使用python访问网页
发布时间:2019-09-07 08:03:53编辑:auto阅读(3231)
python版本:3
访问页面:
import urllib.request
url="https://blog.csdn.net/qq_33160790"
req=urllib.request.Request(url)
resp=urllib.request.urlopen(req)
data=resp.read().decode('utf-8')
print(data)效果:
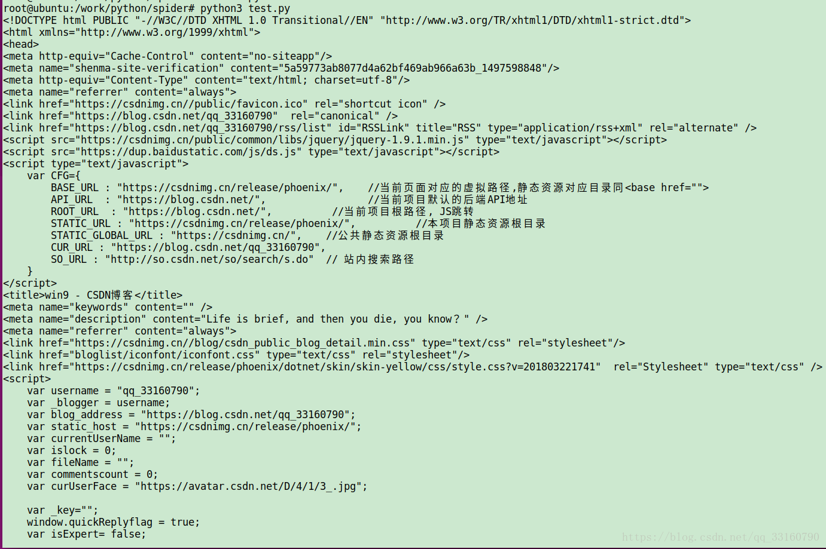
抓取csdn页面中文章的链接:
xpath语法可以看这篇文章:
http://www.w3school.com.cn/xpath/xpath_syntax.asp
from lxml import etree
import requests
url='https://blog.csdn.net/qq_33160790'
resp=requests.get(url)
if resp.status_code==requests.codes.ok:
html=etree.HTML(resp.text)
hrefs=html.xpath('////span[@class="link_title"]/a/@href')
for href in hrefs:
print href
效果:
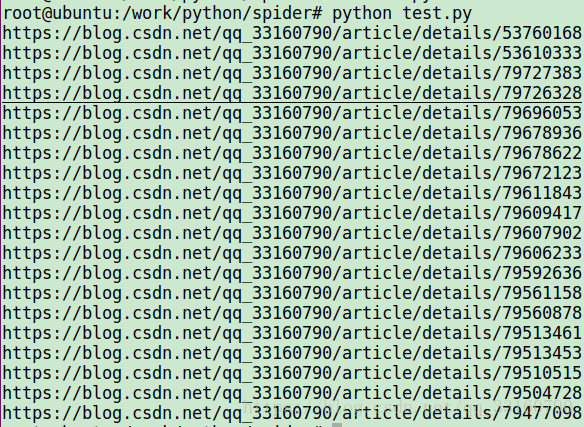
打印出所有文章url:
from lxml import etree
import requests
for i in range(1,23): #23 is equal to pagelist-1
#print(i)
url='https://blog.csdn.net/qq_33160790/article/list/'+str(i)
resp=requests.get(url)
if resp.status_code==requests.codes.ok:
html=etree.HTML(resp.text)
hrefs=html.xpath('////span[@class="link_title"]/a/@href')
for href in hrefs:
print href
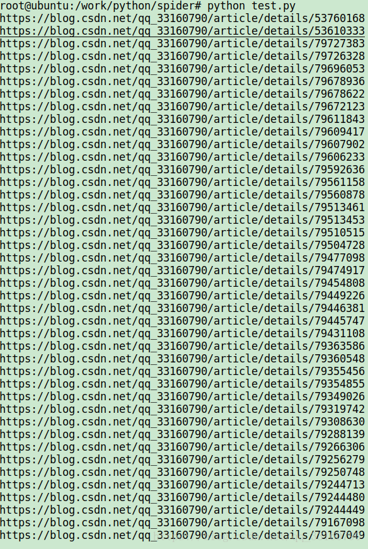
刷csdn点击脚本:
PS:url和23结合实际修改
from lxml import etree
import requests
import urllib.request
for i in range(1,23): #23 is equal to pagelist-1
#print(i)
url='https://blog.csdn.net/qq_33160790/article/list/'+str(i)
resp=requests.get(url)
if resp.status_code==requests.codes.ok:
html=etree.HTML(resp.text)
hrefs=html.xpath('////span[@class="link_title"]/a/@href')
for href in hrefs:
print (href)
req=urllib.request.Request(href)
data=urllib.request.urlopen(req).read()
上一篇: python中用logging实现日志滚
下一篇: Python 写的 Google Map
- H3C基本命令大全
53520
- H3C IRF原理及 配置
40348
- Python exit()函数
34749
- python全系列官方中文文档
30505
- python 获取网卡实时流量
25381
- 1.常用turtle功能函数
25180
- python 获取Linux和Windows硬件信息
23592
- 天天基金网数据接口
18860
- Selenium使用代理IP&无头模式访问网站
15171
- Selenium&Pytesseract模拟登录+验证码识别
14679
- LangGraph Studio可视化
1147°
- LangSmith开发-应用入门
1069°
- LangGraph开发-多轮对话问答机器人
1139°
- LangGraph开发-条件分支/循环图实战
1154°
- LangGraph开发-生态介绍,入门demo实战
1189°
- LangChain-接入12306-HTTP MCP智能体
1347°
- LangChain接入自定义爬虫-MCP工具
1307°
- LangChain接入Filesystem-MCP工具
1279°
- LangChain搭建MCP服务端和客户端流程
1379°
- LangGraph与MCP技术概述
1320°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
