python爬取主播信息
发布时间:2019-07-11 09:55:55编辑:auto阅读(2686)
之前学过python的爬虫技术,现在回顾一下看看还会不会,果然有坑。
先爬取了微博评论网友的id
代码如下
import requests
url = 'https://m.weibo.cn/api/comments/show?id=4188633986790962&page=6
h = requests.get(url)
print(h.json()['data']['data'][0]['user']['id'])
执行的时候报错
Traceback (most recent call last):
File "e:/personal/vscode/pameinv.py", line 9, in <module>
print(a())
File "e:/personal/vscode/pameinv.py", line 8, in a
return html.json()
File "D:\python\Python37\lib\site-packages\requests\models.py", line 897, in json
return complexjson.loads(self.text, **kwargs)
File "D:\python\Python37\lib\json__init__.py", line 348, in loads
return _default_decoder.decode(s)
File "D:\python\Python37\lib\json\decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "D:\python\Python37\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
于是开始各种调试 最后换了一个地址行了,可能是微博的api不让调用了
于是修改了一下程序
import requests
url = 'http://www.yy.com/api/yyue-spot-news'
h = requests.get(url)
for j in range(len(h.json()['data'])):
print(h.json()['data'][j]['id']) #这里有缩进
print里的内容是根据网页里的相应信息而定的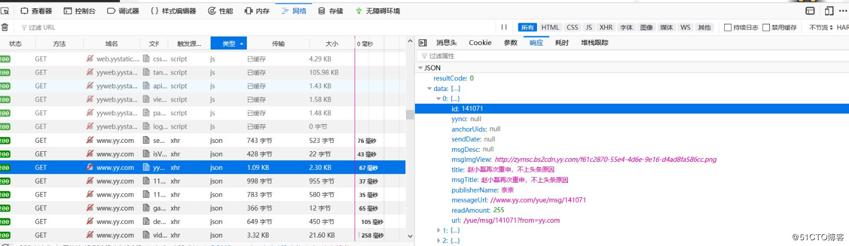
最后运行了一下 成功显示了主播的id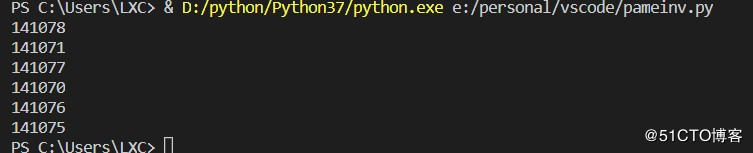
上一篇: Python最简编码规范
下一篇: Catalyst2层交换的3层通信
- H3C基本命令大全
53484
- H3C IRF原理及 配置
40312
- Python exit()函数
34722
- python全系列官方中文文档
30471
- python 获取网卡实时流量
25350
- 1.常用turtle功能函数
25141
- python 获取Linux和Windows硬件信息
23557
- 天天基金网数据接口
18779
- Selenium使用代理IP&无头模式访问网站
15133
- Selenium&Pytesseract模拟登录+验证码识别
14646
- LangGraph Studio可视化
1107°
- LangSmith开发-应用入门
1030°
- LangGraph开发-多轮对话问答机器人
1098°
- LangGraph开发-条件分支/循环图实战
1110°
- LangGraph开发-生态介绍,入门demo实战
1144°
- LangChain-接入12306-HTTP MCP智能体
1298°
- LangChain接入自定义爬虫-MCP工具
1265°
- LangChain接入Filesystem-MCP工具
1240°
- LangChain搭建MCP服务端和客户端流程
1338°
- LangGraph与MCP技术概述
1278°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
