1,b=2,c=3)
In [13]: d1
Out[13]: {'a': 1, 'b': 2, 'c': 3}
In [14]: x,y,z=d1 # 非线性的解构
In [15]: x
Out[15]: 'a'
In [16]: y
Out[16]: 'b'
In [17]: z
Out[17]: 'c'4 python 3 的解构
1 使用 * 变量名接受,但不能单独使用
In [31]: *a=s
File "<ipython-input-31-b4d5f3c4a6ce>", line 4
SyntaxError: starred assignment target must be in a list or tuple
In [32]: s
Out[32]: {1, 2, 3, 4, 6, 7}2 被 * 变量名收集后组成一个列表
In [20]: s={1,2,3,4,6,7}
In [21]: s
Out[21]: {1, 2, 3, 4, 6, 7}
In [22]: a,*b=s # * 表示尽可能多的匹配到此值
In [23]: a
Out[23]: 1
In [24]: b
Out[24]: [2, 3, 4, 6, 7]
In [25]: s
Out[25]: {1, 2, 3, 4, 6, 7}
In [26]: a,*b,c=s
In [27]: a
Out[27]: 1
In [28]: b
Out[28]: [2, 3, 4, 6]
In [29]: c
Out[29]: 73 丢弃变量
如果不关心一个变量,就可以定义改变变量的名字为.
是一个合法的标识符,也可以作为一个有效的变量使用,但定义成下划线就是希望其不要被使用,除非你明确的知道这个数据需要使用
In [33]: s
Out[33]: {1, 2, 3, 4, 6, 7}
In [34]: _,*b,_=s # _下划线标识丢弃变量
In [35]: b
Out[35]: [2, 3, 4, 6]
In [36]: _ # 第一次将其值赋值为1,第二次覆盖为7,因此其结果为7
Out[36]: 74 练习
#提取列表中的4
In [49]: l1
Out[49]: [1, (2, 3, 4), 5]
In [50]: _,[*_,a],_=l1
In [51]: a
Out[51]: 4
# 返回path和bin
In [68]: s='JAVA_HOME=/usr/bin'
In [69]: path,_,bin=s.partition('=')
In [70]: path
Out[70]: 'JAVA_HOME'
In [71]: bin
Out[71]: '/usr/bin'
5 排序法
1 交换排序法
冒泡排序法
实例如下
l1=[8,7,6,5]
第一轮排序
7 8 6 5 (对 7 和 8 进行比较,将大的放置在后端)
7 6 8 5 (对 6和 8 进行比较,将大的放在后端)
7 6 5 8 (对5 和 8 进行比较,将大的放置在后端) 此时,最大的已经在最后端,下面比较次大的数据
第二轮排序
6 7 5 8
6 5 7 8
第三轮排序
5 6 7 8
由上数结论可知,其外层循环次数是len(l1)-1次,内层循环次数是外层循环次数len(l1)-1-i 次的减少 ,代码分析如下:
l1=[8,7,6,5,4,3,2,10,4,3254,67]
for i in range(len(l1)-1):
for j in range(len(l1)-i-1):
if l1[j]>l1[j+1]:
l1[j],l1[j+1]=l1[j+1],l1[j]
print (l1) 升级版
通过在内层判断定义标志位的方式来防止原本是升序的数组再次排序
l1=[8,7,6,5,4,3,2,10,4,3254,67]
for i in range(len(l1)-1):
flag=False
for j in range(len(l1)-i-1):
if l1[j]>l1[j+1]:
l1[j],l1[j+1]=l1[j+1],l1[j]
flag=True
if not flag: # 此处结果若为True,则表明flage为flase,及其通过if判断没有进入内层交换,则表明其是顺序结构
break
print (l1)
2 选择排序法
简单选择排序
两两比较,找出极值,放置在固定位置,这个固定位置一般是指某一端,
结果分为升序和降序
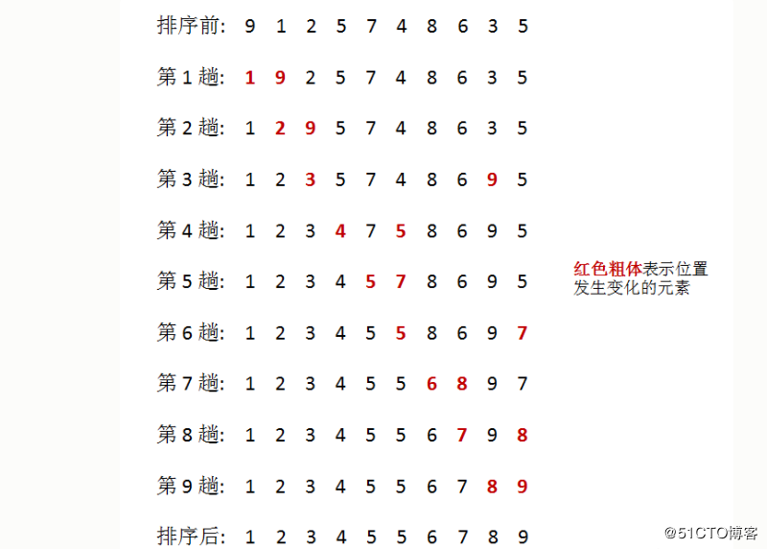
代码如下
import random
l1=[]
for i in range(10):
l1.append(random.randint(1,100)) # 生成随机数
print (l1)
for j in range(len(l1)):
maxindex=j # 指定变化的最大值对应索引,默认是未排序的第一个
for k in range(j+1,len(l1)):
if l1[k]>l1[maxindex]: # 选择替换,其比较的是第一个和其他,不是每一个和其他
maxindex=k # 进行索引替换
if j!=maxindex: # 当索引值发生改变时,则进行相关的位置置换
l1[j],l1[maxindex]=l1[maxindex],l1[j]
print (l1)结果如下:

l1=[1,2,3,5,7,8,4,67,89,90,0,3,4,75,8,6]
for i in range(len(l1)//2):
maxindex=i # 选择第一个为最大
minindex=-i-1 # 选择最后一个为最小
minorgin=minindex # 并进行最后一个的取值操作
for j in range(i+1,len(l1)-i): # 选择减去相同的数
if l1[maxindex]<l1[j]:
maxindex=j
if l1[minindex]>l1[-j-1]:
minindex=-j-1
if i != maxindex: # 改变则交换
l1[i],l1[maxindex]=l1[maxindex],l1[i]
if i == minindex or i == len(l1)+minindex: #如果最小值交换过,则需要更新索引
minindex=maxindex
if minorgin !=minindex:
l1[minindex],l1[minorgin]=l1[minorgin],l1[minindex]
print (l1)结果如下:
3 简单插入排序法
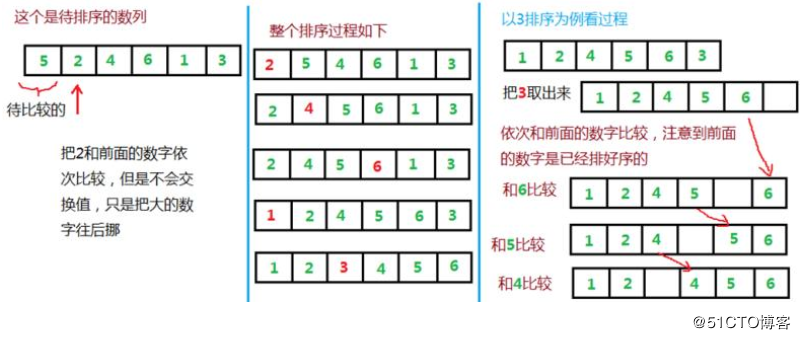
直接插入排序原理
1 增加一个哨兵位。取一个列表,增加哨兵位[0],此处是待排序位,加几无所谓,第一次就会被覆盖
2 告诉哨兵位和原始数据位
3 从第三个数字个开始 ,第一个是哨兵位,第二个是有序位
4 将第三个放入哨兵位,然后使用第三个和第二个进行比较,如果第三个小,则将当前大的覆盖到下一位, 若第三位大,则不移动第三位,进行下一轮比较
5 将比较的前一位因为经过移动而空出来的使用当前的哨兵位进行填补,因为如果哨兵位大,则不会进入移动序列,也就不会产生空缺。因此不会经过if判断。便不会有下面的将哨兵位覆盖的情况了。
l1=[random.randint(1,100) for i in range(10)]
l2=[0]+l1 #进行哨兵位的初始化
s,*orgin=l2 # 进行解构
for j in range(2,len(l2)): # 对后面的无序进行排序。默认的第一个元素是哨兵,第二个元素是有序
l2[0]=l2[j] #对哨兵位进行赋值
k=j-1# 将哨兵位和前一位进行比较
if l2[0]<l2[k]: #如果哨兵位小于前一位,则表明后面小于前面,则需要进行顺序调换
while l2[0]<l2[k]:
l2[k+1]=l2[k] # 因为前面大,因此前面需要覆盖哨兵位对应的值,此时哨兵位对应的值为大值
k-=1 # 需要将哨兵位和前一个有序序列进行比较然后进行排序
l2[k+1]=l2[0] # 此时导致哨兵位不能将其值插入,因此需要将哨兵位的值插入到指定位置,
l2.remove(l2[0])
print (l2)结果如下 
上一篇: python中mysql常用用法
下一篇: Python格式化操作符
- H3C基本命令大全
53531
- H3C IRF原理及 配置
40353
- Python exit()函数
34756
- python全系列官方中文文档
30515
- python 获取网卡实时流量
25393
- 1.常用turtle功能函数
25183
- python 获取Linux和Windows硬件信息
23597
- 天天基金网数据接口
18871
- Selenium使用代理IP&无头模式访问网站
15174
- Selenium&Pytesseract模拟登录+验证码识别
14687
- LangGraph Studio可视化
1151°
- LangSmith开发-应用入门
1073°
- LangGraph开发-多轮对话问答机器人
1143°
- LangGraph开发-条件分支/循环图实战
1162°
- LangGraph开发-生态介绍,入门demo实战
1198°
- LangChain-接入12306-HTTP MCP智能体
1353°
- LangChain接入自定义爬虫-MCP工具
1312°
- LangChain接入Filesystem-MCP工具
1286°
- LangChain搭建MCP服务端和客户端流程
1383°
- LangGraph与MCP技术概述
1327°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
