python3 三种字符串(无前缀,前缀
发布时间:2019-09-06 08:52:55编辑:auto阅读(2439)
假设读者已经了解了什么叫字符集,什么叫编码,什么叫解码。
首先要明确,虽然有三种前缀(无前缀,前缀u,前缀b),但是字符串的类型只有两种(str,bytes),实验如下:

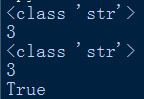
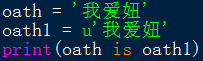
根据程序以及以上运行结果,发现无前缀,和前缀u,构造出来的字符串常量,是一样的。
类型一样是str,长度一样是3,==判断也是返回true。is判断也是返回true。
其实,这里是因为,python3中,字符串的存储方式都是以Unicode字符来存储的,所以前缀带不带u,其实都一样。
结论:字符串常量,前缀带不带u,都是一样的。
不管是utf-8,还是gbk,都可以理解为一种对应关系(若干个十六进制数<——>某个字符):
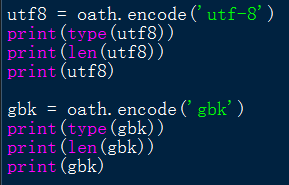
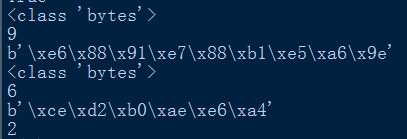
所以可以发现任何str类型的字符串,在经过encode('utf-8')后,就是通过utf-8这种编码解码方式(两种方向),将Unicode字符转换为对应的以字节方式存储的若干十六进制数。
根据如上程序以及结果,可以发现,utf-8用三个十六进制来表示一个中文字符,而gbk用二个十六进制来表示一个中文字符。
结论:encode()函数根据括号内的编码方式,把str类型的字符串转换为bytes字符串,字符对应的若干十六进制数,根据编码方式决定。
既然知道了,str实际存储的是Unicode字符,那么也可以Unicode编码来存储str,形如\u1234:
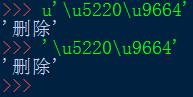 发现\u后面跟四个十六进制数,就可以代表一个Unicode字符,同样的,前缀带不带u都一样。
发现\u后面跟四个十六进制数,就可以代表一个Unicode字符,同样的,前缀带不带u都一样。
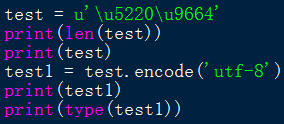
结论:str类型的字符串,每个字符用字符本身或者\u1234,来表示都可以,后者则是直接是Unicode编码。但打印时都是打印字符本身。
bytes字符串的组成形式,必须是十六进制数,或者ASCII字符:

提示错误:bytes只能包含ASCII字符。
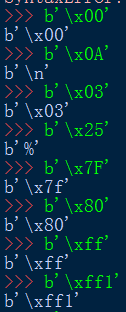 在打印bytes字符串时,某些正常字符和一些转义字符可以打印出来,比如:字母数字和‘\n’换行符。别的就只能以原来的方式存在。
在打印bytes字符串时,某些正常字符和一些转义字符可以打印出来,比如:字母数字和‘\n’换行符。别的就只能以原来的方式存在。

还可以对bytes取索引,所以这里bytes也可以用for循环来迭代了,因为也是可迭代对象。
取索引,将所在元素的数,转换为十进制数。
代码:
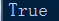
oath = '我爱妞'
print(type(oath))
print(len(oath))
oath1 = u'我爱妞'
print(type(oath1))
print(len(oath1))
print(oath==oath1)
utf8 = oath.encode('utf-8')
print(type(utf8))
print(len(utf8))
print(utf8)
gbk = oath.encode('gbk')
print(type(gbk))
print(len(gbk))
print(gbk)
out = open('test.txt','w',encoding = 'utf-8')
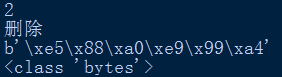
test = u'\u5220\u9664'
print(len(test))
print(test)
test1 = test.encode('utf-8')
print(test1)
print(type(test1))
out.write(test)
out.close()
上一篇: python: 自动去除空行
下一篇: zeromq+python安装手册
- H3C基本命令大全
53520
- H3C IRF原理及 配置
40348
- Python exit()函数
34749
- python全系列官方中文文档
30504
- python 获取网卡实时流量
25381
- 1.常用turtle功能函数
25179
- python 获取Linux和Windows硬件信息
23592
- 天天基金网数据接口
18860
- Selenium使用代理IP&无头模式访问网站
15171
- Selenium&Pytesseract模拟登录+验证码识别
14679
- LangGraph Studio可视化
1147°
- LangSmith开发-应用入门
1069°
- LangGraph开发-多轮对话问答机器人
1139°
- LangGraph开发-条件分支/循环图实战
1154°
- LangGraph开发-生态介绍,入门demo实战
1189°
- LangChain-接入12306-HTTP MCP智能体
1347°
- LangChain接入自定义爬虫-MCP工具
1307°
- LangChain接入Filesystem-MCP工具
1279°
- LangChain搭建MCP服务端和客户端流程
1379°
- LangGraph与MCP技术概述
1320°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
