python3使用PIL、tessera
发布时间:2019-09-25 08:26:07编辑:auto阅读(3045)
第一步:下载安装包
根据https://github.com/tesseract-ocr/tesseract/wiki 我找到非官方的安装包,好像我只看到64位的安装包http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
下载后直接安装即可,但是要记得你的安装目录,我们等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁体字识别包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
或者直接我的百度云盘:链接:tesseract 密码:tmdm
第二步:安装
直接执行下载好的tesseract-ocr-setup-4.0.0-alpha.20180109.exe,下一步、下一步安装。安装过程中,会让你安装额外的语言包,可根据选择下载。
第三步:配置环境变量
我的是安装在C:\Program Files (x86)\Tesseract-OCR,界面如下: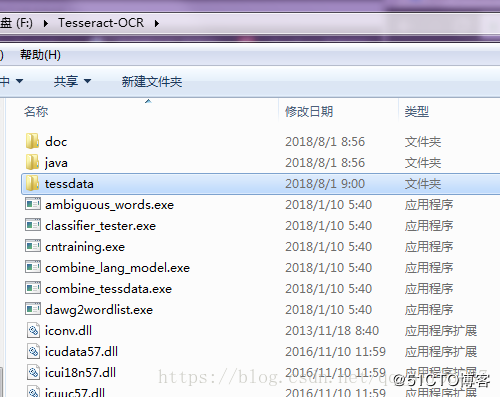
将“F:\Tesseract-OCR”添加到环境变量中。如图:
增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径F:\Tesseract-OCR\tessdata这是将语言字库文件夹添加到变量中;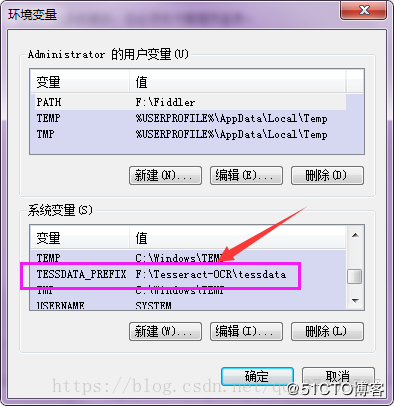
三、使用
打开命令终端,输入:tesseract -v,可以看到版本信息
用命令tesseract --list-langs来查看Tesseract-OCR支持语言。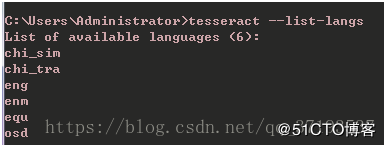
四、修改配置文件
在pycharm中添加pytesseract架包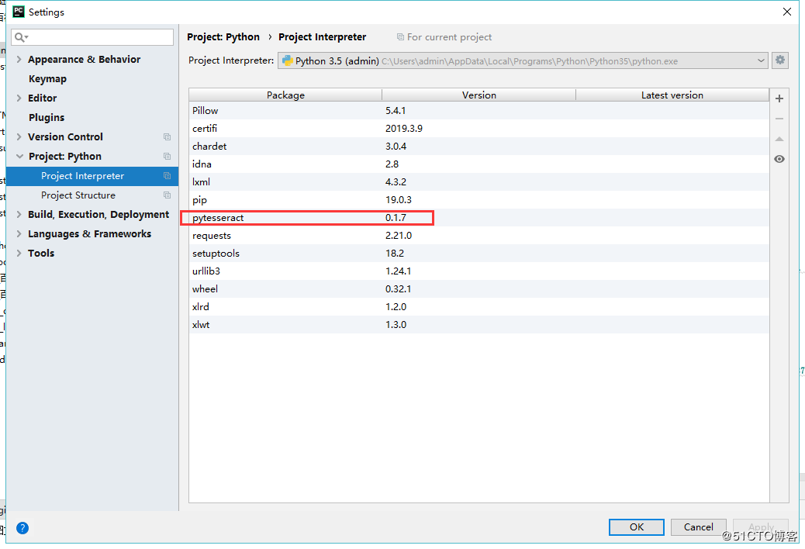
添加完成后,在代码模块中引用,前往源文件中指定Tesseract-OCR的安装目录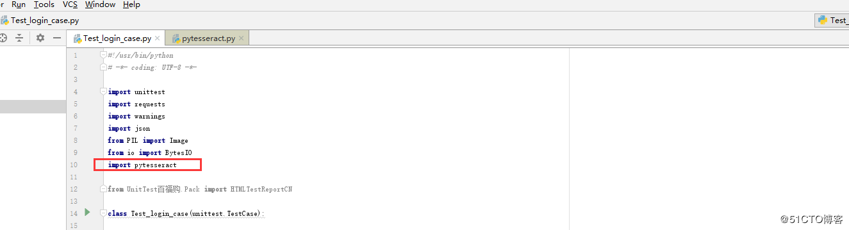
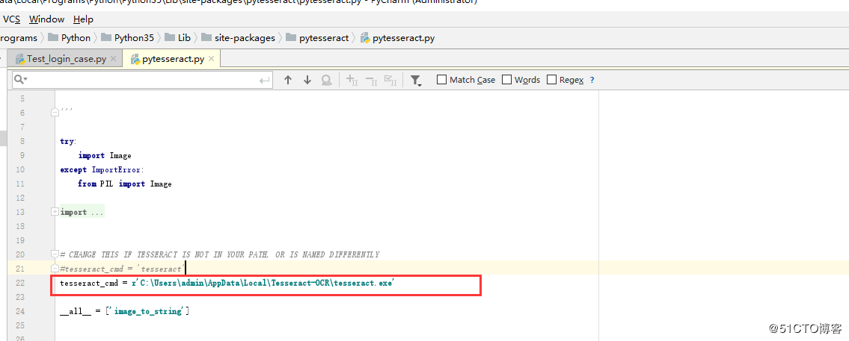
这样就可以将图片中的内容打印出来!
转载地址:https://blog.csdn.net/qq_37193537/article/details/81335165
上一篇: Python3实现快速排序、归并排序、堆
下一篇: windows7 python3和pyt
- H3C基本命令大全
53428
- H3C IRF原理及 配置
40270
- Python exit()函数
34669
- python全系列官方中文文档
30416
- python 获取网卡实时流量
25306
- 1.常用turtle功能函数
25097
- python 获取Linux和Windows硬件信息
23500
- 天天基金网数据接口
18002
- Selenium使用代理IP&无头模式访问网站
15089
- Selenium&Pytesseract模拟登录+验证码识别
14603
- LangGraph Studio可视化
1032°
- LangSmith开发-应用入门
964°
- LangGraph开发-多轮对话问答机器人
1029°
- LangGraph开发-条件分支/循环图实战
1038°
- LangGraph开发-生态介绍,入门demo实战
1077°
- LangChain-接入12306-HTTP MCP智能体
1228°
- LangChain接入自定义爬虫-MCP工具
1201°
- LangChain接入Filesystem-MCP工具
1184°
- LangChain搭建MCP服务端和客户端流程
1277°
- LangGraph与MCP技术概述
1210°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
