如何使用python3抓取微信公众号文章
发布时间:2019-09-26 07:27:17编辑:auto阅读(2605)
- 打开https://mp.weixin.qq.com
- 登录公众号,打开素材管理,点击新建分享图文
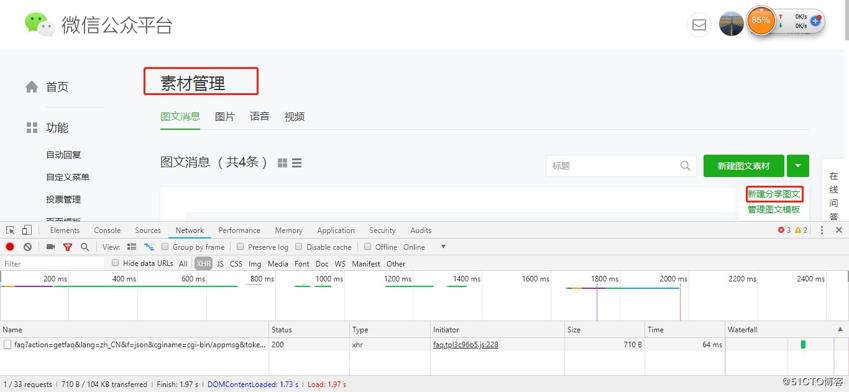
- 打开一个文章搜索接口
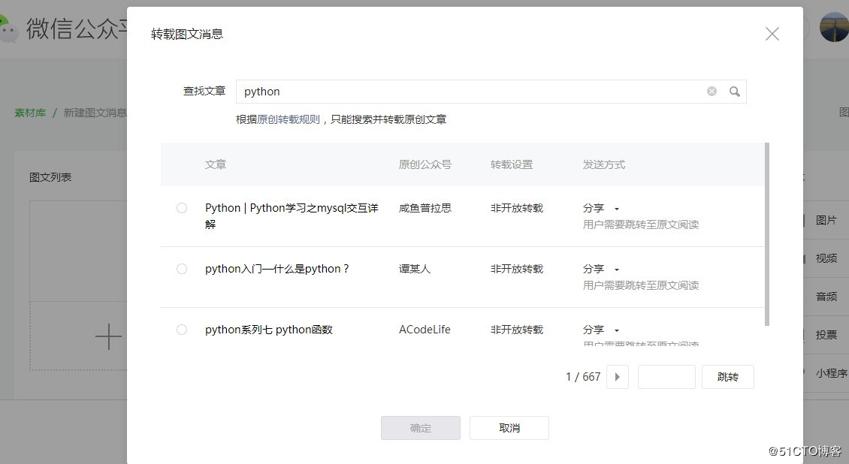
- 输入要搜索的内容后,可以搜索到相关文章的标题、出自哪个公众号等信息。
-
这里有一个问题,打开微信公众平台首页,输入账号密码后需要使用管理的微信号扫码确认一下才能最终成功登录微信公众号,这个要怎么解决呢?
-
我们可以第一次登录的时候按正常的流程输入账号密码,扫码登录,拿到cookies,保存下来以便后面调用这个cookies来验证登录;当然cookies是有失效时间的,但是我在测试的时候好像过了3-4个小时还能用,够做好多事情了。
- 基本思路:1.通过selenium驱动浏览器 打开登录页面 ,输入账号密码登录 ,获取登录后的cookies,保存cookies以便调用;2.拿到cookies之后 ,去请求首页 登录后直接跳转到个人首页,打开文章搜索框,找一些需要的信息;3.拿到有用的信息后,构造data数据包 ,模拟post请求, 然后返回数据,拿到数据之后 ,解析出我们需要的数据。
- 运行结果如下:
- search.txt里保存的内容如下:
- 只要有一个微信公众号就可以实现,可以注册一个试一试。
通过微信公众平台的查找文章接口,抓取我们需要的相关文章
1.首先我们先看一下,通过正常的登录自己的微信公众号,然后用文章搜索功能,搜索一下我们需要查找的相关文章。
2.实现思路
3.获取cookies,话不多说,贴个代码
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
from selenium import webdriver
import time
import json
driver = webdriver.Chrome() #需要一个谷歌驱动chromedriver.exe,要支持你当前谷歌浏览器的版本
driver.get('https://mp.weixin.qq.com/') #发起get请求打开微信公众号平台登录页面,然后输入账号密码登录微信公众号
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').clear() #定位到账号输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').send_keys('这里输入你的账号') #定位到账号输入框,输入账号
time.sleep(3) #等待3秒后执行下一步操作,避免因为网络延迟,浏览器来不及加载出输入框,从而导致以下的操作失败
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').clear() #定位到密码输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').send_keys('这里输入你的密码') #定位到密码输入框,输入密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[3]/label').click() #点击记住密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[4]/a').click() #点击登录
time.sleep(15) #15秒内扫码登录
cookies = driver.get_cookies() #获取扫码登录成功之后的cookies
print(cookies) #打印出来看看,如果超时了还不扫码,获取到的cookies是不完整的,不能用来登录公众号,所以第一次必须扫码登录以获取完整的cookies
cookie = {} #定义一个空字典,以便把获取的cookies以字典的形式写入
for items in cookies: #把登录成功后获取的cookies提取name和value参数写入空字典cookie
cookie[items.get('name')] = items.get('value')
with open('cookies.txt','w') as file: #新建并打开一个cookies.txt文件
file.write(json.dumps(cookie)) #写入转成字符串的字典
driver.close() #关闭浏览器4.新建一个py文件,代码如下
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import requests
import json
import re #正则模块
import random #随机数模块
import time
#query = 'python'
#读取之前登录后保存的cookies
with open('cookies.txt','r') as file:
cookie = file.read()
url = 'https://mp.weixin.qq.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&share=1&token=773059916&lang=zh_CN',
'Host': 'mp.weixin.qq.com',
}
cookies = json.loads(cookie) #加载之前获取的cookies
print(cookies) #可以打印看看,和之前保存的cookies是一样的
response = requests.get(url, cookies = cookies) #请求https://mp.weixin.qq.com/,传cookies参数,登录成功
token = re.findall(r'token=(\d+)',str(response.url))[0] #登录成功后,这是的url里是包含token的,要把token参数拿出来,方便后面构造data数据包发起post请求
#print(token)
#random.random()返回0到1之间随机数
#构造data数据包发起post请求
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': 'python',
'begin': '0',
'count': '3',
}
search_url = 'https://mp.weixin.qq.com/cgi-bin/operate_appmsg?sub=check_appmsg_copyright_stat' #按F12在浏览器里找post请求的url(搜索文章请求的url)
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers) #发起post请求,传cookies、data、headers参数
max_num = search_response.json().get('total') #获取所有文章的条数
num = int(int(max_num/3)) #每页显示3篇文章,要翻total/3页,不过实际上我搜索了几个关键词,发现微信公众号文章搜索的接口最多显示667页,其实后面还有页数,max_num/3的结果大于667没关系
if __name__ == '__main__':
query = input('请输入你要搜索的内容:')
begin = 0
while num +1 > 0:
print(begin)
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': query,
'begin': '{}'.format(str(begin)),
'count': '3',
}
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers)
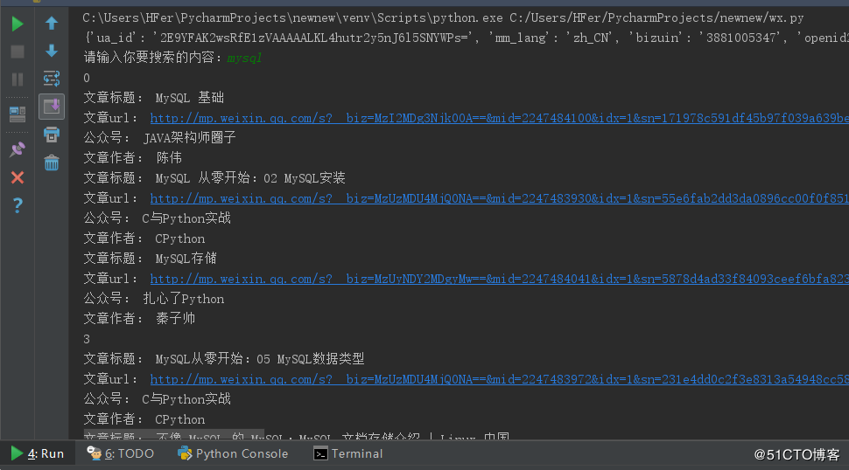
contentt = search_response.json().get('list') #list里面是我们需要的内容,所以要获取list
for items in contentt: #具体需要list里面的哪些参数可以自己选择,这里只获取title、url、nickname、author
f = open('search.txt',mode='a',) #打开一个txt文档,把获取的内容写进去,mode='a'是追加的方式写入,不覆盖
print('文章标题:',items.get('title')) #获取文章标题
f.write('文章标题:')
f.write(items.get('title'))
f.write("\n")
f.write('文章url:')
f.write(items.get('url'))
f.write("\n")
f.write('公众号:')
f.write(items.get('nickname'))
f.write("\n")
f.write('作者:')
f.write(items.get('author'))
f.write("\n")
f.write("\n")
print('文章url:',items.get('url')) #获取文章的url
print('公众号:',items.get('nickname')) #获取出自哪个微信公众号
print('文章作者:',items.get('author')) #获取文章作者
num -= 1
begin = int(begin)
begin += 3
time.sleep(3)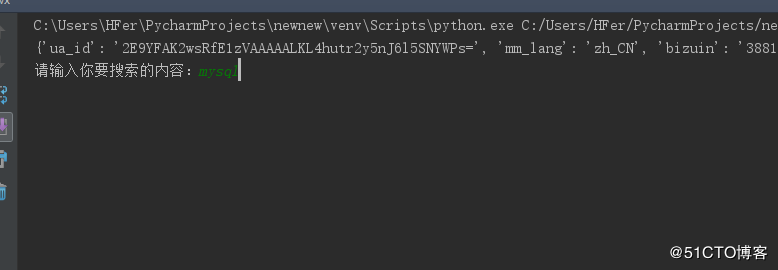

上一篇: python3 列表内多个字典 相同
下一篇: python3实现excel里面读数据进
- H3C基本命令大全
53410
- H3C IRF原理及 配置
40259
- Python exit()函数
34659
- python全系列官方中文文档
30399
- python 获取网卡实时流量
25296
- 1.常用turtle功能函数
25088
- python 获取Linux和Windows硬件信息
23486
- 天天基金网数据接口
17767
- Selenium使用代理IP&无头模式访问网站
15078
- Selenium&Pytesseract模拟登录+验证码识别
14591
- LangGraph Studio可视化
1001°
- LangSmith开发-应用入门
929°
- LangGraph开发-多轮对话问答机器人
1000°
- LangGraph开发-条件分支/循环图实战
1009°
- LangGraph开发-生态介绍,入门demo实战
1048°
- LangChain-接入12306-HTTP MCP智能体
1195°
- LangChain接入自定义爬虫-MCP工具
1172°
- LangChain接入Filesystem-MCP工具
1168°
- LangChain搭建MCP服务端和客户端流程
1260°
- LangGraph与MCP技术概述
1196°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
