python len isalpha 中
发布时间:2019-09-26 11:36:15编辑:auto阅读(2944)
近期在进行自然语言的处理,在使用len函数和isalpha函数时发现几个坑。现在略述一下,才疏学浅还请大牛批评指正。
len和isalpha函数对于str类型或者unicode类型的英文都有效,但是对于中文就要区别对待了!对于中文来说,在python2.7默认字符编码类型下,一个中文字符占两个(windows环境)或者三个(ubuntu系统)字符,所以此时len函数返回的是:真实字符数目*2或者3,而英文符号还是一个字符,所以len返回真实的英文数目。在unicode编码下,一个中文字符占一个unicode码,所以len返回真实字符数目,同样英文字符也是占一个unicode编码,返回真实字符数目。
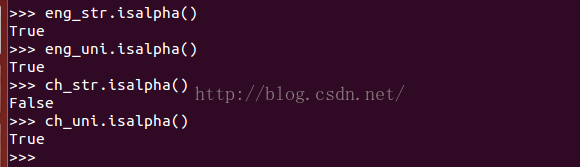
isalpha函数是针对python2.7默认字符编码下的字符串设计的,所不适用于unicode编码,在unicode编码下会出错。具体请看下面的代码例子。
一.关于len的例子
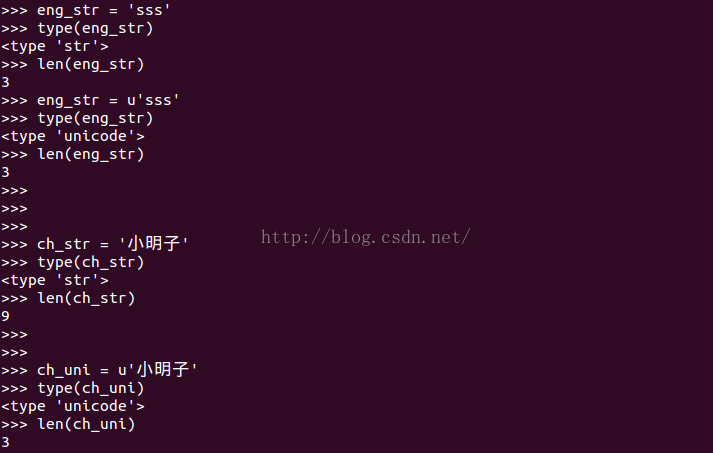

上面是在ubuntu中运行的,下面是window中运行的。
二.关于isalpha的例子
三.str(),decode(),encode()的使用区别
我们知道数据类型有:string,int,float等,这些类型相互转换使用str()
string有很多字符编码,ascii,unicode,gbk,这些编码间相互转化使用decode和encode
上一篇: python 日志记录
下一篇: 用python处理MS Word
- H3C基本命令大全
53421
- H3C IRF原理及 配置
40266
- Python exit()函数
34664
- python全系列官方中文文档
30410
- python 获取网卡实时流量
25303
- 1.常用turtle功能函数
25095
- python 获取Linux和Windows硬件信息
23498
- 天天基金网数据接口
17926
- Selenium使用代理IP&无头模式访问网站
15087
- Selenium&Pytesseract模拟登录+验证码识别
14600
- LangGraph Studio可视化
1016°
- LangSmith开发-应用入门
948°
- LangGraph开发-多轮对话问答机器人
1012°
- LangGraph开发-条件分支/循环图实战
1020°
- LangGraph开发-生态介绍,入门demo实战
1061°
- LangChain-接入12306-HTTP MCP智能体
1209°
- LangChain接入自定义爬虫-MCP工具
1184°
- LangChain接入Filesystem-MCP工具
1176°
- LangChain搭建MCP服务端和客户端流程
1268°
- LangGraph与MCP技术概述
1201°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
